2.11. RAG¶
知识图谱:基本主语-宾语-谓语关系
属性图:为节点和边添加详细属性
GraphRAG:将图形结构与检索增强生成相结合
2.11.1. 简介¶
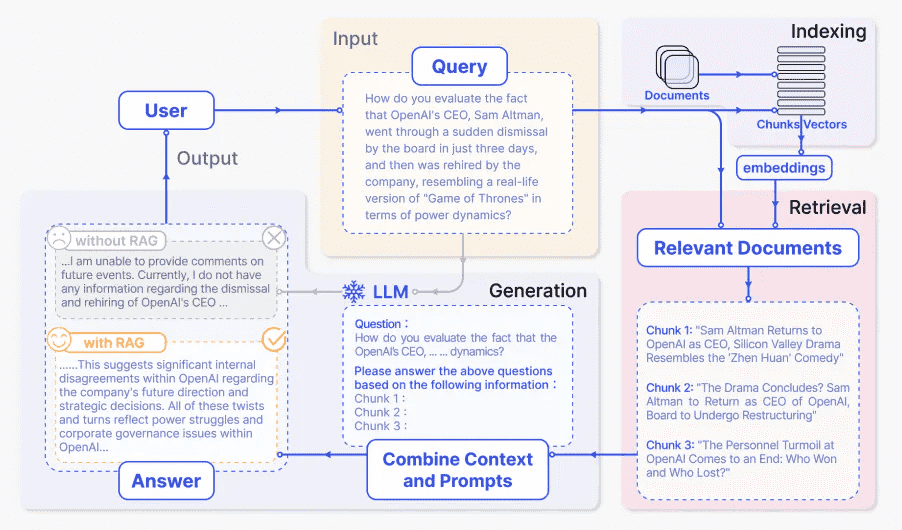
RAG的工作流程包括三个阶段:检索(Retrieval)、扩充(Augmentation)和生成(Generation)。
检索阶段是根据用户查询的向量找到最相似的文档片段;
扩充阶段通过额外的指令、规则和安全措施来丰富这些文档片段(如使用prompt engineering)
生成阶段则是基于扩充后的上下文生成对用户查询的回复(使用genAI)
RAG 变体(GraphRAG、Adaptive RAG、Corrective RAG、Agentic RAG),目的是改进 “传统 “RAG 管道的一些弱点。
2.11.2. 知识图谱KG¶
Knowledge Graphs
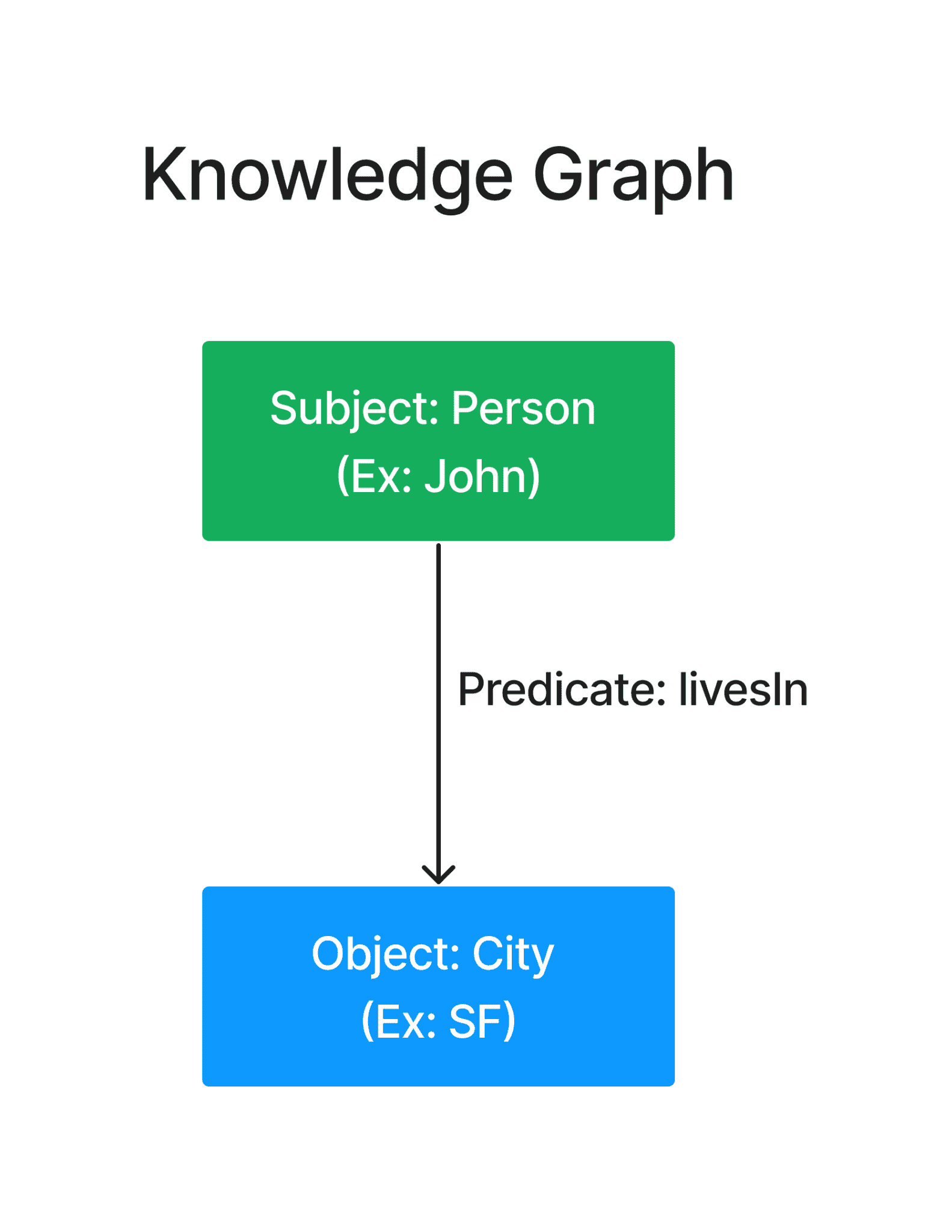
