7.1.7. PEFT¶
GET STARTED¶
PEFT, or Parameter-Efficient Fine-Tuning (PEFT), is a library for efficiently adapting pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model’s parameters.
Supported methods:
LoRA
Prefix Tuning
P-Tuning
Prompt Tuning
AdaLoRA
LLaMA-Adapter
IA3
安装¶
pip install peft
pip install git+https://github.com/huggingface/peft
Quicktour¶
PeftConfig¶
from peft import LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
PeftModel¶
loading the base model you want to finetune:
from transformers import AutoModelForSeq2SeqLM
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
Wrap your base model and peft_config with the get_peft_model function to create a PeftModel:
from peft import get_peft_model
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 输出
"output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
Save and load a model¶
save your model:
model.save_pretrained("output_dir")
# if pushing to Hub
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("my_awesome_peft_model")
load your model:
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
+ peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
+ config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
msg = "Tweet text : @Honda Service has been horrible during the recall process... Label :"
inputs = tokenizer(msg, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 输出
'complaint'
Easy loading with Auto classes¶
- from peft import PeftConfig, PeftModel
- from transformers import AutoModelForCausalLM
+ from peft import AutoPeftModelForCausalLM
- peft_config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
- base_model_path = peft_config.base_model_name_or_path
- transformers_model = AutoModelForCausalLM.from_pretrained(base_model_path)
- peft_model = PeftModel.from_pretrained(transformers_model, peft_config)
+ peft_model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
Currently, supported auto classes are:
AutoPeftModelForCausalLM
AutoPeftModelForSequenceClassification
AutoPeftModelForSeq2SeqLM
AutoPeftModelForTokenClassification
AutoPeftModelForQuestionAnswering and
AutoPeftModelForFeatureExtraction
For other tasks (e.g. Whisper, StableDiffusion), you can load the model with:
- from peft import PeftModel, PeftConfig
+ from peft import AutoPeftModel
- from transformers import WhisperForConditionalGeneration
- model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
peft_model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
- peft_config = PeftConfig.from_pretrained(peft_model_id)
- model = WhisperForConditionalGeneration.from_pretrained(
- peft_config.base_model_name_or_path, load_in_8bit=True, device_map="auto"
- )
- model = PeftModel.from_pretrained(model, peft_model_id)
+ model = AutoPeftModel.from_pretrained(peft_model_id)
TASK GUIDES¶
Image classification using LoRA¶
Install dependencies¶
安装:
!pip install transformers accelerate evaluate datasets peft -q
Check:
import transformers
import accelerate
import peft
print(f"Transformers version: {transformers.__version__}")
print(f"Accelerate version: {accelerate.__version__}")
print(f"PEFT version: {peft.__version__}")
# 输出
"Transformers version: 4.27.4"
"Accelerate version: 0.18.0"
"PEFT version: 0.2.0"
a helper function¶
helper function to check the total number of parameters a model has:
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params}
|| all params: {all_param}
|| trainable%: {100 * trainable_params / all_param:.2f}"
)
生成model:
model_checkpoint = "google/vit-base-patch16-224-in21k"
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(
model_checkpoint,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
使用示例:
>>> print_trainable_parameters(model)
"trainable params: 85876325 || all params: 85876325 || trainable%: 100.00"
Load and prepare a model¶
use get_peft_model to wrap the base model so that “update” matrices are added to the respective places:
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
参数说明:
r:
The dimension used by the LoRA update matrices.
alpha:
Scaling factor.
bias:
Specifies if the bias parameters should be trained.
None denotes none of the bias parameters will be trained.
target_modules:
We’re only interested in targeting the query and value matrices
of the attention blocks of the base model.
modules_to_save:
we want the `classifier` parameters to be trained too
when fine-tuning the base model on our custom dataset.
ensure that the `classifier` parameters are also trained
ensures that these modules are serialized alongside the LoRA trainable parameters
when using utilities like save_pretrained() and push_to_hub().
