6.3.11. PEFT 0.13.0¶
GET STARTED¶
Quicktour¶
train with the Trainer class¶
TrainingArguments:
training_args = TrainingArguments(
output_dir="your-name/bigscience/mt0-large-lora",
learning_rate=1e-3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=2,
weight_decay=0.01,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
Trainer:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
Inference¶
load any PEFT-trained model for inference with the AutoPeftModel class:
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = model.to("cuda")
model.eval()
inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
"Preheat the oven to 350 degrees and place ........."
PEFT method guides¶
备注
本节内容,原始版本都有讲,只不过放在「TASK GUIDES」节,顺序有调整
IA3¶
IA3将模型的激活(自注意力和编码器-解码器注意力块中的键和值,以及位置前馈网络的中间激活)乘以三个学习向量
与引入权重矩阵而不是向量的 LoRA 相比,这种 PEFT 方法引入的可训练参数数量甚至更少
原始模型的参数保持冻结,仅更新这些向量。因此,对新的下游任务进行微调会更快、更便宜、更高效
示例:
from peft import IA3Config, get_peft_model
peft_config = IA3Config(task_type="SEQ_2_SEQ_LM")
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 282,624 || all params: 1,229,863,936 || trainable%: 0.022980103060766553"
Developer guides¶
Model merging¶
PEFT 提供了多种合并模型的方法,例如线性或 SVD 组合
两种通过消除冗余参数更有效地合并 LoRA 适配器的方法:
TIES - TrIm、Elect 和 Merge (TIES) 1. 首先,修剪冗余参数 2. 然后将冲突符号分解为聚合向量 3. 最后对符号与聚合符号相同的参数进行平均 此方法考虑到某些值(冗余和符号不一致)可能会降低合并模型的性能 DARE - Drop And REscale 一种可用于为 TIES 等其他模型合并方法做准备的方法 工作原理是根据丢弃率随机丢弃参数并重新调整剩余参数 这有助于减少多个模型之间冗余和潜在干扰参数的数量
Merge method¶
合并三个微调的 TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T 模型: tinyllama_lora_norobots 、 tinyllama_lora_sql 和 tinyllama_lora_adcopy:
from peft import PeftConfig, PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
config = PeftConfig.from_pretrained("smangrul/tinyllama_lora_norobots")
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, load_in_4bit=True, device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained("smangrul/tinyllama_lora_norobots")
model = PeftModel.from_pretrained(model, "smangrul/tinyllama_lora_norobots", adapter_name="norobots")
_ = model.load_adapter("smangrul/tinyllama_lora_sql", adapter_name="sql")
_ = model.load_adapter("smangrul/tinyllama_lora_adcopy", adapter_name="adcopy")
使用 add_weighted_adapter() 方法设置(TIES方法):
adapters = ["norobots", "adcopy", "sql"]
weights = [2.0, 1.0, 1.0]
adapter_name = "merge"
density = 0.2
model.add_weighted_adapter(adapters, weights, adapter_name, combination_type="ties", density=density)
使用 add_weighted_adapter() 方法设置2(DARE方法):
adapters = ["norobots", "adcopy", "sql"]
weights = [2.0, 0.3, 0.7]
adapter_name = "merge"
density = 0.2
model.add_weighted_adapter(adapters, weights, adapter_name, combination_type="dare_ties", density=density)
使用set_adapter()方法将新合并的模型设置为活动模型:
model.set_adapter("merge")
Merging (IA)³ Models¶
将三个 (IA)³ 适配器合并到 PEFT 模型中:
adapters = ["adapter1", "adapter2", "adapter3"]
weights = [0.4, 0.3, 0.3]
adapter_name = "merge"
model.add_weighted_adapter(adapters, weights, adapter_name)
将合并的模型设置为活动模型:
model.set_adapter("merge")
Quantization¶
量化相关基本参见:
transformer_4.45.2QLoRA 是一种将模型量化为 4 位,然后使用 LoRA 对其进行训练的方法。此方法允许您在单个 48GB GPU 上微调 65B 参数模型!
