11.2. 中文数据集¶
11.2.1. 数据集平台¶
千言数据集: https://www.luge.ai/#/
「千言」是由百度联合中国计算机学会、中国中文信息学会共同发起的面向自然语言处理的开源数据集项目,旨在推动中文信息处理技术的进步。
11.2.2. 著名数据集¶
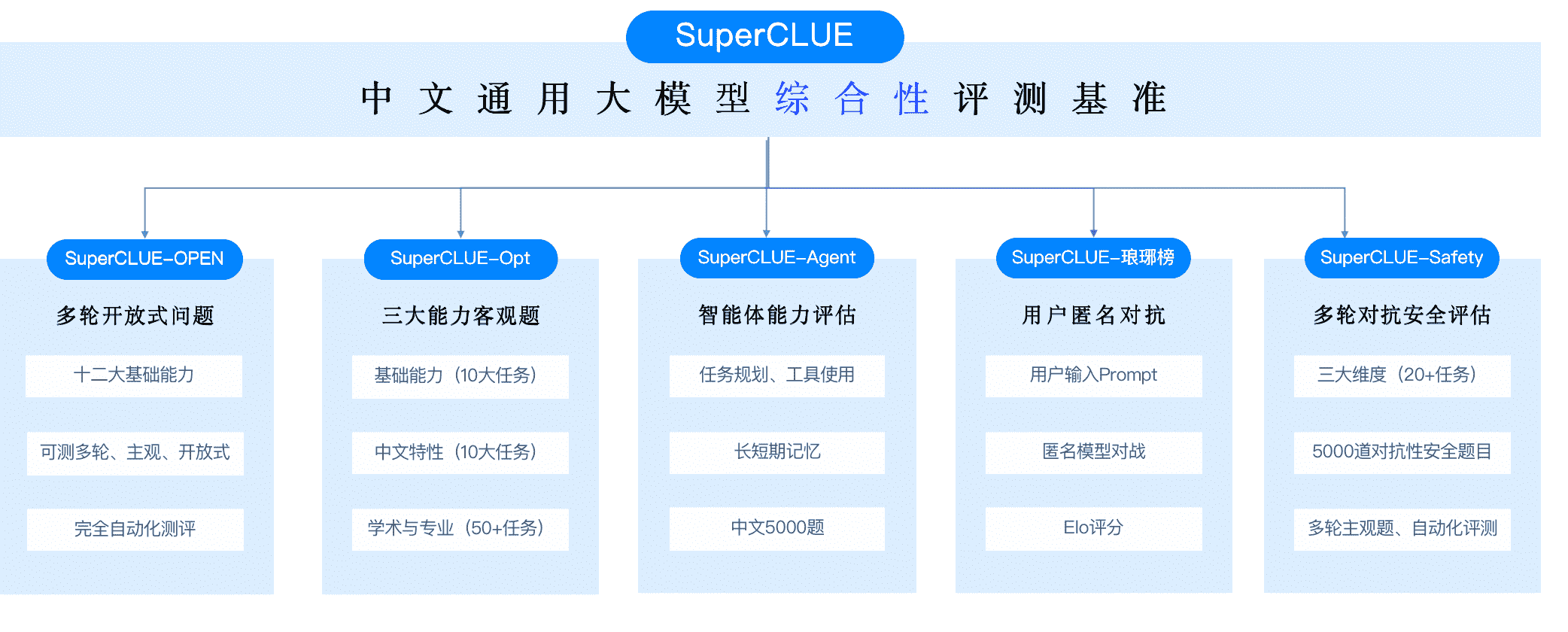
CLUE¶
CLUE: The Chinese Language Understanding Evaluation
中文语言理解测评基准 (CLUE): https://www.cluebenchmarks.com/
中文细粒度命名实体识别: https://github.com/CLUEbenchmark/CLUENER2020
DuIE2.0 数据集¶
DuIE2.0 中文关系抽取数据集: https://www.luge.ai/#/luge/dataDetail?id=5
业界规模最大的中文关系抽取数据集,考察 schema 约束下的关系抽取能力
MSRA_NER 数据集¶
11.2.3. NER类数据集¶
11.2.4. 其他¶
今日头条中文新闻(文本)分类数据集: https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset
常见的中文数据集:
1. CMRC
中文阅读理解数据集
Chinese Machine Reading Comprehension Dataset
https://github.com/ymcui/cmrc2018
from: 哈工大讯飞联合实验室
2. DRCD
台達閱讀理解資料集(通用領域繁體中文機器閱讀理解資料集)
Delta Reading Comprehension Dataset
https://github.com/DRCKnowledgeTeam/DRCD
3. CJRC
中文法律阅读理解数据集
Chinese judicial reading comprehension
数据集: https://hyper.ai/datasets/20004
论文: https://arxiv.org/abs/1912.09156
http://cail.cipsc.org.cn/
CAIL: Challenge of AI in Law(中国法律智能技术评测)
4. XNLI
跨语言自然语言推理数据集
Cross-lingual Natural Language Inference
数据集: https://github.com/facebookresearch/XNLI
https://github.com/google-research/bert/blob/master/multilingual.md
5. ChnSentiCorp
中文情感分析数据集
Chinese Sentiment Analysis Corpus
https://github.com/pengming617/bert_classification
6. LCQMC
中文问句相似度匹配数据集
Large-scale Chinese Question Matching Corpus
http://icrc.hitsz.edu.cn/info/1037/1146.htm
7. BQ Corpus
百度问答语料库
Baidu Question Corpus
http://icrc.hitsz.edu.cn/Article/show/175.html
8. THUCNews
清华大学中文新闻分类数据集
Tsinghua University Chinese News Classification Dataset
http://thuctc.thunlp.org/