8.1. LLM¶
8.1.1. MoE架构¶
混合专家(MoE)架构
混合专家(MoE)架构是一种神经网络设计,通过为每个输入动态激活称为“专家”的专用网络子集来提高效率和性能。门控网络决定激活哪些专家导致稀疏激活和减少计算成本。MoE架构由两个关键组件组成:门控网络和专家网络。
从本质上来说,MoE架构的功能就像一个高效的交通系统,根据实时情况和期望的目的地,将每辆车(或在这种情况下是数据)导向最佳路线。每个任务都被路由到最合适的专门处理该特定任务的专家或子模型。这种动态路由确保为每个任务使用最有能力的资源,从而提高模型的整体效率和有效性。
MoE架构利用了三种方法来提高模型的保真度:
1. 通过多个专家完成任务,MoE通过为每个专家添加更多参数来增加模型的参数大小 2. MoE改变了经典的神经网络架构,它包含了一个门控网络,以确定哪些专家被用于指定的任务 3. 每个人工智能模型都有一定程度的微调,因此MoE中的每个专家都经过微调,以达到传统模型无法利用的额外调整层的预期效果
8.1.2. NLI¶
自然语言推理(Natural Language Inference,NLI)是自然语言处理(NLP)领域中的一个重要任务,旨在判断两个给定的文本(通常称为前提和假设)之间的逻辑关系。
LI任务涉及识别以下三种可能的关系:
1.蕴含(Entailment):假设从前提中可以推出。 如果前提为真,那么假设也必须为真。 例如: 前提:所有的鸟都会飞。 假设:麻雀会飞。 关系:蕴含。 2.矛盾(Contradiction):假设与前提相矛盾。 如果前提为真,那么假设必定为假。 例如: 前提:所有的鸟都会飞。 假设:企鹅不会飞。 关系:矛盾。 3.中立(Neutral):假设与前提之间没有直接的逻辑关系 前提的真实性并不能影响假设的真实性。 例如: 前提:所有的鸟都会飞。 假设:有些鸟是红色的。 关系:中立。
应用:
信息检索:帮助搜索引擎理解用户查询与文档内容之间的逻辑关系。
问答系统:确保系统给出的答案与用户问题逻辑一致。
文本摘要:验证摘要内容是否能够从原文中推导出来。
对话系统:确保对话内容的一致性和逻辑性。
NLI数据集:
SNLI(Stanford Natural Language Inference):由斯坦福大学创建的用于训练和评估NLI模型的大型数据集。
MultiNLI(Multi-Genre Natural Language Inference):包含多种领域的文本,旨在评估NLI模型在不同文本领域中的表现。
8.1.3. 生成文本验证¶
SAFE¶
Search-Augmented Factuality Evaluator
https://github.com/google-deepmind/long-form-factuality/tree/main/eval/safe
为解决「幻觉(Hallucination)」问题
与自然语言处理(NLP)领域的模型评估或校验相关的工具或方法,特别是在验证生成文本(如新闻、报告、摘要等)事实性