LoRA¶
Initialization¶
LoRA权重的初始化由LoraConfig中的参数init_lora_weights控制。
默认情况下,PEFT 使用权重 A 的 Kaiming-uniform 和权重 B 的零来初始化 LoRA 权重
1. PiSSA
2. OLoRA
3. LoftQ
4. Rank-stabilized LoRA
5. Weight-Decomposed Low-Rank Adaptation (DoRA)
6. QLoRA-style training
7. Memory efficient Layer Replication with LoRA
Optimizers¶
LoRA 训练可以使用 LoRA+ 进行优化,LoRA+ 对适配器矩阵 A 和 B 使用不同的学习率,可将微调速度提高 2 倍,性能提高 1-2%。
示例:
from peft import LoraConfig, get_peft_model from peft.optimizers import create_loraplus_optimizer from transformers import Trainer import bitsandbytes as bnb base_model = ... config = LoraConfig(...) model = get_peft_model(base_model, config) optimizer = create_loraplus_optimizer( model=model, optimizer_cls=bnb.optim.Adam8bit, lr=5e-5, loraplus_lr_ratio=16, ) scheduler = None ... trainer = Trainer( ..., optimizers=(optimizer, scheduler), )
Merge LoRA weights into the base model¶
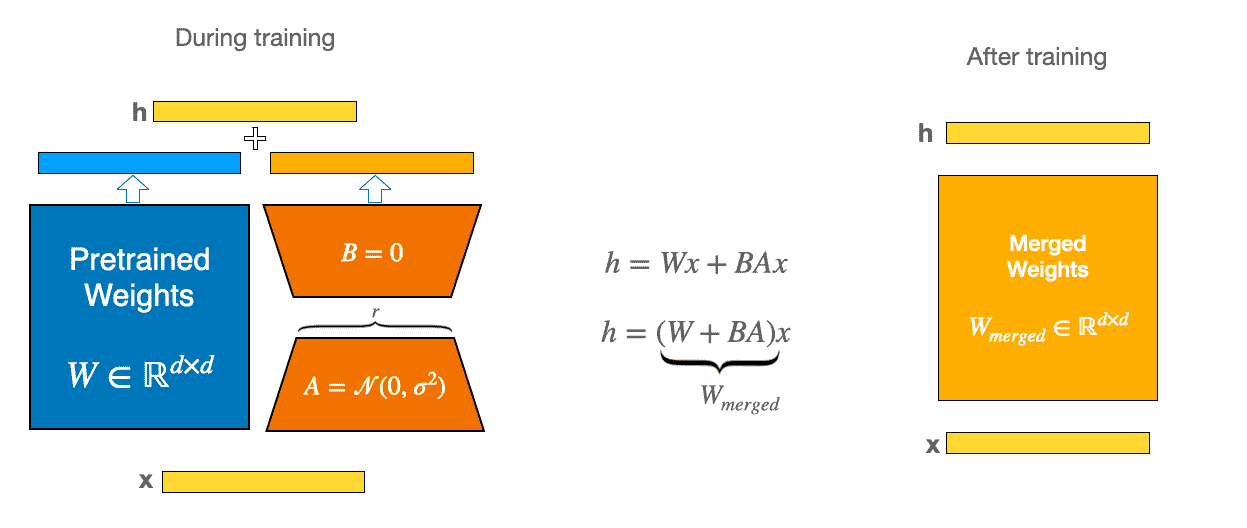
LoRA 适配器合并的示意图¶
how to run that using PEFT:
base_model = ...
