8.15. LSTM: 长短时记忆(Long Short Term Memory, LSTM)¶
LSTM 可以被简单理解为是一种神经元更加复杂的 RNN,处理时间序列中当间隔和延迟较长时,LSTM 通常比 RNN 效果好。
RNN 相比于 CNN 主要是增加了同层网络的信息互相传递(CNN 网络结果的信息传递仅限于窗口内,而窗口太大计算量会增加所以不宜设置太大,CNN 也就天然的难以解决远程信息依赖的问题,而 RNN 理论上没有这个问题),但是实际上信息传递过程中会出现消失或者爆炸:而 LSTM 主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的 RNN,LSTM 能够在更长的序列中有更好的表现。而 bi-lstm 即信息左向和右向各传递一边进行信息累加,因此这种网络结果就非常适合句子这种天然的需要上下文的序列信息了。
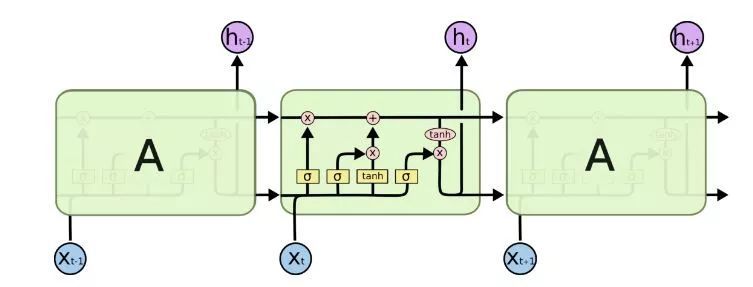
相较于构造简单的 RNN 神经元,LSTM 的神经元要复杂得多,每个神经元接受的输入除了当前时刻样本输入,上一个时刻的输出,还有一个元胞状态(Cell State),LSTM 神经元结构请参见下图:
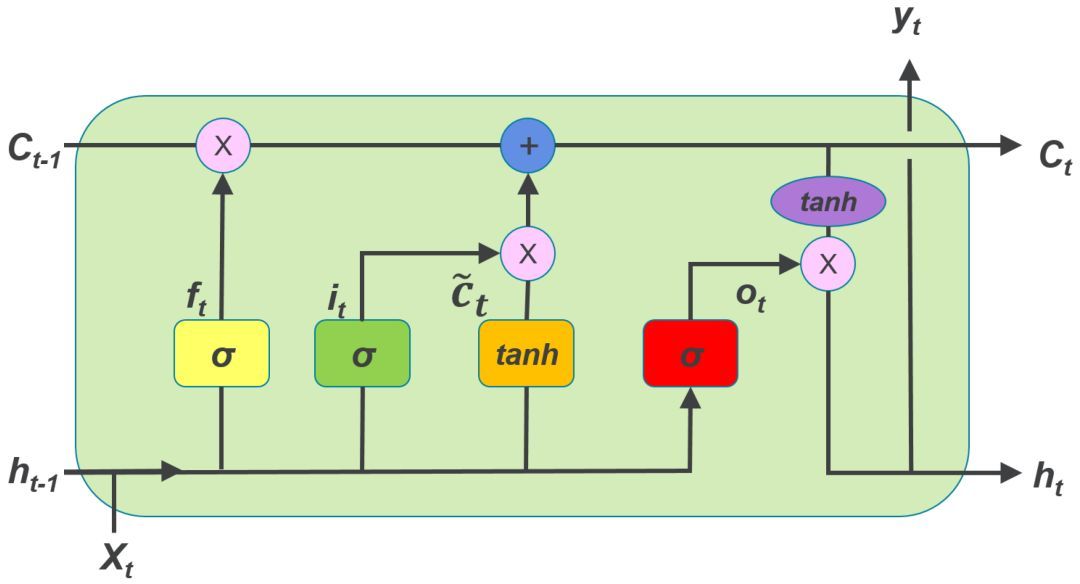
LSTM 神经元中有三个门:
1. 遗忘门(Forget Gate)
2. 输入门(Input Gate)
3. 输出门(Output Gate)
遗忘门(Forget Gate): 接受xt 和 0ht-1 为输入,输出一个0到11之间的值, 用于决定在多大程度上保留上一个时刻的元胞状态ct-1。1表示全保留,0表示全放弃。
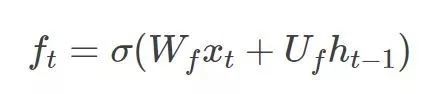
输入门(Input Gate): 用于决定将哪些信息存储在这个时刻的元胞状态 Ct中