备注
r and alpha together control the total number of final trainable parameters giving you the flexibility to balance a trade-off between end performance and compute efficiency.
get a new model where only the LoRA parameters are trainable (so-called “update matrices”) while the pre-trained parameters are kept frozen:
lora_model = get_peft_model(model, config)
打印新模型(可训练参数变少好多):
print_trainable_parameters(lora_model)
# 输出
"trainable params: 667493 || all params: 86466149 || trainable%: 0.77"
run inference¶
load the LoRA updated parameters along with our base model for inference:
from peft import PeftConfig, PeftModel
config = PeftConfig.from_pretrained(repo_name)
model = AutoModelForImageClassification.from_pretrained(
config.base_model_name_or_path,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
# Load the LoRA model
inference_model = PeftModel.from_pretrained(model, repo_name)
fetch an example image:
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
image
instantiate an image_processor:
image_processor = AutoImageProcessor.from_pretrained(repo_name)
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
run inference:
with torch.no_grad():
outputs = inference_model(**encoding)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", inference_model.config.id2label[predicted_class_idx])
"Predicted class: beignets"
Prefix tuning for conditional generation¶
Prefix tuning is an additive method where only a sequence of continuous task-specific vectors is attached to the beginning of the input, or prefix.
Only the prefix parameters are optimized and added to the hidden states in every layer of the model.
The tokens of the input sequence can still attend to the prefix as virtual tokens.
Setup¶
defining the model and tokenizer, text and label columns, and some hyperparameters:
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
device = "cuda"
model_name_or_path = "t5-large"
tokenizer_name_or_path = "t5-large"
text_column = "sentence"
label_column = "text_label"
max_length = 128
lr = 1e-2
num_epochs = 5
batch_size = 8
Load dataset¶
数据集是情感分析数据集:
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset["train"][0]
# 输出
{
"sentence": "Profit before taxes was EUR 4.0 mn , down from EUR 4.9 mn .",
"label": 0,
"text_label": "negative"
}
label标签:
dataset["train"].features["label"].
# 输出
['negative', 'neutral', 'positive']
Preprocess dataset¶
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length",
truncation=True, return_tensors="pt")
labels = tokenizer(targets, max_length=2, padding="max_length",
truncation=True, return_tensors="pt")
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
Create a DataLoader from the train and eval datasets:
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(
train_dataset,
shuffle=True,
collate_fn=default_data_collator,
batch_size=batch_size,
pin_memory=True
)
eval_dataloader = DataLoader(
eval_dataset,
collate_fn=default_data_collator,
batch_size=batch_size,
pin_memory=True
)
Train model¶
peft_config = PrefixTuningConfig(
task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
num_virtual_tokens=20
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 输出
"trainable params: 983040 || all params: 738651136 || trainable%: 0.13308583065659835"
Setup the optimizer and learning rate scheduler:
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
write a training loop to begin:
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(
torch.argmax(outputs.logits, -1).detach().cpu().numpy(),
skip_special_tokens=True
)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
model performs on the validation set:
correct = 0
total = 0
for pred, true in zip(eval_preds, dataset["validation"]["text_label"]):
if pred.strip() == true.strip():
correct += 1
total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{dataset['validation']['text_label'][:10]=}")
"accuracy=97.3568281938326 % on the evaluation dataset"
"eval_preds[:10]=['neutral', 'positive', ...]"
"dataset['validation']['text_label'][:10]=['neutral', 'positive', ...]"
Inference¶
Load the configuration and model:
from peft import PeftModel, PeftConfig
peft_model_id = "stevhliu/t5-large_PREFIX_TUNING_SEQ2SEQ"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
Get and tokenize some text about financial news:
inputs = tokenizer(
"The Lithuanian beer market made up 14.41 million liters in January ,
a rise of 0.8 percent from the year-earlier figure ,
the Lithuanian Brewers ' Association reporting citing the results from its members .",
return_tensors="pt",
)
generate the predicted text sentiment:
model.to(device)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
# 输出
["positive"]
Prompt tuning for causal language modeling¶
Setup¶
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
"/", "_"
)
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8
Load dataset¶
dataset = load_dataset("ought/raft", dataset_name)
dataset["train"][0]
# 输出
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2}
Train¶
peft_config:
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
Initialize a base model from AutoModelForCausalLM, and pass it and peft_config to the get_peft_model() function:
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
print(model.print_trainable_parameters())
# 输出
"trainable params: 8192 || all params: 559222784 || trainable%: 0.0014648902430985358"
Setup an optimizer and learning rate scheduler:
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
start training:
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
Inference¶
load the prompt tuned model:
from peft import PeftModel, PeftConfig
peft_model_id = "stevhliu/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
Grab a tweet and tokenize it:
inputs = tokenizer(
f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid.