from peft import PeftModel
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_and_unload()
keep a copy of the weights so you can unmerge the adapter later or delete and load different ones:
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_adapter()
# unmerge the LoRA layers from the base model
model.unmerge_adapter()
根据用户在weights参数中提供的权重方案将多个 LoRA 合并到新适配器中:
# 加载第一个适配器
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id, adapter_name="sft")
# 加载另一个适配器并将其与第一个适配器合并
weighted_adapter_name = "sft-dpo"
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
model.add_weighted_adapter(
adapters=["sft", "dpo"],
weights=[0.7, 0.3],
adapter_name=weighted_adapter_name,
combination_type="linear"
)
model.set_adapter(weighted_adapter_name)
Load adapters¶
使用load_adapter()将适配器加载到预训练模型上:
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
# load different adapter
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
# set adapter as active
model.set_adapter("dpo")
切回基本模型:
# unload adapter(卸载所有 LoRA 模块)
model.unload()
# delete adapter(完全删除适配器)
model.delete_adapter("dpo")
Inference with different LoRA adapters in the same batch¶
通常,每个推理批次必须在 PEFT 中使用相同的适配器。
可以使用adapter_name参数在同一批次中混合不同的LoRA适配器:
# load the LoRA adapter for French peft_model = PeftModel.from_pretrained(model, <path>, adapter_name="adapter_fr") # next, load the LoRA adapter for German peft_model.load_adapter(<path>, adapter_name="adapter_de")
可以使用adapter_names参数来指定每个样本使用哪个适配器:
inputs = tokenizer( [ "Hello, my dog is cute", # 英语 "Salut, mon chien est mignon", # 法语 "Hallo, mein Hund ist süß", # 德语 ], return_tensors="pt", padding=True, ) adapter_names = [ "__base__", "adapter_fr", "adapter_de", ] # 对每一个input指定adapter output = peft_model.generate(**inputs, adapter_names=adapter_names, max_new_tokens=20)
注意事项¶
Custom models¶
备注
一些微调技术(例如prompt tuning)特定于语言模型。这意味着在 🤗 PEFT 中,默认使用 🤗 Transformers 模型。然而,其他微调技术(例如LoRA )并不局限于特定的模型类型。
Multilayer perceptron¶
简单的多层感知器,具有输入层、隐藏层和输出层
from torch import nn
class MLP(nn.Module):
def __init__(self, num_units_hidden=2000):
super().__init__()
