7.1.2. Hugging Face Hub¶
Hugging Face Hub 是一个拥有超过 120k 模型、20k 数据集和 50k 演示应用程序 (Spaces) 的平台
Repositories¶
Models, Spaces, and Datasets are hosted on the Hugging Face Hub as Git repositories, which means that version control and collaboration are core elements of the Hub.
Cloning repositories 克隆存储库:
git clone https://huggingface.co/<your-username>/<your-model-name>
git clone git@hf.co:<your-username>/<your-model-name>
Models¶
常见的机器学习文档工具包括:
- 模型卡(Model Cards):自动生成描述模型性能、用途、局限性等信息的标准文档。
- 数据表(Data Sheets):自动生成数据集的元数据、组成、收集方法等信息的标准文档。
- 报告生成器(Reporting):根据模型试验结果自动生成试验报告。
- 文档extractors:从代码注释、函数签名等自动提取文档。
- 可视化工具(Visualization):通过关系图、流程图等可视化展示系统结构。
- 笔记本工具(Notebooks):像Jupyter等笔记本可以嵌入文档、代码、结果展示。
Integrated Libraries¶
HuggingFace Supported Libraries:
+----------------------------+---------------+---------+-------------------+-------------+
| Library | Inference API | Widgets | Download from Hub | Push to Hub |
+============================+===============+=========+===================+=============+
| 🤗 Transformers | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| 🤗 Diffusers | ❌ | ❌ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Adapter Transformers | ❌ | ❌ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| AllenNLP | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| Asteroid | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| BERTopic | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| docTR | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| ESPnet | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| fastai | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Keras | ❌ | ❌ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Flair | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| MBRL-Lib | ❌ | ❌ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| ML-Agents | ❌ | ❌ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| NeMo | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| PaddleNLP | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Pyannote | ❌ | ❌ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| PyCTCDecode | ❌ | ❌ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| Pythae | ❌ | ❌ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| RL-Baselines3-Zoo | ❌ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Sample Factory | ❌ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Sentence Transformers | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| spaCy | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| SpanMarker | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Scikit Learn (using skops) | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Speechbrain | ✅ | ✅ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| Stable-Baselines3 | ❌ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| TensorFlowTTS | ❌ | ❌ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
| Timm | ✅ | ✅ | ✅ | ✅ |
+----------------------------+---------------+---------+-------------------+-------------+
| Transformers.js | ❌ | ❌ | ✅ | ❌ |
+----------------------------+---------------+---------+-------------------+-------------+
HuggingFace Supported Libraries Description 各lib库具体链接参见
Library Description
🤗 Transformers State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX
🤗 Diffusers A modular toolbox for inference and training of diffusion models
Adapter Transformers Extends 🤗Transformers with Adapters.
AllenNLP An open-source NLP research library, built on PyTorch.
Asteroid Pytorch-based audio source separation toolkit
BERTopic BERTopic is a topic modeling library for text and images
docTR Models and datasets for OCR-related tasks in PyTorch & TensorFlow
ESPnet End-to-end speech processing toolkit (e.g. TTS)
fastai Library to train fast and accurate models with state-of-the-art outputs.
Keras Library that uses a consistent and simple API to build models leveraging TensorFlow and its ecosystem.
Flair Very simple framework for state-of-the-art NLP.
MBRL-Lib PyTorch implementations of MBRL Algorithms.
ML-Agents Enables games and simulations made with Unity to serve as environments for training intelligent agents.
NeMo Conversational AI toolkit built for researchers
PaddleNLP Easy-to-use and powerful NLP library built on PaddlePaddle
Pyannote Neural building blocks for speaker diarization.
PyCTCDecode Language model supported CTC decoding for speech recognition
Pythae Unifyed framework for Generative Autoencoders in Python
RL-Baselines3-Zoo Training framework for Reinforcement Learning, using Stable Baselines3.
Sample Factory Codebase for high throughput asynchronous reinforcement learning.
Sentence Transformers Compute dense vector representations for sentences, paragraphs, and images.
spaCy Advanced Natural Language Processing in Python and Cython.
SpanMarker Familiar, simple and state-of-the-art Named Entity Recognition.
ScikitLearn(using skops) Machine Learning in Python.
Speechbrain A PyTorch Powered Speech Toolkit.
Stable-Baselines3 Set of reliable implementations of deep reinforcement learning algorithms in PyTorch
TensorFlowTTS Real-time state-of-the-art speech synthesis architectures.
