5.2.7. 语言模型¶
语言模型是根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。
统计语言模型¶
可以使用概率统计的方法来建立一个语言模型,这种模型我们称之为统计语言模型。
统计语言模型的原理,简单来说就是计算一句话是自然语言(也就是一个正常句子)的概率。
统计语言模型示例讲解:
给定一个句子 S=w1,w2,w3,…,wn,
则生成该句子的概率为:p (S)=p (w1,w2,w3,w4,w5,…,wn),
再由链式法则我们可以继续得到:p (S)=p (w1) p (w2|w1) p (w3|w1,w2)…p (wn|w1,w2,…,wn-1)
那么这个 p (S) 就是我们所要的统计语言模型。
最为经典的就是基于马尔可夫假设 n-gram 语言模型,它也是被广泛采用的模型之一。
备注
但这样参数量真的实在是太大了,语料中数据存在稀疏的问题,基于此问题,我们假设:对于文本中的一个词,它出现的概率,很大程度上是由这个单词前面的一个或者几个单词决定的,这就是马尔可夫假设。
马尔可夫假设:
unigram(一元模型)
单词的出现仅由其本身决定的,与其他单词无关,就变成了最简单的形式:p (wn)
bigram
只由前面的一个单词决定,那它就是 p (wn|wn-1)
trigram
由前面两个单词决定,则变为 p (wn|wn-2,wn-1)
神经网络语言模型¶
ngram 模型一定程度上减少了参数的数量,但是如果 n 比较大,或者相关语料比较少的时候,数据稀疏问题仍然不能得到很好地解决。