Can you do something about this?"} Label : ',
return_tensors="pt",
)
run:
model.to(device)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=10,
eos_token_id=3
)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
[
"Tweet text : @nationalgridus I have no water and the bill is current and paid.
Can you do something about this? Label : complaint"
]
Semantic segmentation using LoRA¶
Prepare datasets for training and evaluation¶
from transformers import AutoImageProcessor
checkpoint = "nvidia/mit-b0"
image_processor = AutoImageProcessor.from_pretrained(checkpoint, reduce_labels=True)
Load a base model¶
from transformers import AutoModelForSemanticSegmentation
model = AutoModelForSemanticSegmentation.from_pretrained(
checkpoint, id2label=id2label, label2id=label2id, ignore_mismatched_sizes=True
)
print_trainable_parameters(model)
Wrap the base model as a PeftModel for LoRA training¶
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=32,
lora_alpha=32,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="lora_only",
modules_to_save=["decode_head"],
)
lora_model = get_peft_model(model, config)
print_trainable_parameters(lora_model)
P-tuning for sequence classification¶
P-tuning is a method for automatically searching and optimizing for better prompts in a continuous space.
Setup¶
model_name_or_path = "roberta-large"
task = "mrpc"
num_epochs = 20
lr = 1e-3
batch_size = 32
Load dataset and metric¶
Load dataset:
dataset = load_dataset("glue", task)
dataset["train"][0]
{
"sentence1": 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"sentence2": 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
"label": 1,
"idx": 0,
}
load a metric for evaluating the model’s performance:
metric = evaluate.load("glue", task)
Train¶
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
wrap the base model and peft_config with get_peft_model() to create a PeftModel:
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 输出
"trainable params: 1351938 || all params: 355662082 || trainable%: 0.38011867680626127"
Inference¶
peft_model_id = "smangrul/roberta-large-peft-p-tuning"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(inference_model, peft_model_id)
Get some text and tokenize it:
classes = ["not equivalent", "equivalent"]
sentence1 = "Coast redwood trees are the tallest trees on the planet and can grow over 300 feet tall."
sentence2 = "The coast redwood trees, which can attain a height of over 300 feet, are the tallest trees on earth."
inputs = tokenizer(sentence1, sentence2, truncation=True, padding="longest", return_tensors="pt")
Pass the inputs to the model to classify the sentences:
with torch.no_grad():
outputs = model(**inputs).logits
print(outputs)
paraphrased_text = torch.softmax(outputs, dim=1).tolist()[0]
for i in range(len(classes)):
print(f"{classes[i]}: {int(round(paraphrased_text[i] * 100))}%")
"not equivalent: 4%"
"equivalent: 96%"
CONCEPTUAL GUIDES¶
LoRA¶
To make fine-tuning more efficient, LoRA’s approach is to represent the weight updates with two smaller matrices (called update matrices) through low-rank decomposition.
