5.2.6. 注意力机制¶
对于一个由 n 个单词组成的句子来说,不同位置的单词,重要性是不一样的。因此,我们需要让模型 “注意” 到那些相对更加重要的单词,这种方式我们称之为注意力机制,也称作 Attention 机制。
关于注意力机制最经典的论文就是大名鼎鼎的《Attention Is All You Need》
Attention 机制要做的事:找到最重要的关键内容。它对网络中的输入(或者中间层)的不同位置,给予了不同的注意力或者权重,然后再通过学习,网络就可以逐渐知道哪些是重点,哪些是可以舍弃的内容了。
在前面的神经网络语言模型中,对于一个确定的单词,它的向量是固定的,但是现在不一样了,因为 Attention 机制,对于同一个单词,在不同语境下它的向量表达是不一样的。
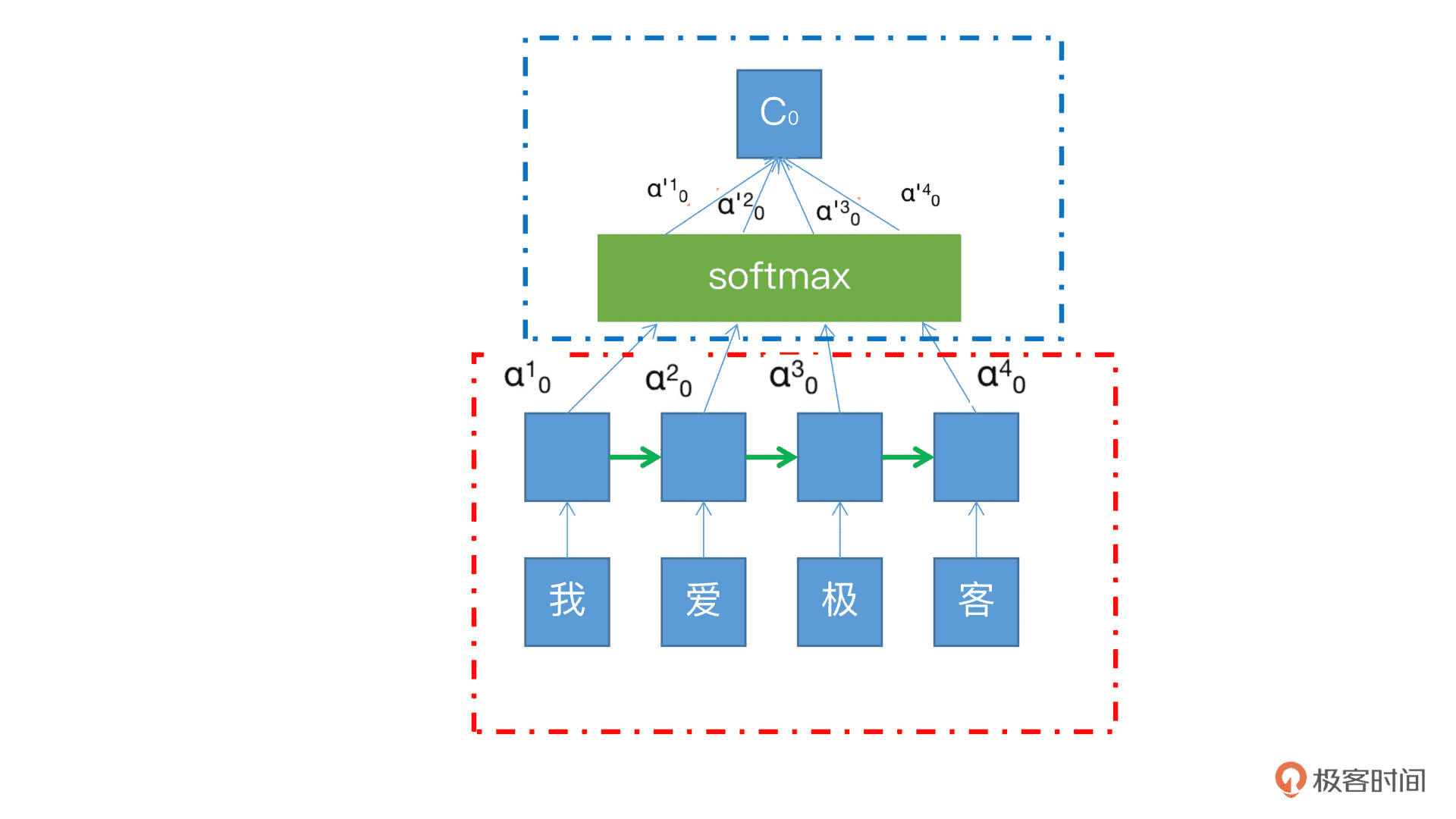
这张图是 Attention 机制和 RNN 结合的例子。其中红色框中的是 RNN 的展开模式,我们可以看到,我 / 爱 / 极 / 客四个字的向量沿着绿色箭头的方向传递,每个字从 RNN 节点出来之后都会有一个隐藏状态 h,也就是输入节点上面的蓝色方框,在这个过程中每个状态的权重是一样的,不分大小。而蓝色框就是 Attention 机制所加入的部分,其中的每个 α 就是每个状态 h 的权重,有了这个权重,就可以将所有的状态 h,加权汇总到 softmax 中,然后求和得到最终输出 C。这个 C 就可以为后续的 RNN 判断权重,提供更多的计算依据。¶
