3.4.3. Prompt Engineering¶
简单示例:
Chain of Thought
Let’s Think step by step
Self-Consistency
Few-shot + {question} 用几个相似的具有推导步骤的例子
Auto-CoT
Few-shot + {question} +Chain of Thought相似的具有推导步骤的例子+{问题}+给出具体思考过程。
Generation Knowledge
以事实+知识的方式组织样例,再最后提问,要求给出解释和答案
Automatic Prompt Engineer
Let's work this out in a step by step way to be sure we have the right answer
OPRO
“Take a deep breath and think step by step.”
Optimization by PROmpting (OPRO)总体架构:最开始输入meta-prompt,这个初始的meta-prompt基本上只是对优化任务进行了描述(也会有few-shot example)。
输入后LLM便会生成一个solution,这个solution由objective function评估并打分。
(solution, score)组合成一对添加到meta-prompt中,如此完成一个循环。
多次循环后取分数最高的solution作为优化结果。
meta-prompt分为两部分,问题描述和优化轨迹,问题描述就是用自然语言描述想要优化的问题,比如“generate a new instruction that achieves a higher accuracy”。
而优化轨迹(Optimization trajectory)则是指之前提到的(solution, score)对,即之前生成的解决方案和对应的分数,可以看作优化的“日志”。
但是要注意这个轨迹不是按时间顺序排的,而是按照打分升序排的。
因为之前的研究也发现,越靠后的样例对输出的影响越大,所以把分数高的排在后面有利于LLM向其学习。
Tree of Thought
f“给定当前的推理状态:‘{state_text}’,生成{k}条连贯的思想来实现推理过程:”
f“鉴于当前的推理状态:‘{state_text}’,根据其实现 {initial_prompt} 的潜力悲观地将其值评估为 0 到 1 之间的浮点数”
利用树的遍历算法(BFS, DFS, MC,BF,A*),搜索最佳答案。
Graph of Thought
出发点:人类的思维在解决问题时,不是只会链式思维或者尝试不同的链(TOT),而是在脑中构建一个复杂的思维网络。
人类在思考时会沿着一个链式的推理,回溯,再尝试一个新的方向,并把之前的链的优点保留,缺点剔除,与当前探索的链的方向结合生成一个新的解决方案
创新点是将大模型生成的信息建模为一个图,节点是 “LLM的思想“,边是这些思想的依赖关系。
这种方法能够将任意 LLM 思想,组合,提取出这个网络的思想本质。
Chain of Verification
鼓励 LLM 在产生 response 之前生成内部思想的推理链,或者通过 self-critique 等技术来更新它们的初始 response.
包含四个步骤:
1. Generate Baseline Response:给定一个 query,使用 LLM 生成一个 response。
2. Plan Verifications:基于原始的 query 和上一轮得到的原始 response,让 LLM 生成一个 verification question 列表,并用于帮助 LLM 进行自我分析。
3. Execute Verifications:依次回答每个 verification question,从而对照原始 response 检查是否存在不一致或错误。
4. Generate Final Verified Response:考虑前面步骤的结果,完成最终的修正后的 response。
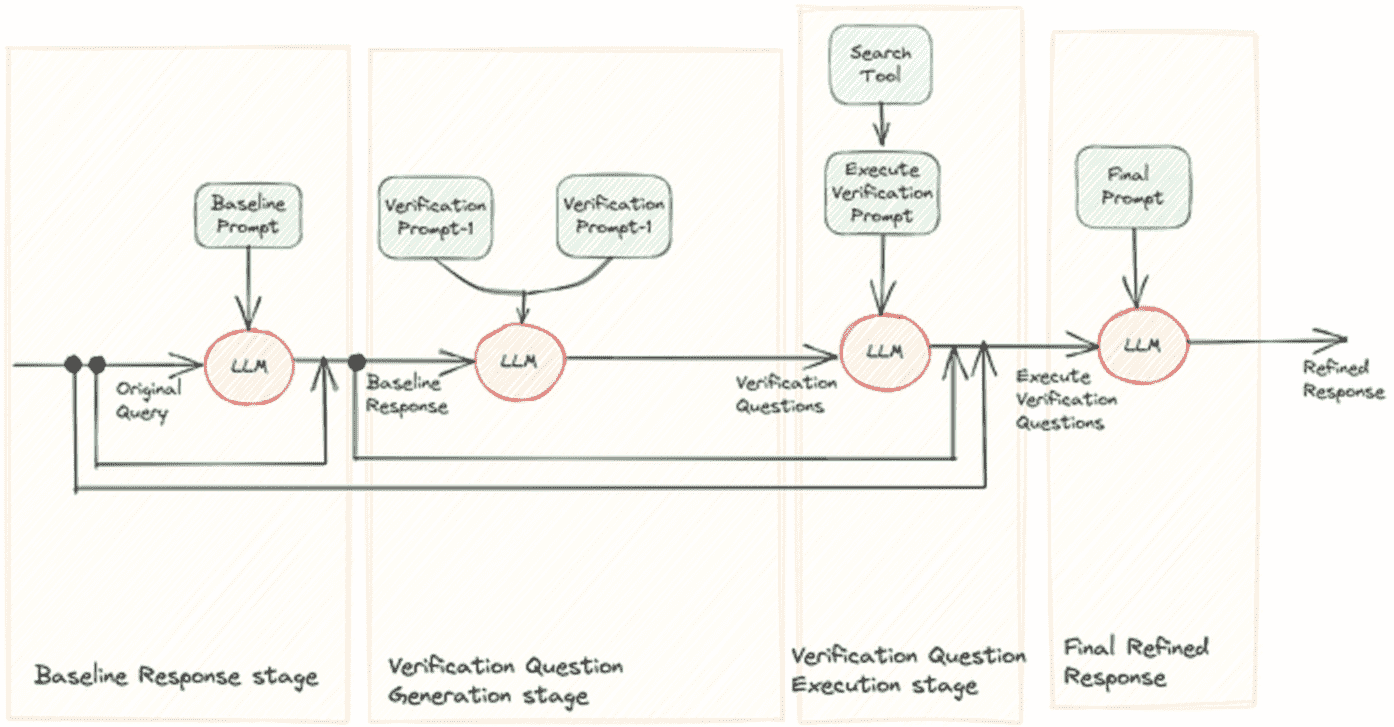
Chain of Verification¶
MedPrompt
出发点:通过更加精巧的Prompt技术来解锁大模型的能力以获得近似微调的效果。
这个Prompt方法实际上是一种结合了训练数据的few-shot方法。