如:把水浒传的文本放入模型中进行统计训练,最后却问模型林冲和潘金莲的关系,因为基于 ngram 的统计模型实在是收集不到两者共现的文本。
备注
从本质上说,神经网络语言模型也是通过 ngram 来进行语言的建模,但是神经网络的学习不是通过计数统计的方法,而是通过神经网络内部神经元针对数据不断更新。
神经网络语言模型具体是怎么做的呢?首先我们要定义一个向量空间,假定这个空间是一百维的,这就意味着,对于每个单词,我们可以用一个一百维的向量对其进行表示,比如 V (中国)=[0.2821289, 0.171265, 0.12378123,…,0.172364]。
这样,对于任意两个单词,我们可以用距离计算的方式来评价它们之间的联系。比如我们使用 cosin 距离计算 “中国” 和 “北京” 两个单词的距离,就大概率要比 “中国” 和 “西瓜” 的距离要近得多。
这样做有什么好处呢?首先,词与词之间的距离可以作为两个词之间相似性的度量。其次,向量空间隐含了很多的数学计算,比如经典的 V (国王)- V (皇后) = V (男人) - V (女人) ,这让词语之间有了更多的语义上的关联。
除了维度,为了确定向量空间,我们还需要确定这个空间有多少个 “点”,也就是词语的数量有多少。一般来说,我们是将语料库中出现超过一定阈值次数的单词保留,把这些留下来的单词的数量,作为空间点的量了。
具体看看实际的操作过程中是怎么做的:
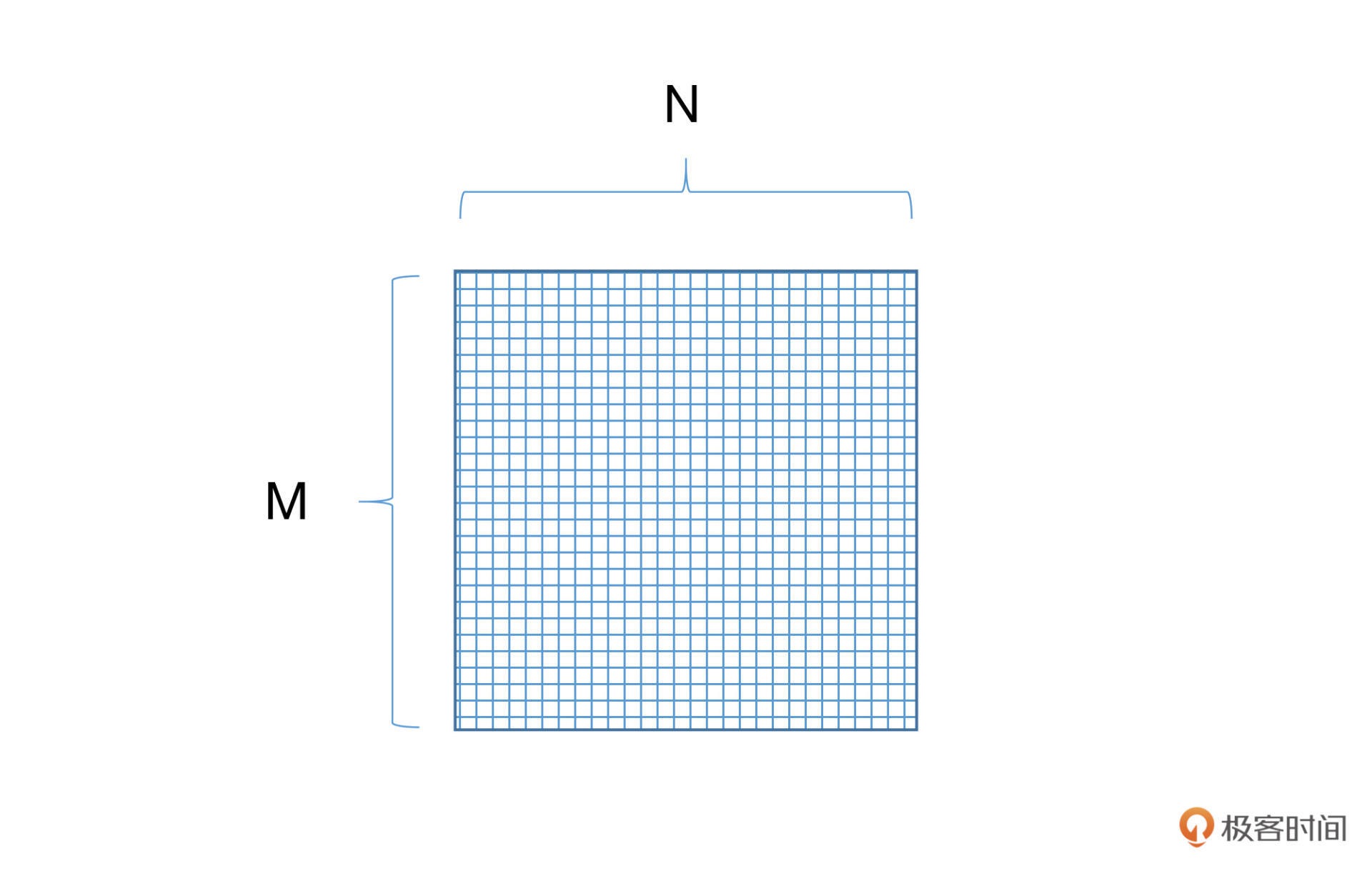