Timm Collection of image models, scripts, pretrained weights, etc.
Transformers.js State-of-the-art Machine Learning for the web. Run 🤗 Transformers directly in your browser, with no need for a server!
Transformers¶
transformers is a library with state-of-the-art Machine Learning for Pytorch, TensorFlow and JAX. It provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
You can find models for many different tasks:
01. Extracting the answer from a context (question-answering).
02. Creating summaries from a large text (summarization).
03. Classify text (e.g. as spam or not spam, text-classification).
04. Generate a new text with models such as GPT (text-generation).
05. Identify parts of speech (verb, subject, etc.)
or entities (country, organization, etc.) in a sentence (token-classification).
06. Transcribe audio files to text (automatic-speech-recognition).
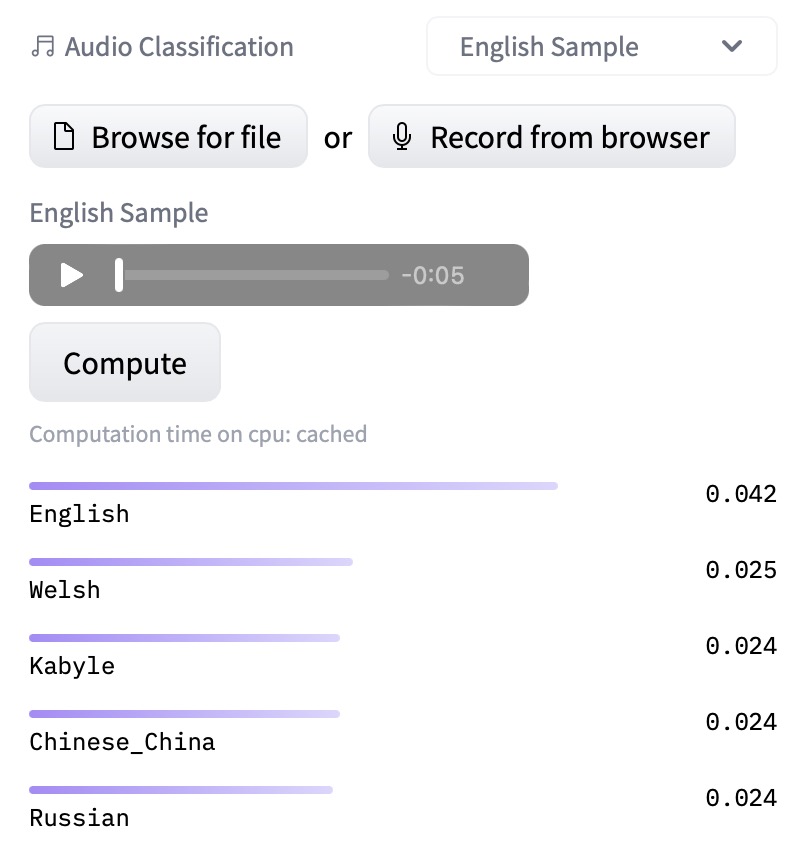
07. Classify the speaker or language in an audio file (audio-classification).
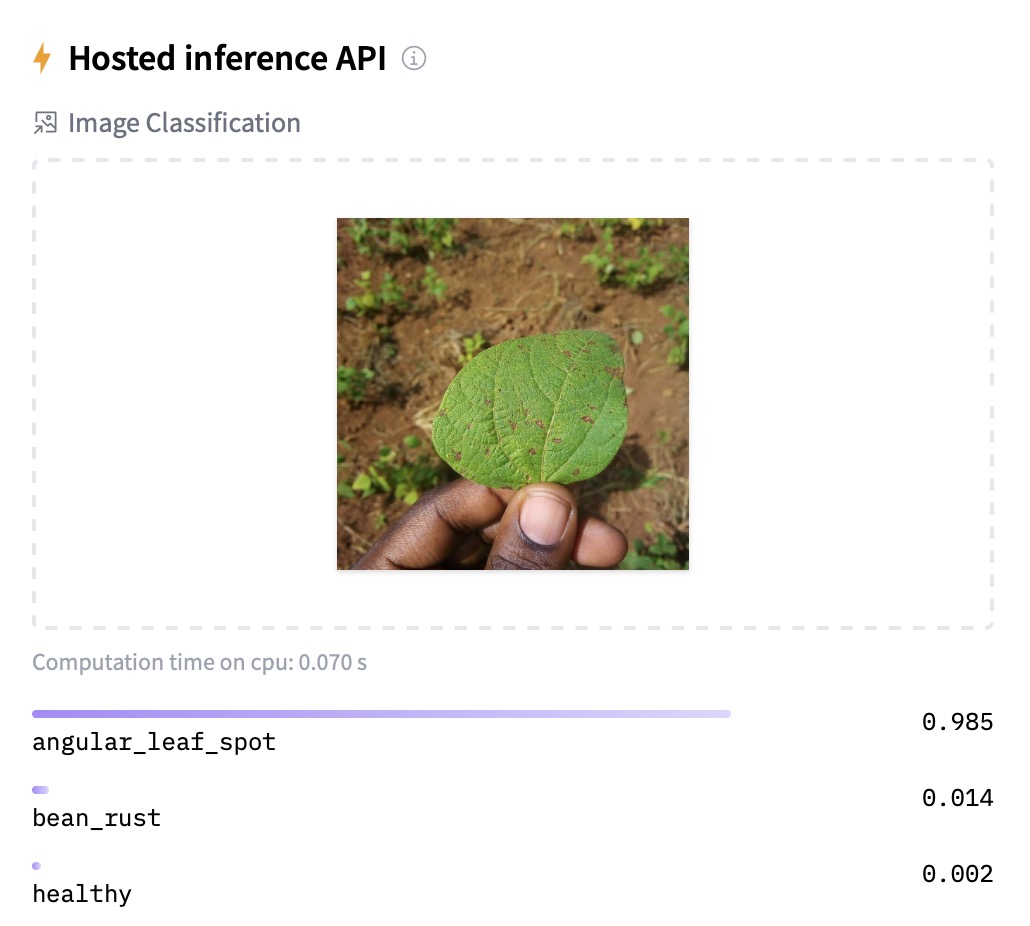
08. Detect objects in an image (object-detection).
09. Segment an image (image-segmentation).
10. Do Reinforcement Learning (reinforcement-learning)
Using existing models:
# With pipeline, just specify the task and the model id from the Hub.
from transformers import pipeline
pipe = pipeline("text-generation", model="distilgpt2")
# If you want more control, you will need to define the tokenizer and model.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
其他资源
Transformers library: https://github.com/huggingface/transformers
Transformers docs: https://huggingface.co/docs/transformers/index
Share a model guide: https://huggingface.co/docs/transformers/model_sharing
Adapter Transformers¶
安装:
pip install -U adapter-transformers