Merge LoRA weights into the base model¶
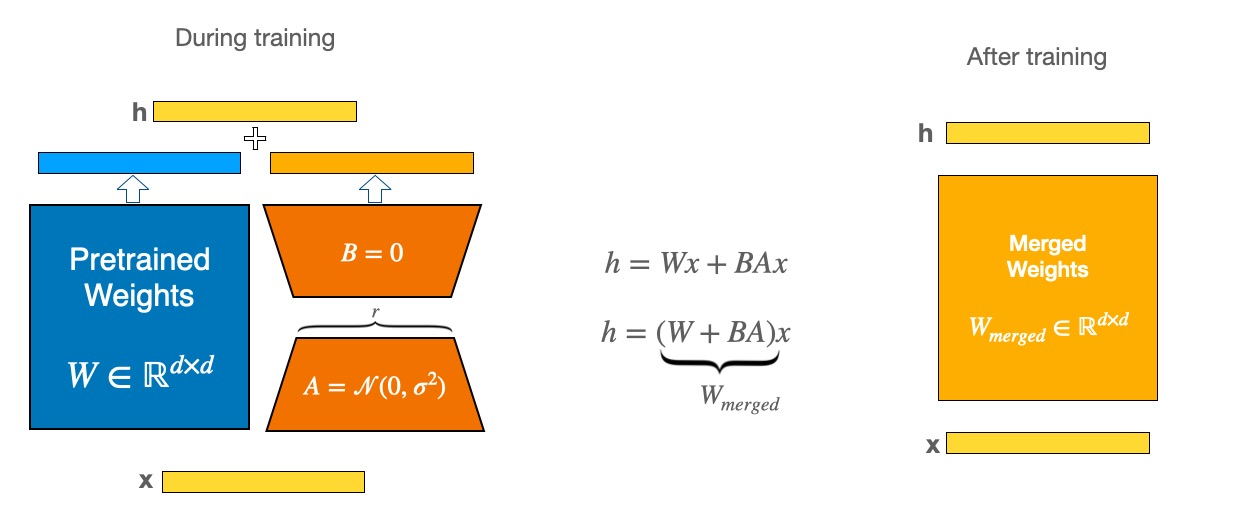
While LoRA is significantly smaller and faster to train, you may encounter latency issues during inference due to separately loading the base model and the LoRA model. To eliminate latency, use the merge_and_unload() function to merge the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.¶
Utils for LoRA¶
merge_adapter()
unmerge_adapter()
unload()
delete_adapter()
add_weighted_adapter()
Common LoRA parameters in PEFT¶
fine-tune a model using LoRA, you need to:
1. Instantiate a base model.
2. Create a configuration (`LoraConfig`) where you define LoRA-specific parameters.
3. Wrap the base model with `get_peft_model()` to get a trainable `PeftModel`.
4. Train the `PeftModel` as you normally would train the base model.
LoraConfig allows you to control how LoRA is applied to the base model through the following parameters:
r: the rank of the update matrices, expressed in int. Lower rank results in smaller update matrices with fewer trainable parameters.
target_modules: The modules (for example, attention blocks) to apply the LoRA update matrices.
alpha: LoRA scaling factor.
bias: Specifies if the bias parameters should be trained. Can be 'none', 'all' or 'lora_only'.
modules_to_save: List of modules apart from LoRA layers to be set as trainable and saved in the final checkpoint. These typically include model’s custom head that is randomly initialized for the fine-tuning task.
layers_to_transform: List of layers to be transformed by LoRA. If not specified, all layers in target_modules are transformed.
layers_pattern: Pattern to match layer names in target_modules, if layers_to_transform is specified. By default PeftModel will look at common layer pattern (layers, h, blocks, etc.), use it for exotic and custom models.
Prompting¶
Prompt tuning¶
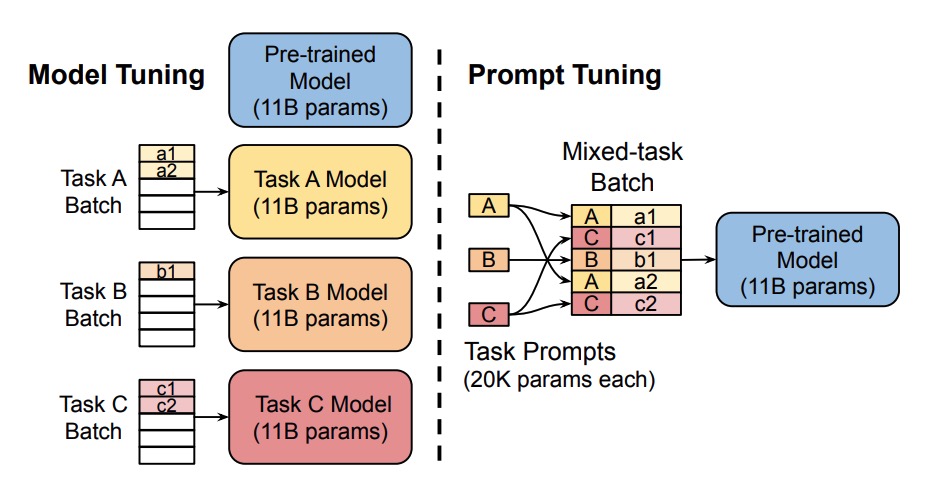
Only train and store a significantly smaller set of task-specific prompt parameters¶
Prompt tuning was developed for text classification tasks on T5 models, and all downstream tasks are cast as a text generation task.