简单来说,在prompt中加入few-shot案例,可以大幅提高模型的性能。
但是传统技术上都是直接使用固定的few-shot案例,这显然是低效的。
解决的办法是让模型自动搜索领域知识,然后生成few-shot样例再为用户提供答案。
具体来说,就是为GPT-4准备垂直(医学)领域的预训练数据,在GPT-4回答用户领域问题之前,先通过检索的方法从训练数据中找到近似的问答结果,然后构造few-shot案例,嵌入用户的输入中,再让模型回答问题。
方法:主要包含三个步骤:
1. dynamic few-shot,
2. self-generated chain of thought,
3. choice shuffling ensemble。
动态少样本选择是根据query样本选择k个训练样本,使其与测试样本语义最相似,构成少样本展示。
自生成思维链就是结合前面的动态选择训练数据,使用GPT-4来自主生成每道题目的详细思维展示,作为Prompt(提示)给GPT-4使用,这样在动态few-shot选择的时候可以获得更加高质量的prompt模板。
选项洗牌集成主要解决大模型生成不稳定的问题,核心在于通过改变问题中的选项顺序,然后观察模型对不同顺序下选择的一致性,以此来减少模型对某些选项的偏好。
集成部分主要是指将模型在不同选项顺序情况下生成的多个答案进行汇总和分析。
LLMLingua(提示压缩): https://rv3gbat836y.feishu.cn/docx/Hs3SdfOmAoCwO7x73XlcqiURnuE
出发点:
1. 自然语言本质上是冗余的,并且 LLM 可以有效地从被压缩文本中还原源文本。
2. 类似于Selective-Context 方法,首先使用小型语言模型计算原始提示中每个词汇单元(如句子、短语或 token)的自身信息,然后删除较少信息的内容来压缩提示。
然而,它不仅忽视了被压缩内容之间的相互依赖关系,还忽略了目标 LLM 与用于提示压缩的较小语言模型之间的对应关系。
3. 困惑度被用作衡量提示信息复杂度的标准。较低困惑度的 token 在语言模型的预测中贡献的不确定性较小,因此可能被认为是相对冗余的信息,在压缩中被删除也不太影响语义信息。
LLMLingua 框架旨在通过更精细地控制压缩过程,确保在减小提示长度的同时有效保留原始提示信息。组件:
1. 压缩比例控制器:其主要作用是动态地为提示中的不同部分分配不同的压缩比例,同时在高度压缩的情况下保持语义的完整性。
第一点是,给示例动态分配更小的压缩比例(即保留比例越小),给指令和问题更大的压缩比例,以更好地实现信息保留。
第二点是引入了句子级的丢弃,特别是在存在多个冗余示例的情况下,还可以执行示例级的控制,以满足压缩的需求。
2. 迭代提示:在压缩提示的过程中迭代处理每个 token,更细粒度地压缩提示内容,以更准确地保留关键的上下文信息。包括提示分段、计算困惑度、迭代压缩、概率估计与过滤等步骤。
3. 对齐方法:用于解决小型语言模型与黑盒大型语言模型之间存在的概率分布差距。
包括对小LM模型的微调、用小LM进行概率分布估计、基于生成的分布进行对齐处理,使小型 LM 生成的提示分布更加接近 LLM 的提示分布三步。
CogTree: https://rv3gbat836y.feishu.cn/docx/Y81RdflPxoCZlXxDtBoceJw1nZb
思路:
面向轻量化大模型的复杂任务推理,使用较小规模的模型(7B),构建双系统生成推理树。
基于人类的认知理论,通过两个系统来模仿人类产生认知的过程。
直觉系统(Generation)利用上下文将复杂的问题分解为子问题,并生成对查询的响应。
反思系统(Scores)评估直觉系统产生的结果,并选择最有可能的解决方案,为下一轮提供指导。
反思系统采用两种方法来验证结果:中间过程的验证和整个推理链的验证。
具体实现是:采用基于提示的方法并将其视为分类问题,模型输出三个类别之一:确定、不可能或可能
训练:
直觉系统的目标是生成答案,使用监督微调 SFT 精调模型,直觉系统通过利用上下文示例将查询(即复杂问题)分解为子问题。
在自回归期间,只对生成的文本计算损失。反思系统的目标是打分。
由于人类的决策行为源于对各种选择的比较分析,因此采用对比学习方法来增强模型区分不同状态的能力,即最大化正样本和负样本在样本空间中的距离来学习正样本和负样本的表示。
对比学习中负采样也非常重要,需要生成更具挑战的负样本。