备注
注意力机制的原理其实很简单,但是也很巧妙。只需要增加很少的参数,就可以让模型自己弄清楚谁重要谁次要。
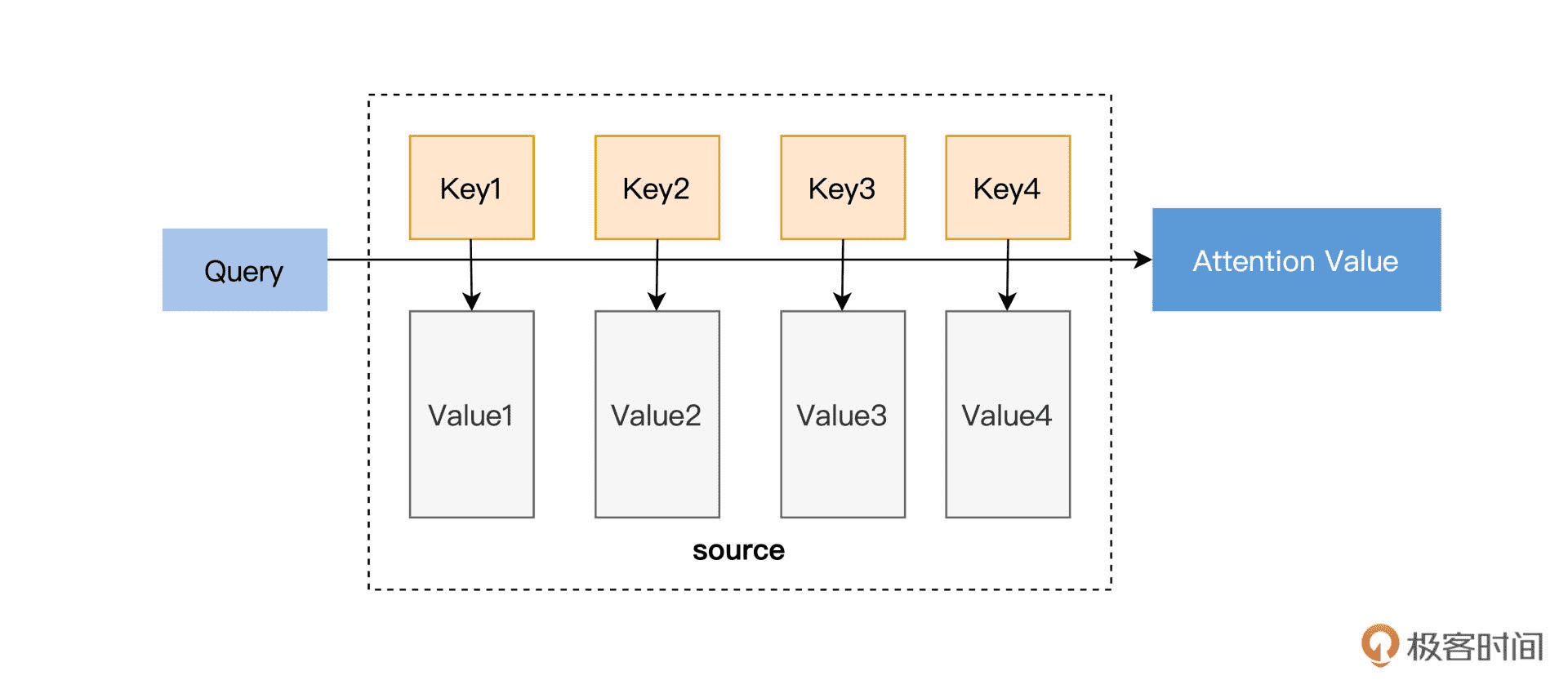
在这里输入是 query (Q), key (K), value (V),输出是 attention value。跟刚才 Attention 与 RNN 结合的图类比,query 就是上一个时间节点传递进来的状态 Zt-1,而这个 Zt-1 就是上一个时间节点输出的编码。key 就是各个隐藏状态 h,value 也是隐藏状态 h(h1, h2…hn)。模型通过 Q 和 K 的匹配公式计算出权重,再同 V 结合就可以得到输出¶
这就相当于计算得到了当前的输出和所有输入的匹配度,公式如下:
Attention(Q,K,V)=softmax(sim(Q,K))V
Attention 目前主要有两种,一种是 soft attention,一种是 hard attention。hard attention 关注的是当前词附近很小的一个区域,而 soft attention 则是关注了更大更广的范围,也更为常用。