知识图谱的核心是使用由主语、宾语和谓语组成的三元组结构来定义关系。将 KG 想象成一个基本的家谱。它显示了谁与谁有亲戚关系,但并没有告诉您有关每个人的太多信息。¶
2.11.3. 属性图谱PG¶
Property Graphs
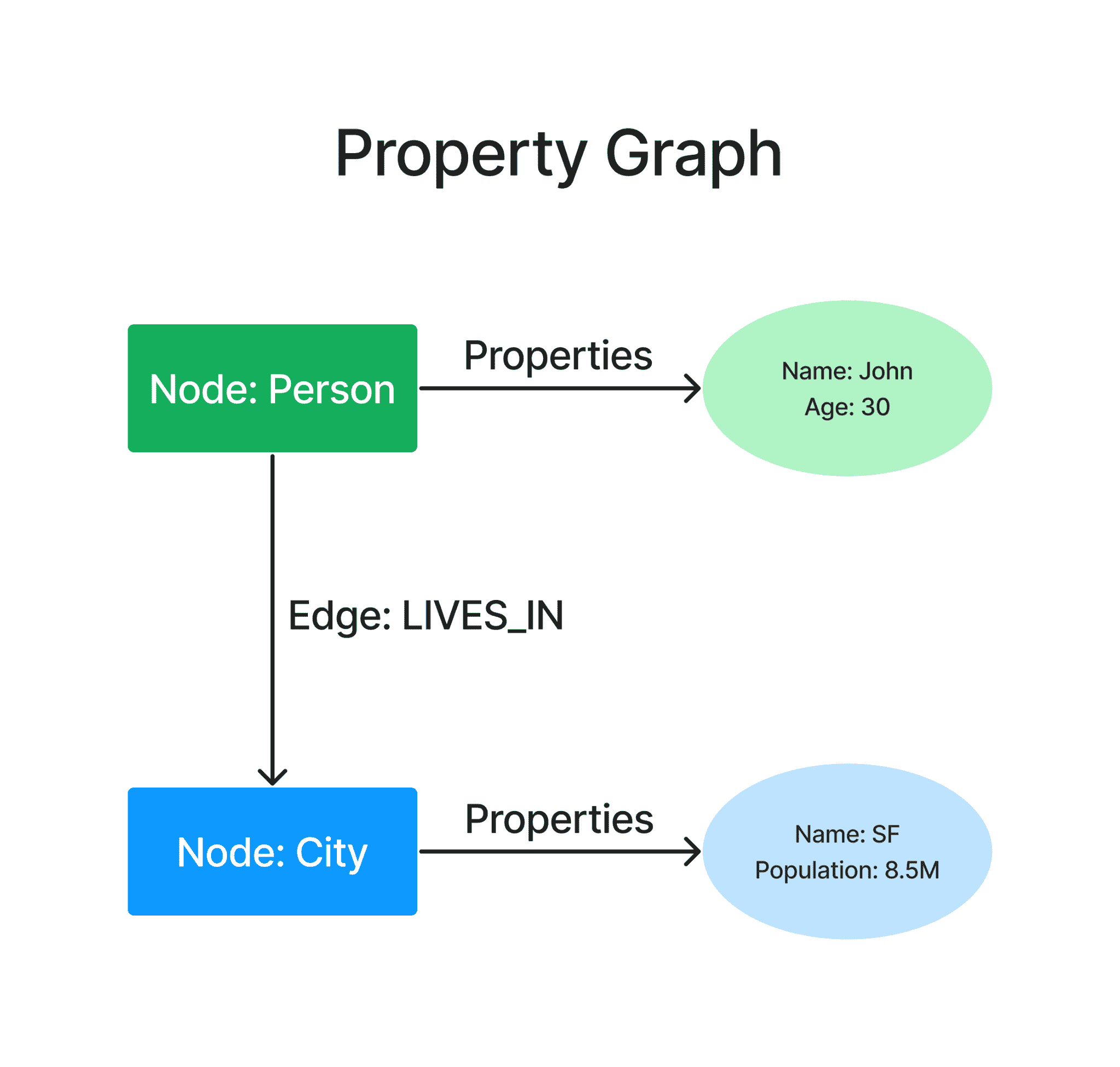
PG 结构不仅包含主语、宾语和谓语,还包含附加到每个实体的属性,例如名称/值对,即升级的家谱。这就像从姓名标签到每个家庭成员的详细资料。¶
2.11.4. RAG¶
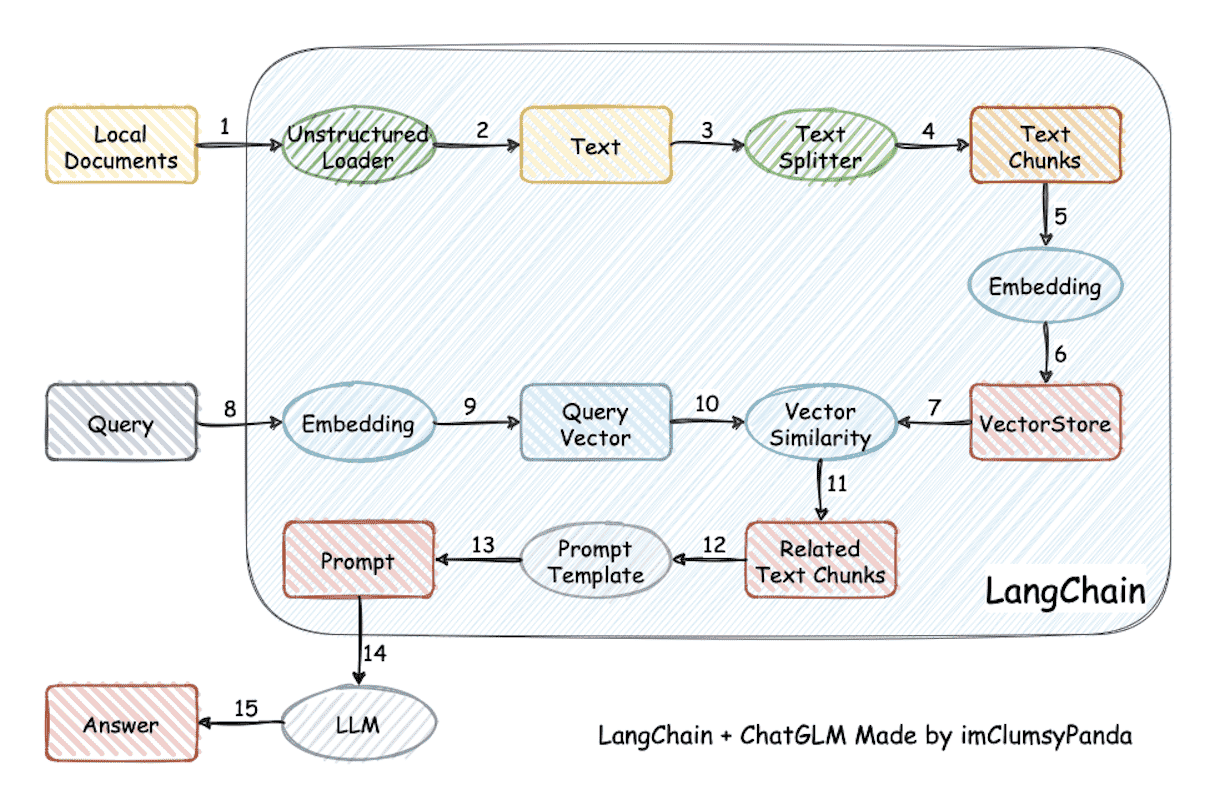
RAG index 和 search的主要流程¶
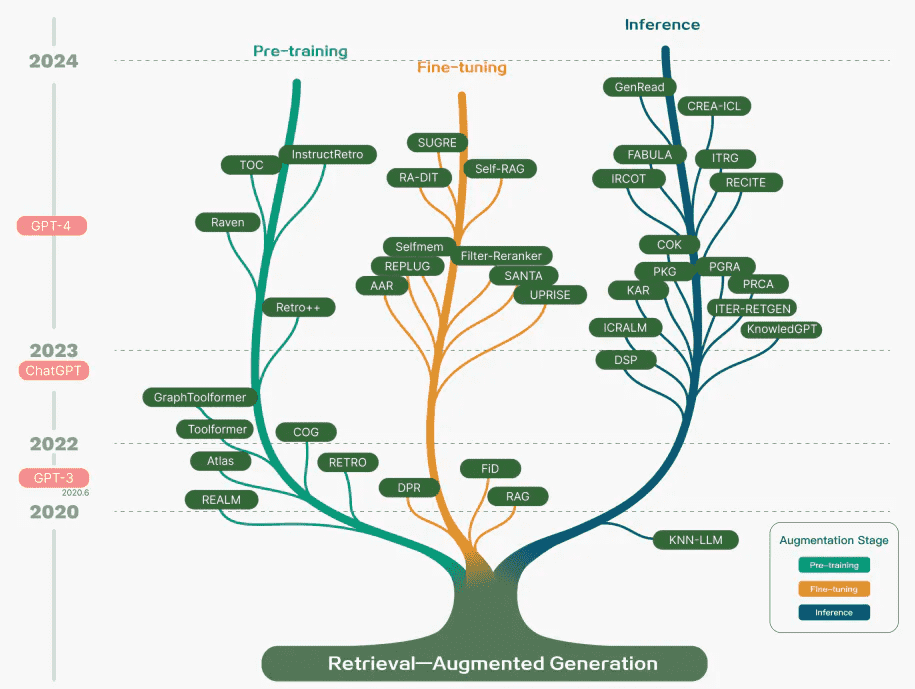
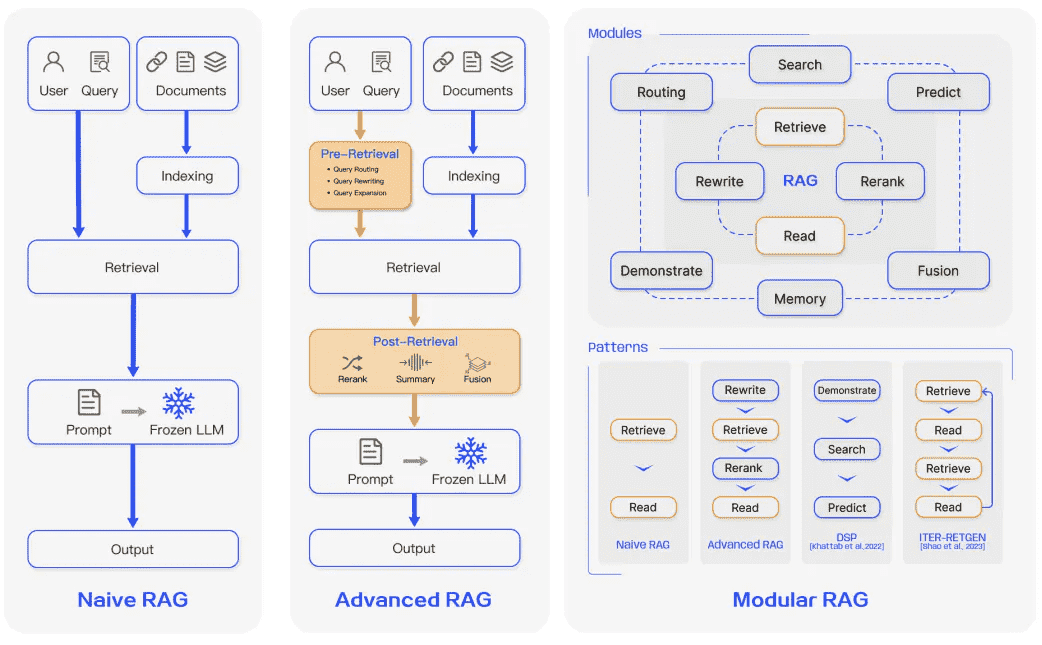
RAG 系统已经从简单的 RAG 发展到高级 RAG 和模块化 RAG。这种演变是为了解决性能、成本和效率方面的某些限制。图片来源 这儿3 .¶