For example, sequence classification usually assigns a single class label to a sequence of text. By casting it as a text generation task, the tokens that make up the class label are generated. Prompts are added to the input as a series of tokens. Typically, the model parameters are fixed which means the prompt tokens are also fixed by the model parameters.
Prefix tuning¶
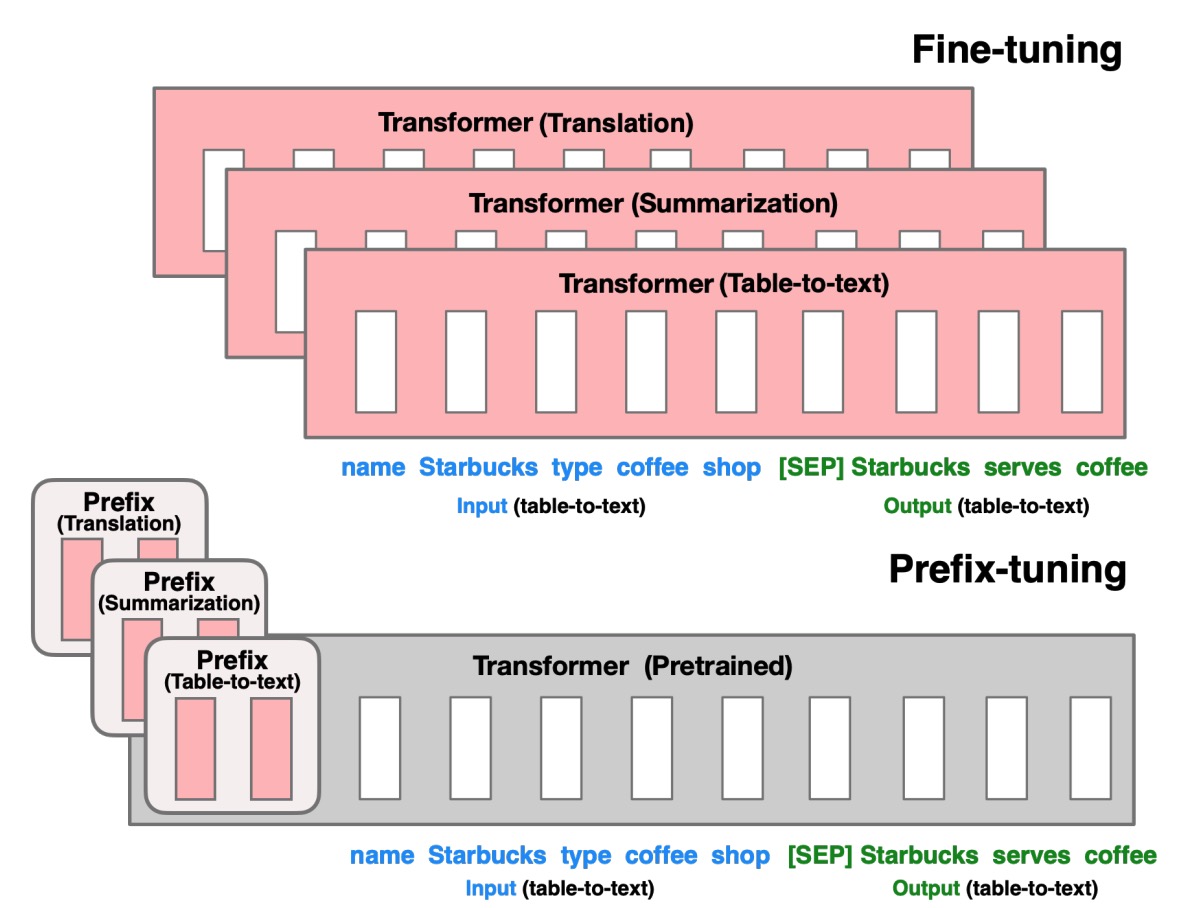
Prefix tuning was designed for natural language generation (NLG) tasks on GPT models.