adapter-transformersis a library that extends 🤗 transformers by allowing to integrate, train and use Adapters and other efficient fine-tuning methods. The library is fully compatible with 🤗 transformers. Adapters are small learnt layers inserted within each layer of a pre-trained model. You can learn more about this in the original paper.Adapter Hub repository: https://github.com/adapter-hub/hub
AdapterHub: https://adapterhub.ml/explore/
official guide: https://docs.adapterhub.ml/index.html
Adapter Transformers library: https://github.com/adapter-hub/adapter-transformers
Integration with Hub docs: https://docs.adapterhub.ml/huggingface_hub.html
示例:
from transformers import AutoModelWithHeads
model = AutoModelWithHeads.from_pretrained("bert-base-uncased")
adapter_name = model.load_adapter("AdapterHub/bert-base-uncased-pf-emotion", source="hf")
model.active_adapters = adapter_name
find all Adapter Models programmatically:
from transformers import list_adapters
# source can be "ah" (AdapterHub), "hf" (hf.co) or None (for both, default)
adapter_infos = list_adapters(source="hf", model_name="bert-base-uncased")
AllenNLP¶
allennlp is a NLP library for developing state-of-the-art models on different linguistic tasks. It provides high-level abstractions and APIs for common components and models in modern NLP. It also provides an extensible framework that makes it easy to run and manage NLP experiments.

AllenNLP website: https://allenai.org/allennlp
AllenNLP repository: https://github.com/allenai/allennlp
示例:
import allennlp_models
from allennlp.predictors.predictor import Predictor
predictor = Predictor.from_path("hf://allenai/bidaf-elmo")
predictor_input = {
"passage": "My name is Wolfgang and I live in Berlin",
"question": "Where do I live?"