self.seq = nn.Sequential(
nn.Linear(20, num_units_hidden),
nn.ReLU(),
nn.Linear(num_units_hidden, num_units_hidden),
nn.ReLU(),
nn.Linear(num_units_hidden, 2),
nn.LogSoftmax(dim=-1),
)
def forward(self, X):
return self.seq(X)
备注
在此示例中,我们选择了大量的隐藏单元(num_units_hidden=2000)来突出 PEFT 的效率增益
在多层感知器中,需要我们作为用户来选择要调整的层:
# 打印所有的层
>>> print([(n, type(m)) for n, m in MLP().named_modules()])
[('', __main__.MLP),
('seq', torch.nn.modules.container.Sequential),
('seq.0', torch.nn.modules.linear.Linear),
('seq.1', torch.nn.modules.activation.ReLU),
('seq.2', torch.nn.modules.linear.Linear),
('seq.3', torch.nn.modules.activation.ReLU),
('seq.4', torch.nn.modules.linear.Linear),
('seq.5', torch.nn.modules.activation.LogSoftmax)]
# 示例:将 LoRA 应用于输入层和隐藏层,即'seq.0'和'seq.2',要在没有 LoRA 的情况下更新输出层,即'seq.4'
from peft import LoraConfig
config = LoraConfig(
target_modules=["seq.0", "seq.2"],
modules_to_save=["seq.4"],
)
创建 PEFT 模型并检查训练参数的比例:
from peft import get_peft_model
model = MLP()
peft_model = get_peft_model(model, config)
peft_model.print_trainable_parameters()
# prints trainable params: 56,164 || all params: 4,100,164 || trainable%: 1.369798866581922
Adapter injection¶
使用 PEFT,您可以将可训练适配器注入到任何torch模块中,这允许您使用适配器方法,而无需依赖 PEFT 中的建模类。目前,PEFT 支持将LoRA 、 AdaLoRA和IA3注入模型中,因为对于这些适配器,模型的就地修改足以对其进行微调。
缺点:一是需要手动编写 Hugging Face 中的from_pretrained和save_pretrained实用函数来保存和加载适配器;二是不适用于PeftModel提供的任何实用方法,例如禁用和合并适配器
优点:一是模型就地修改,保留所有原始属性和方法;二是适用于任何torch模块和模式
Creating a new PEFT model¶
要执行适配器注入,请使用inject_adapter_in_model()方法。此方法采用 3 个参数:PEFT 配置、模型和可选的适配器名称。如果您使用不同的适配器名称多次调用inject_adapter_in_model(),您还可以将多个适配器附加到模型。
将 LoRA 适配器注入到DummyModel模块的linear子模块:
.. code-block:: python
import torch from peft import inject_adapter_in_model, LoraConfig
- class DummyModel(torch.nn.Module):
- def __init__(self):
super().__init__() self.embedding = torch.nn.Embedding(10, 10) self.linear = torch.nn.Linear(10, 10) self.lm_head = torch.nn.Linear(10, 10)
- def forward(self, input_ids):
x = self.embedding(input_ids) x = self.linear(x) x = self.lm_head(x) return x
- lora_config = LoraConfig(
