5.2.5. 文本表示¶
独热(One-hot)表示法¶
假定所有的文字一共有 N 个单词(也可以是字符),我们可以将每个单词赋予一个单独的序号 id,那么对于任意一个单词,我们都可以采用一个 N 位的列表(向量)对其进行表示。在这个表示中,只需要将这个单词对应序号 id 的位置为 1,其他位置为 0 即可。
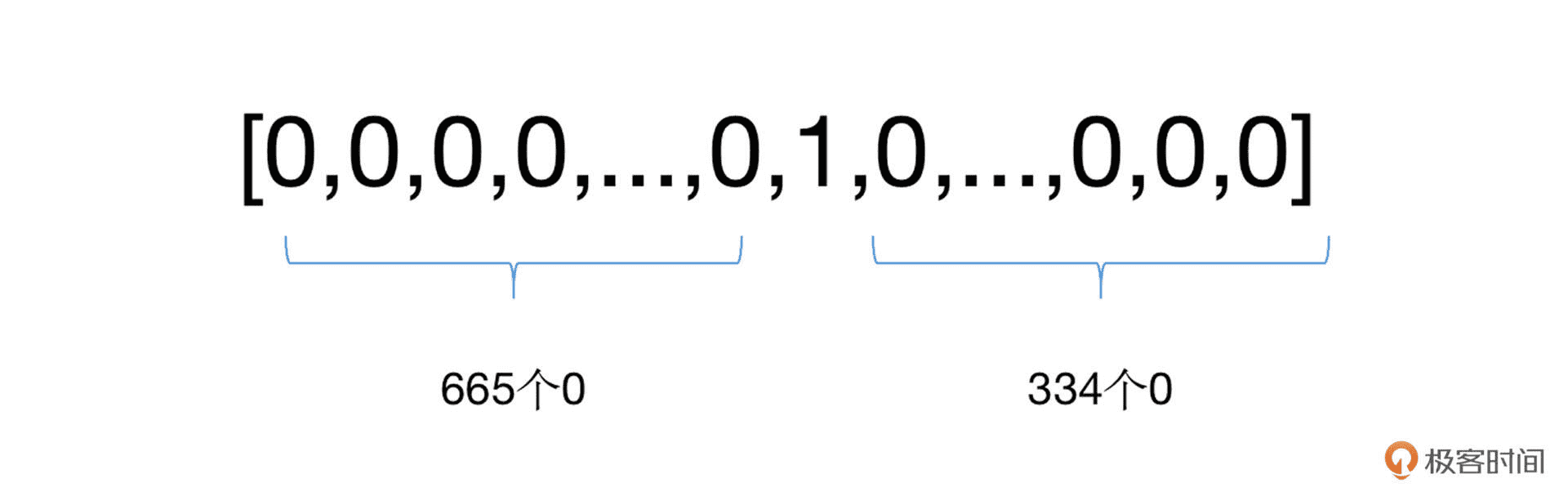
示例: 词典大小为 10000,“极客” 这个单词的序号 id 为 666,那么我们就需要建立一个 10000 长度的向量,并将其中的第 666 位置为 1,其余位为 0¶
在 UTF-8 编码中,中文字符有两万多个,词语数量更是天文数字,那么我们仅用字符的方式,每个字就需要两万多维度的数据来表示
如果有一篇一万字的文章,这个数据量就很可怕了
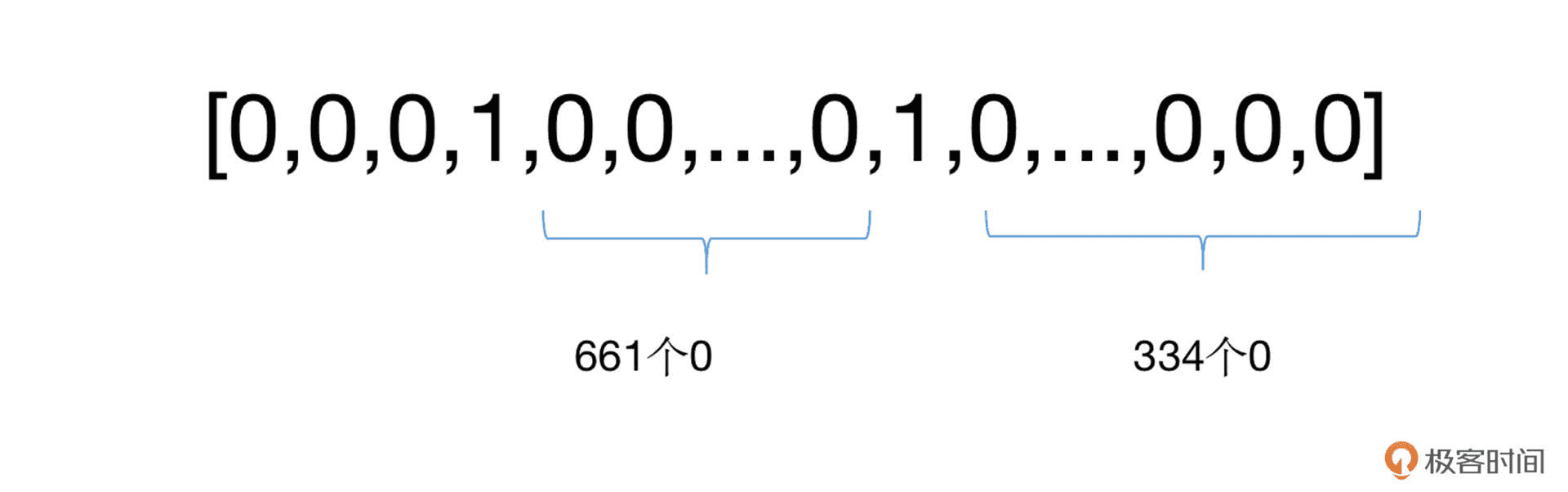
只使用一个向量表示文章中所有的单词,例如前面的例子,我们仍旧建立一个 10000 维的向量,把文章中出现过的所有单词的对应位置置为 1,其余为 0。¶
count-based 表示法¶
采用 v={index1: count1, index2: count2,…, index n: count n} 的形式,对每一个出现的单词的序号 id 以及出现过的次数进行统计,这样一来,“极客时间” 我们只需要两个 k-v 对的 dict 即可表示: {3:1, 665:1}
这种表示方法在 SVM、树模型等多个算法包中被广泛采用,因为客观来说,它确实能够大幅度地压缩空间的占用,生成起来也非常方便。
Word Embedding¶
前面这几种方法,不能表述单词的语序信息。
如:“我 / 喜欢 / 你” 和 “你 / 喜欢 / 我” 两个截然不同的意思,用前面的方法做分词的话,却会得到相同的表示结果。