}
predictions = predictor.predict_json(predictor_input)
Asteroid¶
asteroid is a Pytorch toolkit for audio source separation. It enables fast experimentation on common datasets with support for a large range of datasets and recipes to reproduce papers.
models page: https://huggingface.co/models?filter=asteroid
Asteroid website: https://asteroid-team.github.io/
Asteroid library: https://github.com/asteroid-team/asteroid
Integration docs: https://github.com/asteroid-team/asteroid/blob/master/docs/source/readmes/pretrained_models.md
示例:
from asteroid.models import ConvTasNet
model = ConvTasNet.from_pretrained('mpariente/ConvTasNet_WHAM_sepclean')
ESPnet¶
espnet is an end-to-end toolkit for speech processing, including automatic speech recognition, text to speech, speech enhancement, dirarization and other tasks.

ESPnet model zoo repository: https://github.com/espnet/espnet_model_zoo
ESPnet docs: https://espnet.github.io/espnet/index.html
Integration docs: https://github.com/asteroid-team/asteroid/blob/master/docs/source/readmes/pretrained_models.md
示例:
import soundfile
from espnet2.bin.tts_inference import Text2Speech
text2speech = Text2Speech.from_pretrained("model_name")
speech = text2speech("foobar")["wav"]
soundfile.write("out.wav", speech.numpy(), text2speech.fs, "PCM_16")
fastai¶
fastai is an open-source Deep Learning library that leverages PyTorch and Python to provide high-level components to train fast and accurate neural networks with state-of-the-art outputs on text, vision, and tabular data.
models page: https://huggingface.co/models?library=fastai&sort=downloads
安装:
pip install huggingface_hub["fastai"]
fastai course: https://course.fast.ai/
fastai website: https://www.fast.ai/
Integration with Hub docs: https://docs.fast.ai/huggingface.html
Integration with Hub announcement: https://huggingface.co/blog/fastai
示例:
from huggingface_hub import from_pretrained_fastai
learner = from_pretrained_fastai("espejelomar/identify-my-cat")
_,_,probs = learner.predict(img)
print(f"Probability it's a cat: {100*probs[1].item():.2f}%")
# Probability it's a cat: 100.00%
Keras¶
keras is an open-source machine learning library that uses a consistent and simple API to build models leveraging TensorFlow and its ecosystem.
Keras Developer Guides: https://keras.io/guides/
Keras examples: https://keras.io/examples/
Keras examples on 🤗 Hub: https://huggingface.co/keras-io
Keras learning resources: https://keras.io/getting_started/learning_resources/#moocs
示例:
from huggingface_hub import from_pretrained_keras
model = from_pretrained_keras("keras-io/mobile-vit-xxs")
prediction = model.predict(image)
prediction = tf.squeeze(tf.round(prediction))
print(f'The image is a {classes[(np.argmax(prediction))]}!')
# The image is a sunflower!
ML-Agents¶
ml-agents is an open-source toolkit that enables games and simulations made with Unity to serve as environments for training intelligent agents.
安装:
# Clone the repository
git clone https://github.com/Unity-Technologies/ml-agents
# Go inside the repository and install the package
cd ml-agents
pip3 install -e ./ml-agents-envs
pip3 install -e ./ml-agents
ML-Agents documentation: https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Hugging-Face-Integration.md
Official Unity ML-Agents Spaces demos: https://huggingface.co/unity
示例:
mlagents-load-from-hf --repo-id="Art-phys/poca-SoccerTwos_500M" --local-dir="./downloads"
PaddleNLP¶
Leveraging the PaddlePaddle framework, PaddleNLP is an easy-to-use and powerful NLP library with awesome pre-trained model zoo, supporting wide-range of NLP tasks from research to industrial applications.
安装:
pip install -U paddlenlp
示例:
from paddlenlp.transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
model = AutoModelForMaskedLM.from_pretrained("PaddlePaddle/ernie-1.0-base-zh", from_hf_hub=True)
tokenizer.save_to_hf_hub(repo_id="<my_org_name>/<my_repo_name>")
model.save_to_hf_hub(repo_id="<my_org_name>/<my_repo_name>")
RL-Baselines3-Zoo¶
rl-baselines3-zoo is a training framework for Reinforcement Learning using Stable Baselines3.
RL-Baselines3-Zoo official trained models: https://huggingface.co/sb3
RL-Baselines3-Zoo documentation: https://github.com/DLR-RM/rl-baselines3-zoo
示例:
# Download ppo SpaceInvadersNoFrameskip-v4 model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga sb3
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
Sample Factory¶
sample-factory is a codebase for high throughput asynchronous reinforcement learning. It has integrations with the Hugging Face Hub to share models with evaluation results and training metrics.