与 FActScore 相比,主要区别在于,对于每个自包含的原子事实,SAFE 使用语言模型作为代理,在多步骤过程中迭代发出 Google 搜索查询,并推断搜索结果是否支持该事实。在每个步骤中,代理都会根据要检查的给定事实以及先前获得的搜索结果生成搜索查询。经过多个步骤后,模型执行推理以确定搜索结果是否支持该事实。根据实验,SAFE方法比人类注释者效果更好,尽管便宜20倍:与人类的一致率为72%,当他们不同意时,比人类的胜率为76%。
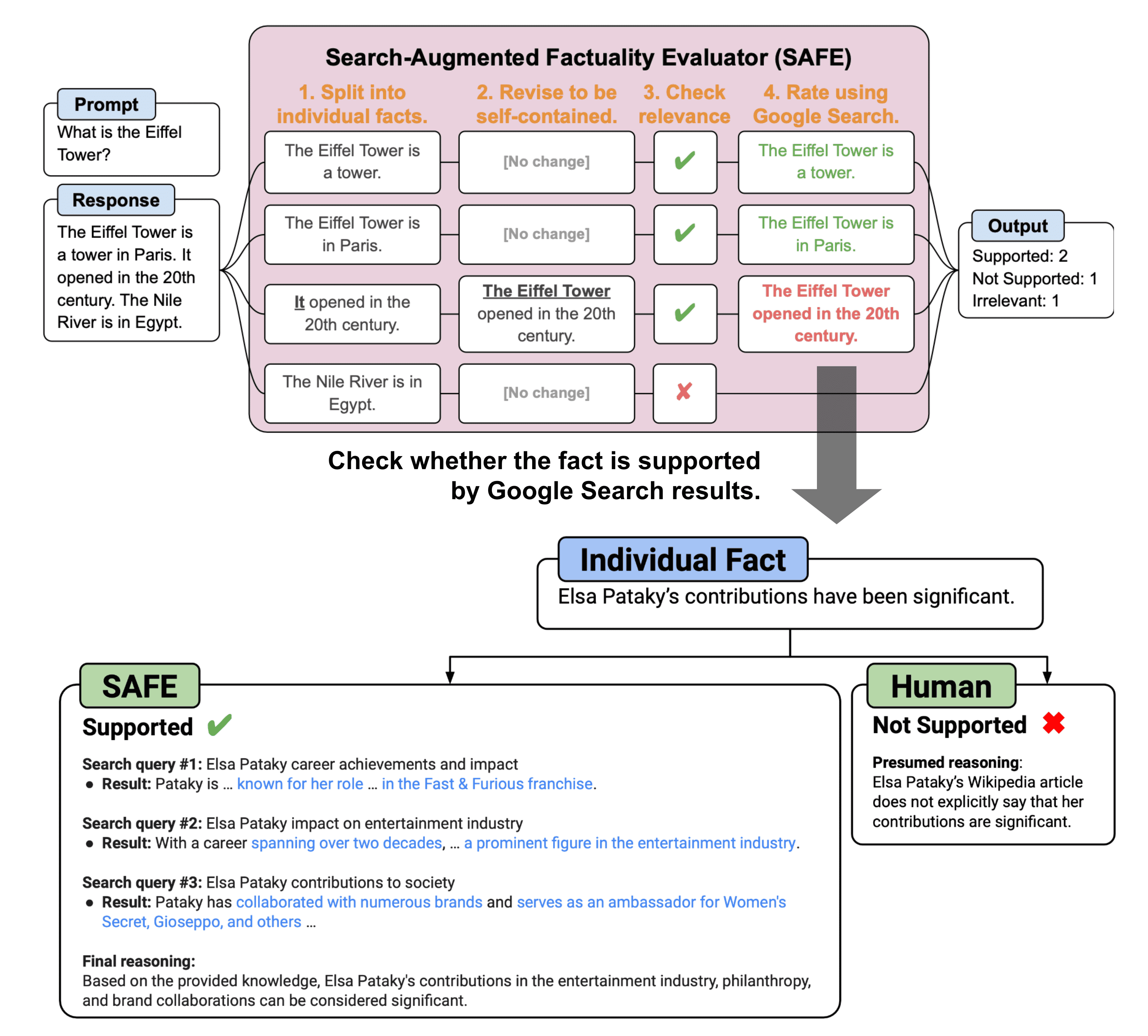
Overview of SAFE for factuality evaluation of long-form LLM generation. (Image source: Wei et al. 2024 )¶
FActScore¶
为解决「幻觉(Hallucination)」问题
FActScore 是一种用于衡量生成文本中事实性的方法。它旨在评估自动生成的文本(如摘要、新闻或对话)在多大程度上与真实信息或事实保持一致。
原理:FActScore 主要通过衡量生成文本与事实性信息源之间的一致性来评估文本的真实性。这个信息源可以是结构化数据、知识图谱、或经过验证的文本(如维基百科文章)。
方法:FActScore 通过使用自然语言处理技术,如信息检索、文本匹配和相似度计算,来确定生成文本中的陈述是否与事实性信息源中的陈述相符。FActScore 的计算可能会涉及多个子任务,例如命名实体识别、关系抽取和文本相似度评估。
参考¶
Extrinsic Hallucinations in LLMs: https://lilianweng.github.io/posts/2024-07-07-hallucination/
8.1.4. ALCE¶
Automatic LLM Citation Evaluation
一个用于评估大语言模型(LLM)生成的文本中引用质量的基准工具或框架
设计目标是通过自动化的方式来评估 LLM 生成的带有引用的文本,特别是关注引用的准确性、相关性和可验证性。
大语言模型生成的内容有时会出现虚构现象(即所谓的“幻觉”),这会导致生成的文本与事实不符,甚至在引用部分出现不可靠的信息。
因此,ALCE 的出现旨在解决以下几个关键问题:
提高生成内容的可信度:通过评估 LLM 引用的质量,ALCE 能够帮助改进模型,使其生成更具事实性和可验证性的文本
自动化评估:与依赖人类评估不同,ALCE 提供了一个自动化的基准,用于在不同的模型和方法之间进行可重复的比较。这有助于推动研究的标准化,并降低复现和比较不同方法的难度
与现有方法的区别:现有的方法往往依赖于商业搜索引擎和人工评估,而 ALCE 提供了一个独立的、可重复的自动评估基准。这使得研究人员可以在没有外部依赖的情况下,对 LLM 的引用生成能力进行系统化的评价
备注
可以查看相关论文
8.1.5. 训练方法¶
预训练¶
所有LLM都依赖于在互联网文本数据上进行大规模的自监督预训练。