lora_alpha=16, lora_dropout=0.1, r=64, bias=”none”, target_modules=[“linear”], # 注入了这个modules )
model = DummyModel() model = inject_adapter_in_model(lora_config, model) # 使用inject_adapter_in_model注入(会生成随机参数的状态字典/权重)
dummy_inputs = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]]) dummy_outputs = model(dummy_inputs)
打印模型以查看适配器是否已正确注入:
# 注入前
DummyModel(
(embedding): Embedding(10, 10)
(linear): Linear(in_features=10, out_features=10, bias=True)
(lm_head): Linear(in_features=10, out_features=10, bias=True)
)
# 注入后
DummyModel(
(embedding): Embedding(10, 10)
(linear): Linear(
in_features=10, out_features=10, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=10, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=10, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(lm_head): Linear(in_features=10, out_features=10, bias=True)
)
Saving the model¶
使用 get_peft_model_state_dict 获取model适配层的具体权重:
from peft import get_peft_model_state_dict
peft_state_dict = get_peft_model_state_dict(model)
print(peft_state_dict)
Loading the model¶
使用 set_peft_model_state_dict 加载适配层的具体权重:
from peft import set_peft_model_state_dict
model = DummyModel()
model = inject_adapter_in_model(lora_config, model) # 会生成随机参数的状态字典/权重
outcome = set_peft_model_state_dict(model, peft_state_dict) # 指定使用保存的参数的状态字典/权重
# check that there were no wrong keys
print(outcome.unexpected_keys)
查看相关参数-fromGPT¶
查看适配器参数的初始状态和更新后的状态:
# 检查适配器参数的状态
print("Before set_peft_model_state_dict:")
for name, param in model.named_parameters():
if 'lora' in name: # 假设适配器层参数包含 'lora' 字段
print(f"{name} - Mean: {param.mean().item()}, Std: {param.std().item()}")
比较模型的输出变化:
# 使用相同的输入数据来比较输出
input_ids = torch.randint(0, 10, (1, 5))
output_before = model(input_ids)
print("Output before set_peft_model_state_dict:\n", output_before)
检查参数是否被加载(哈希值验证):
import hashlib
def get_params_hash(model):
params = torch.cat([p.flatten() for p in model.parameters() if 'lora' in p.name])
return hashlib.md5(params.detach().cpu().numpy().tobytes()).hexdigest()
# 计算适配器参数的哈希值
hash_before = get_params_hash(model)