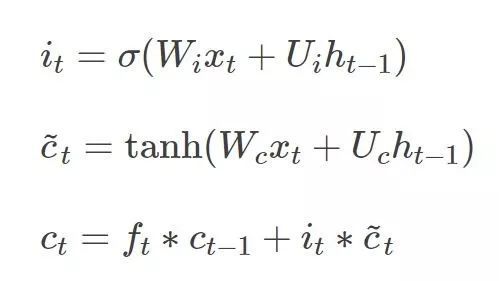
输出门(Output Gate):用于决定输出哪些信息。
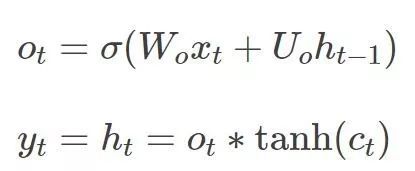
8.15.1. RNN vs LSTM¶
虽然从连接上看,LSTM 和 RNN 颇为相似,但两者的神经元却相差巨大,我们可以看一下下面两个结构图的对比:
LSTM 的结构图:
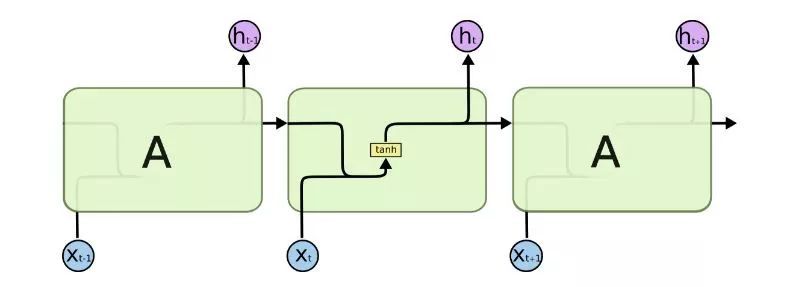
RNN 的结构图:
备注
注意:如果把 LSTM 的遗忘门强行置0,输入门置1,输出门置1,则 LSTM 就变成了标准 RNN。
可见 LSTM 比 RNN 复杂得多,要训练的参数也多得多。
但是,LSTM 在很大程度上缓解了一个在 RNN 训练中非常突出的问题:梯度消失/爆炸(Gradient Vanishing/Exploding)。这个问题不是 RNN 独有的,深度学习模型都有可能遇到,但是对于 RNN 而言,特别严重。
梯度消失和梯度爆炸虽然表现出来的结果正好相反,但出现的原因却是一样的。
因为神经网络的训练中用到反向传播算法,而这个算法是基于梯度下降的——在目标的负梯度方向上对参数进行调整。如此一来就要对激活函数求梯度。
又因为 RNN 存在循环结构,因此激活函数的梯度会乘上多次,这就导致:
如果梯度小于1,那么随着层数增多,梯度更新信息将会以指数形式衰减,即发生了梯度消失(Gradient Vanishing); 如果梯度大于1,那么随着层数增多,梯度更新将以指数形式膨胀,即发生梯度爆炸(Gradient Exploding)。 因为三个门,尤其是遗忘门的存在,LSTM 在训练时能够控制梯度的收敛性,从而梯度消失/爆炸的问题得以缓解,同时也能够保持长期的记忆性。
果然,LSTM 在语音处理、机器翻译、图像说明、手写生成、图像生成等领域都表现出了不俗的战绩。
备注
LSTM 相较于 RNN,能更好地解决梯度消失与梯度爆炸的问题