Repository: https://github.com/alex-petrenko/sample-factory
安装:
pip install sample-factory
示例:
python -m sample_factory.huggingface.load_from_hub -r <HuggingFace_repo_id> -d <train_dir_path>
Sentence Transformers¶
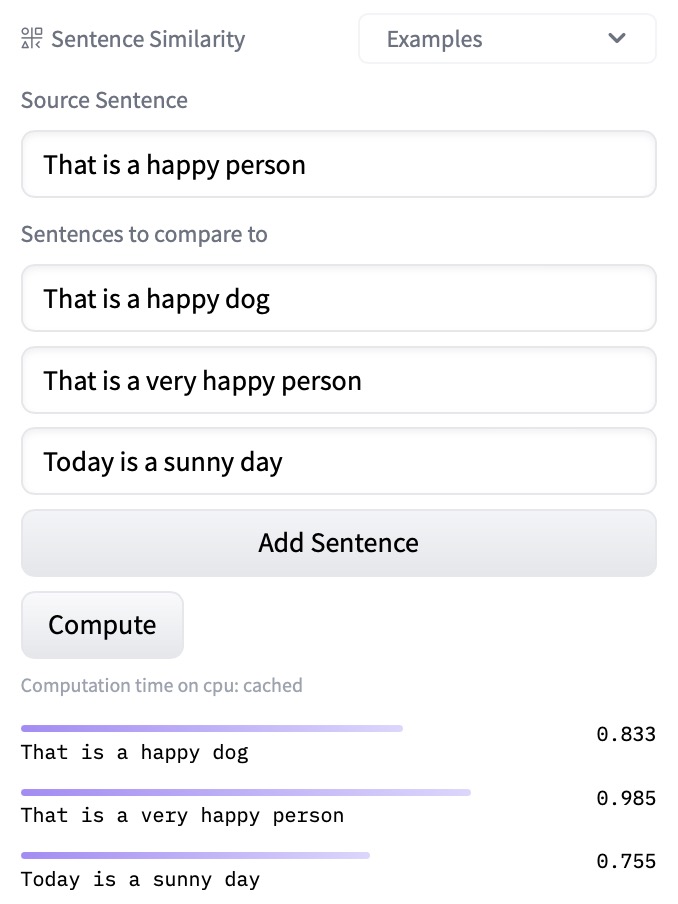
sentence-transformers is a library that provides easy methods to compute embeddings (dense vector representations) for sentences, paragraphs and images. Texts are embedded in a vector space such that similar text is close, which enables applications such as semantic search, clustering, and retrieval.
Sentence Transformers library: https://github.com/UKPLab/sentence-transformers
Sentence Transformers docs: https://www.sbert.net/
Integration with Hub announcement: https://huggingface.co/blog/sentence-transformers-in-the-hub
示例:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
query_embedding = model.encode('How big is London')
passage_embedding = model.encode(['London has 9,787,426 inhabitants at the 2011 census',
'London is known for its finacial district'])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))
spaCy¶
spaCy is a popular library for advanced Natural Language Processing used widely across industry. spaCy makes it easy to use and train pipelines for tasks like named entity recognition, text classification, part of speech tagging and more, and lets you build powerful applications to process and analyze large volumes of text.
安装:
pip install spacy-huggingface-hub
示例:
# Using spacy.load().
import spacy
nlp = spacy.load("en_core_web_sm")
# Importing as module.
import en_core_web_sm
nlp = en_core_web_sm.load()
SpanMarker¶
SpanMarker is a framework for training powerful Named Entity Recognition models using familiar encoders such as BERT, RoBERTa and DeBERTa. Tightly implemented on top of the 🤗 Transformers library, SpanMarker can take good advantage of it. As a result, SpanMarker will be intuitive to use for anyone familiar with Transformers.
安装:
pip install -U span_marker
SpanMarker repository: https://github.com/tomaarsen/SpanMarkerNER
SpanMarker docs: https://tomaarsen.github.io/SpanMarkerNER
示例:
from span_marker import SpanMarkerModel
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-fewnerd-fine-super")
SpeechBrain¶
speechbrain is an open-source and all-in-one conversational toolkit for audio/speech. The goal is to create a single, flexible, and user-friendly toolkit that can be used to easily develop state-of-the-art speech technologies, including systems for speech recognition, speaker recognition, speech enhancement, speech separation, language identification, multi-microphone signal processing, and many others.