print(f"Hash before: {hash_before}")
Mixed adapter types¶
通常,在🤗 PEFT 中混合不同类型的适配器是不可能的。您可以使用两个不同的 LoRA 适配器(可以有不同的配置选项)创建 PEFT 模型,但无法组合 LoRA 和 LoHa 适配器。然而,对于PeftMixedModel ,只要适配器类型兼容,这就可以工作。允许混合适配器类型的主要目的是组合经过训练的适配器进行推理。虽然可以训练混合适配器模型,但尚未经过测试,因此不建议这样做。
torch.compile¶
在 PEFT 中, torch.compile适用于某些功能,但不是所有功能。
它并不总是有效的原因是 PEFT 在某些地方是高度动态的(例如在多个适配器之间加载和切换),这可能会给torch.compile带来麻烦。
PEFT checkpoint format¶
PEFT files¶
When you call save_pretrained() on a PEFT model, the PEFT model saves three files:
1. adapter_model.safetensors or adapter_model.bin
默认情况下,模型以safetensors格式保存,这是bin格式的安全替代方案
bin格式已知容易受到安全漏洞的影响,因为它在底层使用了 pickle 实用程序
两种格式都存储相同的state_dict ,并且可以互换
2. adapter_config.json
包含适配器模块的配置,这是加载模型所必需的
包含:
存储的适配器模块类型, "peft_type": "IA3"
基础模型的信息,如 "base_model_name_or_path": "bert-base-uncased"
模型的修订版(如果有), "revision": null
3. README.md
IA³ 适配器的 adapter_config.json 示例:
{
"auto_mapping": {
"base_model_class": "BertModel",
"parent_library": "transformers.models.bert.modeling_bert"
},
"base_model_name_or_path": "bert-base-uncased",
"fan_in_fan_out": false,
"feedforward_modules": [
"output.dense"
],
"inference_mode": true,
"init_ia3_weights": true,
"modules_to_save": null,
"peft_type": "IA3",
"revision": null,
"target_modules": [
"key",
"value",
"output.dense"
],
"task_type": null
}
Convert to PEFT format¶
adapter_model:
1. 默认情况,对于 BERT 模型,LoRA 应用于注意力模块的query层和value层
这就是为什么您会在每层的键名称中看到attention.self.query和attention.self.value
2. LoRA 将权重分解为两个低秩矩阵: lora_A和lora_B
3. LoRA 矩阵被实现为nn.Linear层,因此参数存储在.weight属性中
4. 默认情况下,LoRA 不应用于 BERT 的嵌入层,因此没有lora_A_embedding和lora_B_embedding的条目
adapter_config.json 至少应包含以下条目:
{
"target_modules": ["query", "value"],
"peft_type": "LORA"
}
Accelerate integrations¶
DeepSpeed¶
DeepSpeed是一个专为具有数十亿参数的大型模型的分布式训练的速度和规模而设计的库。
其核心是零冗余优化器 (ZeRO),它将优化器状态 (ZeRO-1)、梯度 (ZeRO-2) 和参数 (ZeRO-3) 跨数据并行进程进行分片。
这大大减少了内存使用量,使您能够将训练扩展到十亿个参数模型。为了释放更高的内存效率,ZeRO-Offload 在优化过程中利用 CPU 资源来减少 GPU 计算和内存。
Fully Sharded Data Parallel¶
全分片数据并行(FSDP) 专为高达 1T 参数的大型预训练模型的分布式训练而开发。
FSDP 通过跨数据并行进程对模型参数、梯度和优化器状态进行分片来实现这一点,并且它还可以将分片的模型参数卸载到 CPU。
FSDP 提供的内存效率允许您将训练扩展到更大的批次或模型大小。