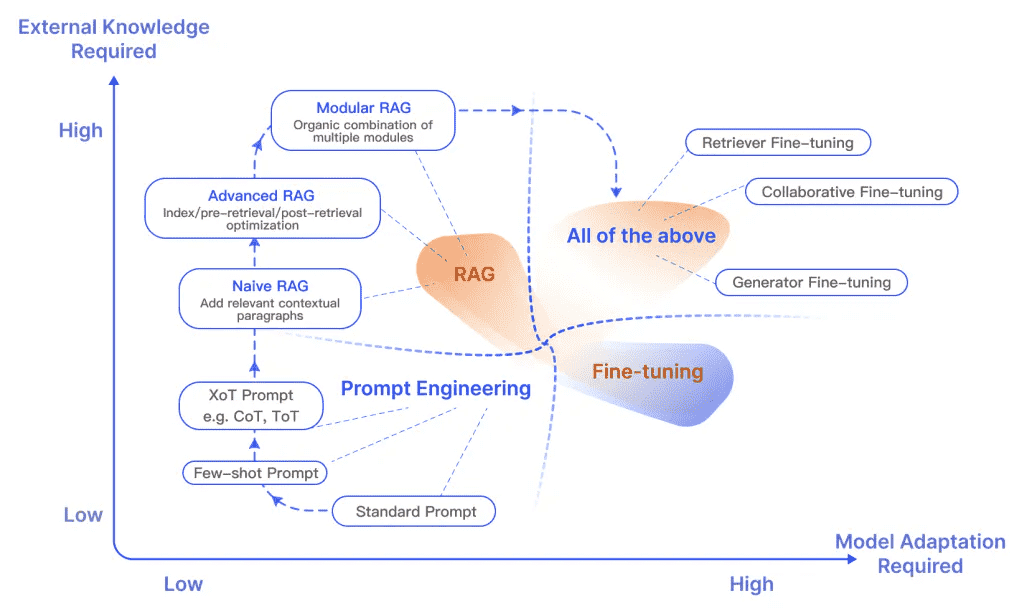
RAG 与其他模型优化方法相比的不同特性¶
2.11.5. GraphRAG¶
GraphRAG (Graphs + Retrieval Augmented Generation)
结合了检索增强生成(RAG)和查询聚焦摘要(QFS)的优势,可以有效处理大型文本数据集上的复杂查询。虽然 RAG 擅长获取精确信息,但它在处理需要主题理解的更广泛查询时遇到了困难,QFS 解决了这一挑战,但无法很好地扩展。 GraphRAG 集成了这些方法,可在广泛、多样化的文本语料库中提供响应式且全面的查询功能。
GraphRAG 擅长以查询为中心的总结,解决了传统 RAG 系统在处理复杂开放式问题方面的局限性。
一般流程:
1. Extracting a Knowledge Graph:
从原始文本中创建一个 "知识图谱"。
知识图谱就像一个由相互连接的想法组成的网络,其中每个想法(或 "节点")都以有意义的方式与其他想法相连。