示例:
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(
source="speechbrain/urbansound8k_ecapa"
)
out_prob, score, index, text_lab = classifier.classify_file('speechbrain/urbansound8k_ecapa/dog_bark.wav')
SpeechBrain website: https://speechbrain.github.io/
SpeechBrain docs: https://speechbrain.readthedocs.io/en/latest/index.html
Stable-Baselines3¶
stable-baselines3 is a set of reliable implementations of reinforcement learning algorithms in PyTorch.
安装:
pip install stable-baselines3
pip install huggingface-sb3
Hugging Face Stable-Baselines3 documentation: https://github.com/huggingface/huggingface_sb3#hugging-face–x-stable-baselines3-v20
Stable-Baselines3 documentation: https://stable-baselines3.readthedocs.io/en/master/
Stanza¶
stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
stanza docs: https://stanfordnlp.github.io/stanza/
示例:
import stanza
nlp = stanza.Pipeline('en') # download th English model and initialize an English neural pipeline
doc = nlp("Barack Obama was born in Hawaii.") # run annotation over a sentence
TensorBoard¶
TensorBoard provides tooling for tracking and visualizing metrics as well as visualizing models. All repositories that contain TensorBoard traces have an automatic tab with a hosted TensorBoard instance for anyone to check it out without any additional effort!
TensorBoard documentation: https://www.tensorflow.org/tensorboard
timm¶
timm, also known as pytorch-image-models, is an open-source collection of state-of-the-art PyTorch image models, pretrained weights, and utility scripts for training, inference, and validation.
示例:
import timm
# Loading https://huggingface.co/timm/eca_nfnet_l0
model = timm.create_model("hf-hub:timm/eca_nfnet_l0", pretrained=True)
timm (pytorch-image-models) GitHub Repo: https://github.com/rwightman/pytorch-image-models
timm documentation: https://huggingface.co/docs/timm
Transformers.js¶
Transformers.js is a JavaScript library for running 🤗 Transformers directly in your browser, with no need for a server! It is designed to be functionally equivalent to the original Python library, meaning you can run the same pretrained models using a very similar API.
安装:
npm i @xenova/transformers
Transformers.js repository: https://github.com/xenova/transformers.js
Transformers.js docs: https://huggingface.co/docs/transformers.js
Transformers.js demo: https://xenova.github.io/transformers.js/
示例:
// Use a different model for sentiment-analysis
let pipe = await pipeline('sentiment-analysis', 'nlptown/bert-base-multilingual-uncased-sentiment');
Widgets 部件¶
Widgets examples¶
some links to examples¶
text-classification, for instance roberta-large-mnli
token-classification, for instance dbmdz/bert-large-cased-finetuned-conll03-english
question-answering, for instance distilbert-base-uncased-distilled-squad
translation, for instance t5-base
summarization, for instance facebook/bart-large-cnn
conversational, for instance facebook/blenderbot-400M-distill
text-generation, for instance gpt2
fill-mask, for instance distilroberta-base
zero-shot-classification (implemented on top of a nli text-classification model), for instance facebook/bart-large-mnli
table-question-answering, for instance google/tapas-base-finetuned-wtq
sentence-similarity, for instance osanseviero/full-sentence-distillroberta2
详细内容: https://huggingface.co/docs/hub/models-widgets#what-are-all-the-possible-taskwidget-types
Datasets¶
🤗 Datasets documentation: https://huggingface.co/docs/datasets/index
dataset card: https://huggingface.co/docs/hub/datasets-cards
main datasets page: https://huggingface.co/datasets
备注
打开指定数据集时,可以点击按钮``Use in dataset library``查看使用方法
Using Datasets¶
Some datasets on the Hub contain a loading script, which allows you to easily load the dataset when you need it.
Many datasets however do not need to include a loading script, for instance when their data is stored directly in the repository in formats such as CSV, JSON and Parquet. 🤗 Datasets can load those kinds of datasets automatically without a loading script.
how-to guides: https://huggingface.co/docs/datasets/how_to
更多详情参见: Datasets documentation
Adding new datasets¶
三种方法:
Add files manually to the repository through the UI
Push files with the
push_to_hubmethod from 🤗 DatasetsUse Git to commit and push your dataset files
Spaces¶
Hugging Face Spaces: https://huggingface.co/spaces