Conceptual guides¶
Adapters¶
基于适配器的方法在冻结预训练模型的注意力层(attention)和全连接层(fully-connected)之后添加额外的可训练参数,以减少内存使用并加快训练速度。
该方法因适配器而异,它可能只是一个额外的附加层,也可能将权重更新 ΔW 表示为权重矩阵的低秩分解。
无论哪种方式,适配器通常都很小,但表现出与完全微调的模型相当的性能,并且能够用更少的资源训练更大的模型。
Low-Rank Adaptation (LoRA)¶
备注
LoRA 是最流行的 PEFT 方法之一,如果您刚刚开始使用 PEFT,那么这是一个很好的起点。它最初是为大型语言模型开发的,但由于其效率和有效性,它是扩散模型的一种非常流行的训练方法。
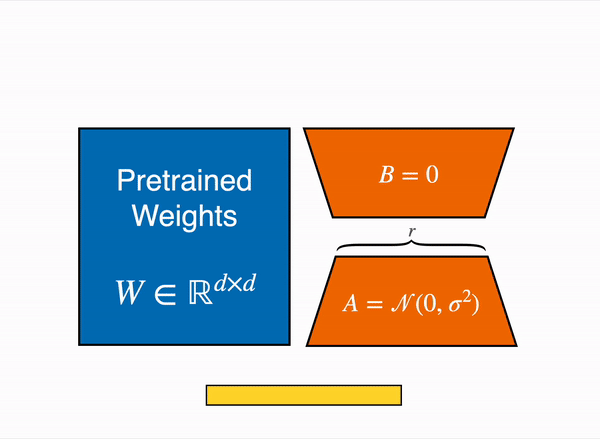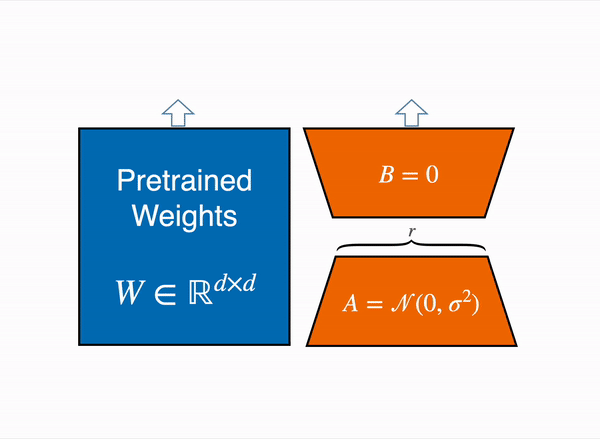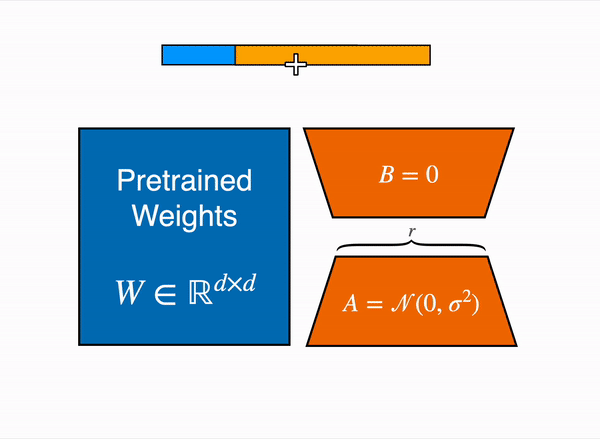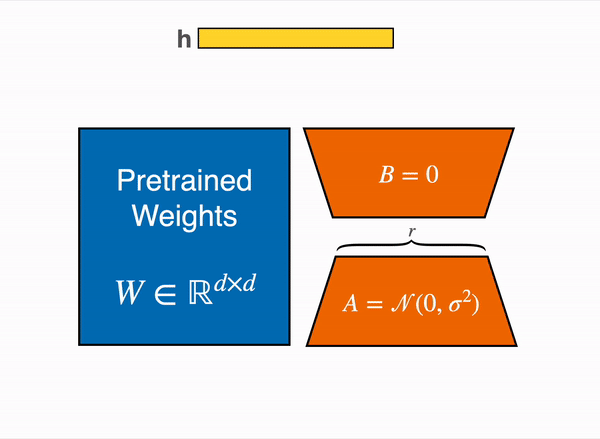
LoRA 通过低秩分解用两个较小的矩阵(称为更新矩阵)表示权重更新 ΔW。可以训练这些新矩阵以适应新数据,同时保持较低的参数总数。原始权重矩阵保持冻结状态,不会收到任何进一步的更新。为了产生最终结果,将原始权重和额外调整的权重相结合。您还可以将适配器权重与基本模型合并,以消除推理延迟。¶
优点:
1. LoRA 通过大幅减少可训练参数的数量来提高微调的效率。
2. 原始预训练权重保持冻结状态,这意味着您可以拥有多个轻量级便携式 LoRA 模型,用于在其之上构建的各种下游任务。
3. LoRA 与其他参数有效的方法正交,并且可以与其中许多方法组合。
4. 使用 LoRA 微调的模型的性能与完全微调的模型的性能相当。
Mixture of LoRA Experts (X-LoRA)¶
X-LoRA是 LoRA 的混合专家方法,它通过使用密集或稀疏门控来动态激活 LoRA 专家。
LoRA 专家以及基础模型在训练期间被冻结,导致参数数量较低,因为只有门控层必须进行训练。
特别是,门控层输出缩放(取决于配置)在层和令牌级别上是细粒度的。此外,在推理过程中,X-LoRA 动态激活 LoRA 适配器来回忆知识并有效地混合它们
对于每个步骤,X-LoRA 要求基本模型运行两次:
1. 首先,在没有任何 LoRA 适配器的情况下获取hidden states 2. 其次,用hidden states计算scalings(应用于 LoRA 适配器)并第二次运行模型。 第二次运行的输出是模型步骤的结果。
Low-Rank Hadamard Product (LoHa)¶
低秩分解会影响性能,因为权重更新仅限于低秩空间,这会限制模型的表达能力。
但是,您不一定要使用更大的Rank(秩),因为它会增加可训练参数的数量。
为了解决这个问题, LoHa (一种最初为计算机视觉开发的方法)被应用于扩散模型(diffusion models),其中生成不同图像的能力是一个重要的考虑因素。
LoHa 还应该适用于一般模型类型,但嵌入层目前尚未在 PEFT 中实现。
LoHa 使用Hadamard 乘积(逐元素乘积)而不是矩阵乘积。 ΔW 由四个较小的矩阵表示,而不是 LoRA 中的两个矩阵,并且每对这些低秩矩阵都与 Hadamard 乘积相结合。因此,ΔW 可以具有相同数量的可训练参数,但具有更高的秩和表达能力。
Low-Rank Kronecker Product (LoKr)¶
LoKr与 LoRA 和 LoHa 非常相似,它也主要应用于扩散模型(diffusion models),尽管您也可以将它与其他模型类型一起使用。
LoKr 将矩阵乘积替换为克罗内克乘积。
克罗内克乘积分解创建一个块矩阵,该矩阵保留原始权重矩阵的秩。克罗内克乘积的另一个好处是它可以通过堆叠矩阵列来矢量化。这可以加快该过程,因为您可以避免完全重建 ΔW。
Orthogonal Finetuning (OFT)¶
OFT是一种主要关注在微调模型中保留预训练模型的生成性能(generative performance)的方法。
它试图在一层中所有成对神经元之间保持相同的余弦相似性(超球面能量),因为这样可以更好地捕获神经元之间的语义信息。
这意味着OFT更能保存主题,并且更适合可控生成(类似于ControlNet )。
Orthogonal Butterfly (BOFT)¶
应该类似 OFT
Adaptive Low-Rank Adaptation (AdaLoRA)¶
AdaLoRA通过为更适合任务的重要权重矩阵分配更多参数(即更高的秩 r)并修剪不太重要的权重矩阵来管理从 LoRA 引入的参数预算。秩由类似于奇异值分解 (SVD, singular value decomposition) 的方法控制。