需要建立一个 M*N 大小的矩阵,并随机初始化里面的每一个数值,其中 M 表示的是词语的数量,N 表示词语的维度。我们把这样矩阵叫做词向量矩阵。¶
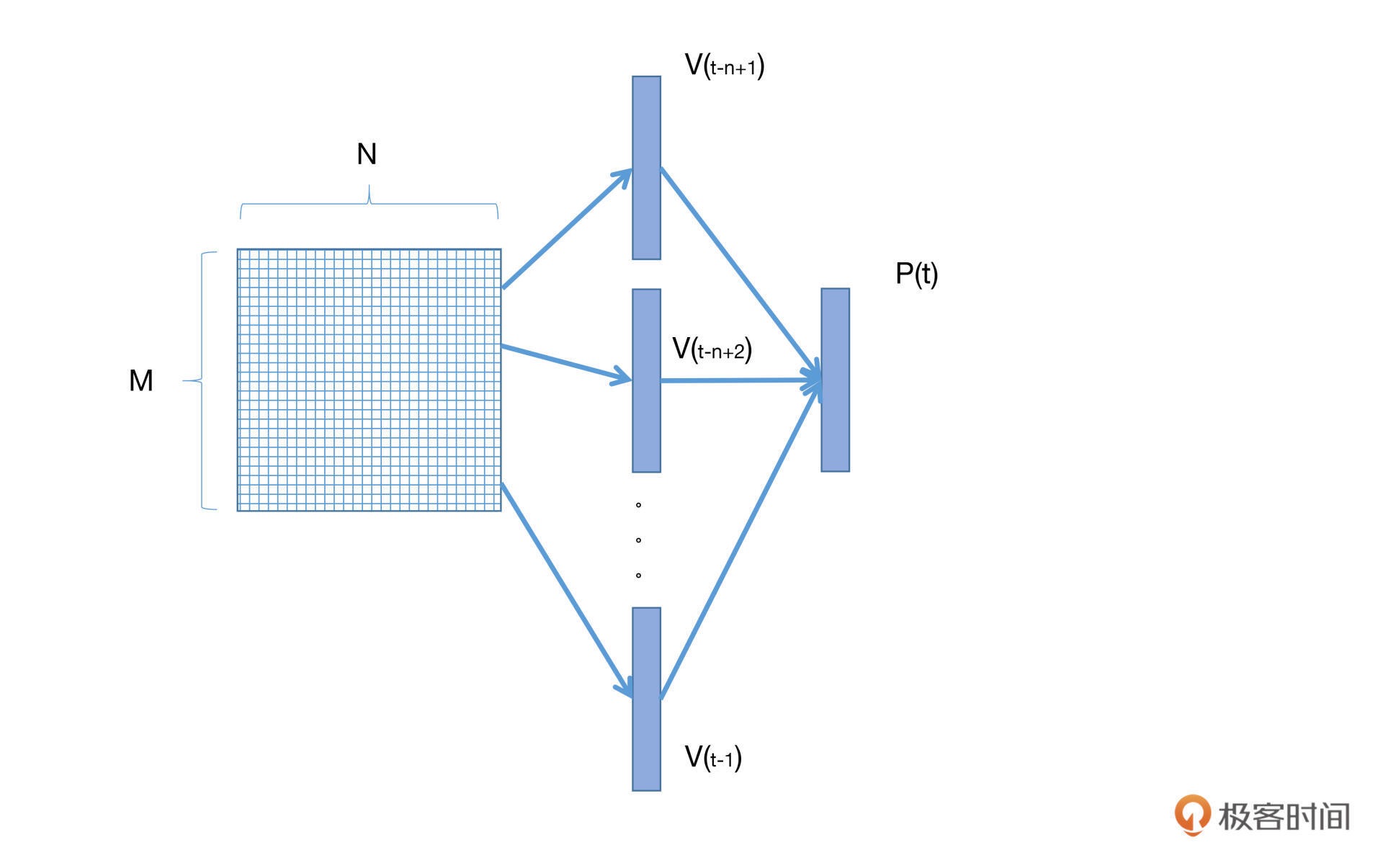
既然是随机初始化的,那么就意味着这个向量空间不能作为我们的语言模型使用。下面我们就要想办法让这个矩阵学到内容。¶
神经网络语言模型也是通过 ngram 来进行语言建模的。假定我们的 ngram 长度为 n,那么我们就从词向量矩阵中找到对应的前 n-1 个词的向量,经过若干层神经网络(包括激活函数),将这 n-1 个词的向量映射到对应的条件概率分布空间中。最后,模型就可以通过参数更新的方式,学习词向量的映射关系参数,以及上下文单词出现的条件概率参数了。
简单来说就是,我们使用 n-1 个词,预测第 n 个词,并利用预测出来的词向量跟真实的词向量做损失函数并更新,就可以不断更新词向量矩阵,从而获得一个语言模型。这种类型的神经网络语言模型我们称之为 前馈网络语言模型
总结¶
备注
统计语言模型和神经网络语言模型的区别。统计语言模型的本质是基于词与词共现频次的统计,而神经网络语言模型则是给每个词分别赋予了向量空间的位置作为表征,从而计算它们在高维连续空间中的依赖关系。相对来说,神经网络的表示以及非线性映射,更加适合对自然语言进行建模。
备注
通过语言模型,我们可以将语言文字变成可以计算的形式,让文字之间有了更为直接的关联。有了注意力机制,我们可以让模型了解到哪些是应该被更加关注的内容,从而提高语言模型的效果。