It is very similar to prompt tuning; prefix tuning also prepends a sequence of task-specific vectors to the input that can be trained and updated while keeping the rest of the pretrained model’s parameters frozen.
The main difference is that the prefix parameters are inserted in all of the model layers, whereas prompt tuning only adds the prompt parameters to the model input embeddings. The prefix parameters are also optimized by a separate feed-forward network (FFN) instead of training directly on the soft prompts because it causes instability and hurts performance. The FFN is discarded after updating the soft prompts.
P-tuning¶
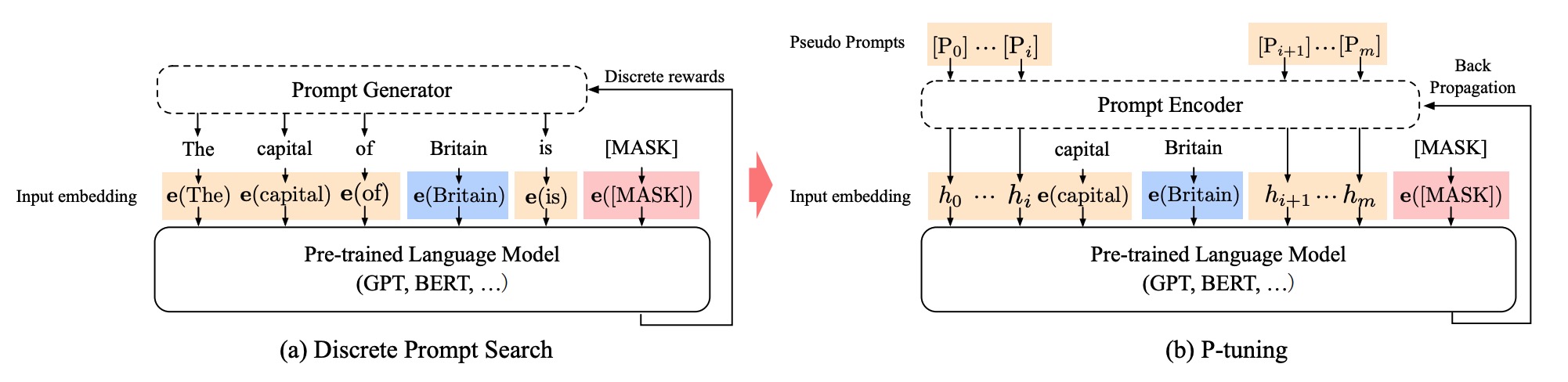
P-tuning is designed for natural language understanding (NLU) tasks and all language models.
It is another variation of a soft prompt method; P-tuning also adds a trainable embedding tensor that can be optimized to find better prompts, and it uses a prompt encoder (a bidirectional long-short term memory network or LSTM) to optimize the prompt parameters.
Unlike prefix tuning though:
the prompt tokens can be inserted anywhere in the input sequence, and it isn’t restricted to only the beginning the prompt tokens are only added to the input instead of adding them to every layer of the model introducing anchor tokens can improve performance because they indicate characteristics of a component in the input sequence
IA3¶
IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations)
参考¶
[论文]Prefix-Tuning: Optimizing Continuous Prompts for Generation: https://arxiv.org/abs/2101.00190
[论文]LoRA: Low-Rank Adaptation of Large Language Models: https://arxiv.org/abs/2106.09685
[论文]The Power of Scale for Parameter-Efficient Prompt Tuning: https://arxiv.org/abs/2104.08691
[论文]GPT Understands, Too(p-tuning): https://arxiv.org/abs/2103.10385
[论文]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale: https://arxiv.org/abs/2208.07339