∆W 通过两个正交矩阵和一个包含奇异值的对角矩阵进行参数化。
这种参数化方法避免了迭代应用计算成本高昂的 SVD。
基于此方法,∆W 的秩根据重要性分数进行调整。
∆W 被分为三元组,每个三元组根据其对模型性能的贡献进行评分。重要性分数低的三元组被修剪,重要性分数高的三元组保留以进行微调。
Llama-Adapter¶
Llama-Adapter 是一种将 Llama 模型调整为能够理解和执行指令(instruction-following)的方法。
为了使模型能够适应这种“指令跟随”的任务,研究人员对 Llama-Adapter 进行了训练,使用的数据集包含 52,000 条指令及其相应的输出。
Soft prompts¶
参见前版本的 Conceptual guides -> Prompting
Multitask prompt tuning¶
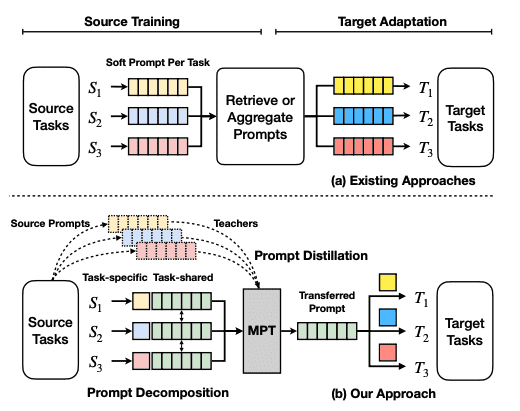
Multitask prompt tuning (MPT) 从多个任务类型的数据中学习单个提示,这些任务类型可以为不同的目标任务共享。其他现有方法为每个任务学习一个单独的软提示,需要检索或聚合这些提示以适应目标任务。
MPT由两个阶段组成:
1. source training 对于每个任务,其soft prompt被分解为特定于任务的向量。 将特定于任务的向量相乘以形成另一个矩阵W,并且在W和共享提示矩阵P之间使用Hadamard乘积来生成特定于任务的提示矩阵。 特定于任务的提示被提炼成在所有任务之间共享的单个提示矩阵。该提示是通过多任务训练进行训练的。 2. target adaptation 为了适应目标任务的单个提示,目标提示被初始化并表示为共享提示矩阵和特定于任务的低秩提示矩阵的Hadamard乘积。
IA3¶
一种参数高效的微调技术,旨在改进LoRA 。
为了使微调更加有效,IA3(通过抑制和放大内部激活的注入式适配器Infused Adapter by Inhibiting and Amplifying Inner Activations)使用学习向量(learned vectors)重新调整内部激活。
这些学习到的向量被注入到典型的基于变压器的架构中的注意力和前馈模块(attention and feedforward modules)中。
这些学习到的向量是微调期间唯一可训练的参数,因此原始权重保持冻结。
处理学习向量(与学习 LoRA 等权重矩阵的低秩更新相反)可以使可训练参数的数量少得多。
优点¶
IA3 通过大幅减少可训练参数的数量,使微调更加高效。 (对于 T0,IA3 模型只有大约 0.01% 可训练参数,而即使 LoRA 也有 > 0.1%)
原始的预训练权重保持冻结状态,这意味着您可以拥有多个轻量级便携式 IA3 模型,用于在其之上构建的各种下游任务。
使用 IA3 微调的模型的性能与完全微调的模型的性能相当。
IA3 不会增加任何推理延迟,因为适配器权重可以与基本模型合并。
备注
上述优点与 LoRA 类似
原则上,IA3 可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。根据作者的实现,IA3 权重被添加到 Transformer 模型的键、值和前馈层(key, value and feedforward layers)。具体来说,对于 Transformer 模型,IA3 权重被添加到键层和值层(key and value layers)的输出以及每个 Transformer 块中第二前馈层的输入。
给定注入 IA3 参数的目标层,可训练参数的数量可以根据权重矩阵的大小确定。
Common IA3 parameters in PEFT¶
target_modules
应用 IA3 向量的模块(例如,注意力块, attention blocks)
feedforward_modules
在target_modules中被视为前馈层的模块列表
虽然学习向量(learned vectors)与注意力块的输出激活(output activation for attention blocks)相乘,但向量与经典前馈层的输入相乘
请注意, feedforward_modules必须是target_modules的子集
modules_to_save
除了 IA3 层之外的模块列表,要设置为可训练并保存在最终检查点中。这些通常包括模型的自定义头,该头是为微调任务随机初始化的
参考¶
实践: notebook collection: https://huggingface.co/spaces/PEFT/causal-language-modeling