2. Building a Community Hierarchy
将这些相关联的想法组织成小组或 "社区"。将这些社区视为相关概念的集群。
3. Generating Summaries
对于每个社区,GraphRAG 都会生成能抓住要点的摘要。
这有助于理解关键观点,而不会迷失在细节中。
4. Leveraging the Structures
当您需要执行涉及检索和生成信息的任务(基于 RAG 的任务)时,GraphRAG 会使用这种组织良好的结构。
这使得整个过程更加高效和准确。
Performance Improvements:
Complex Information Traversal:
擅长将不同的信息连接起来,以提供新的、综合的见解
Holistic Understanding:
能更好地理解和总结大型数据集,提供更全面的信息
The GraphRAG Process:
Indexing Phase
TextUnits Creation
将输入文本分割成称为 TextUnits 的较小单元。这些单元可作为分析的基本构件,并在输出中提供详细参考。
Entity Extraction
使用 LLM 从 TextUnits 中提取所有实体(如人、地点、组织)、关系和关键主张。
Hierarchical Clustering
使用莱顿技术对图形进行分层聚类。
可视化表示法中的每个圆圈都是一个实体,大小表示实体的重要性(程度),颜色表示实体的群落。
Community Summarization
自下而上生成每个社区及其组成部分的摘要。这有助于全面了解数据集。
Query Phase
Global Search
使用社区摘要来推理涉及整个语料库的广泛而全面的问题
Local Search
专注于特定实体,将搜索范围扩大到其邻近实体和相关概念,以进行更详细的推理
2.11.6. Adaptive RAG¶
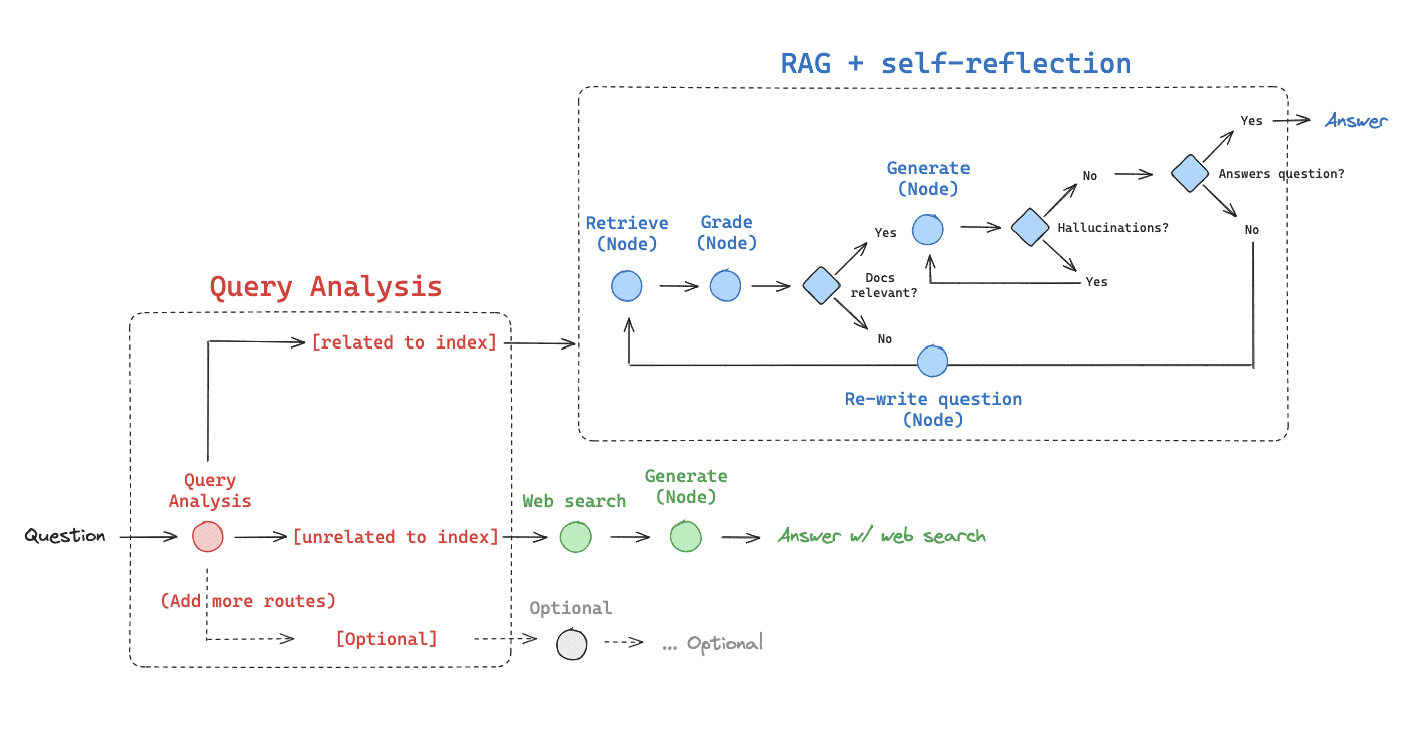
Adaptive RAG is a strategy for RAG that unites (1) query analysis with (2) active / self-corrective RAG.
自适应 RAG 是一种 RAG 策略,它将
(1) 查询分析与(2) 主动/自我纠正 RAG结合在一起。
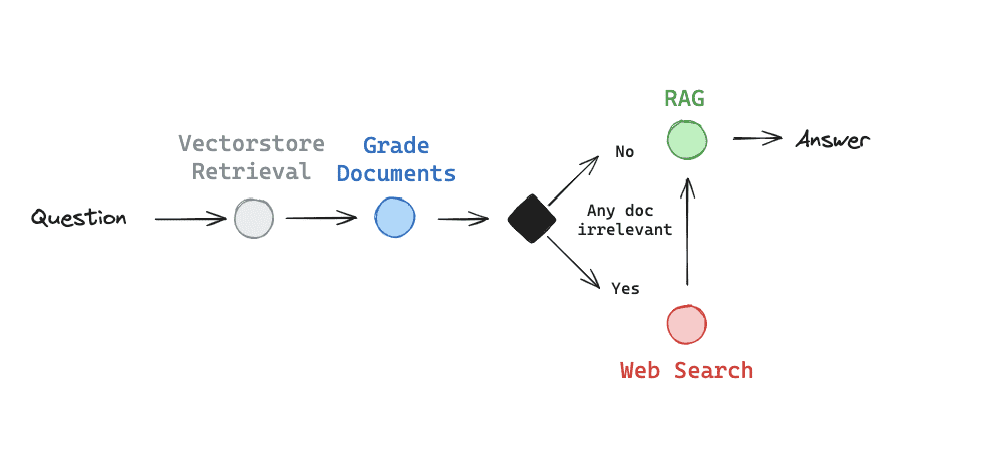
2.11.7. Corrective RAG¶
Corrective-RAG (CRAG) 是 RAG 的一种策略,它结合了对检索到的文档的自我反思/自我评分。
一般流程:
1. 至少有一个文档超过了相关性阈值,则继续进行生成
2. 如果所有文档都低于相关性阈值,或者评分者不确定,则使用 Web 搜索来补充检索
3. 在生成之前,它对搜索或检索到的文档进行知识提炼
4. 将文档划分为知识条
5. 对每个条带进行分级,并过滤掉不相关的条带
2.11.8. 参考¶
From Knowledge Graphs to GraphRAG: Advanced Intelligent Data Retrieval: https://div.beehiiv.com/p/knowledge-graphs-graphrag-advanced-intelligent-data-retrieval
Property Graphs: https://docs.google.com/presentation/d/15qKwdOVoobnIuGDVN0qNl7hDO3nPwLAdETpCoBAKqfQ/
Knowledge Graph + RAG > Naive RAG: https://div.beehiiv.com/p/knowledge-graph-rag-naive-rag
Introducing Agent-based RAG: https://readmedium.com/zh/introducing-agent-based-rag-9b7141ae1cd7
Adaptive RAG 自适应 RAG: https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/