仅解码器的LLM遵循因果语言建模目标,通过该目标,模型学习根据之前的token序列预测下一个token。
根据开源LLM分享的预训练细节,文本数据的来源包括CommonCrawl、C4、GitHub、Wikipedia、书籍和在线讨论,如Reddit或StackOverFlow。人们普遍认为,扩展预训练语料库的大小可以提高模型的性能,并与扩展模型大小密切相关,这种现象被称为缩放定律。现代的LLM在数千亿到数万亿token的语料库上进行预训练。
微调¶
微调的目的是通过使用可用的监督来更新权重,使预训练的LLM适应下游任务,这些监督通常时比预训练使用的数据集小一个量级的数据集。
T5是最早将微调框架构建为文本到文本统一框架的之一,用自然语言指令描述每个任务。指令微调后来通过在几个任务上联合训练扩展了微调,每个都用自然语言指令进行描述。指令微调迅速流行起来,因为它能够大幅提高LLM的零样本性能,包括在unseen任务上,特别是在更大的模型规模上。
使用多任务监督微调(通常称为SFT)的标准指令微调仍然可以保证模型在安全、道德和无害的同时遵循人类意图,并可以通过从人类反馈中强化学习(RLHF)进一步改进。
RLHF指的是人类标注者对微调模型的输出进行排序,用于通过强化学习再次微调。最近的工作表明,人类反馈可以被LLM的反馈取代,这一过程称为从人工智能反馈中强化学习(RLAIF)。
直接偏好优化(DPO)绕过了像RLHF那样将奖励模型拟合人类偏好的需要,而是用交叉熵目标直接微调策略,实现了LLM与人类偏好的更有效对齐。
在构建不同任务的指令微调数据集时,重点是质量而不是数量:Lima仅在1000个示例上微调Llama-65B,表现优于GPT-3,而Alpagasus通过将其指令微调数据集从52k清理到9k,对Alpaca进行了改进。
再次预训练¶
再预训练包括从预训练的LLM执行另一轮的预训练,通常比第一阶段的数据量更少。
这样的过程可能有助于快速适应新领域或在LLM中引出新属性。
例如,对Lemur进行再次预训练,以提高编码和推理能力,对Llama-2-long进行扩展上下文窗口。
推理¶
存在几种使用LLM进行自回归解码的序列生成的替代方法,它们的区别在于输出的随机性和多样性程度。
在采样期间增加温度使输出更加多样化,而将其设置为0则会退回到贪婪解码,这在需要确定性输出的场景中可能需要。采样方法top-k和top-p限制了每个解码步骤要采样的token池。
注意力复杂度是关于输入长度的二次型,因此一些技术旨在提高推理速度,特别是在较长的序列长度时。
FlashAttention优化了GPU内存级之间的读写,加速了训练和推理。
FlashDecoding将注意力机制中的key-value(KV)缓存加载并行化,产生8倍的端到端加速。
推测解码使用一个额外的小型语言模型来近似来自LLM的下一个token分布,这在不损失性能的情况下加速了解码。
vLLM使用PagedAttention加速LLM推理和服务,
PagedAttention是一种优化注意力键和值的内存使用的算法。
8.1.6. 其他¶
消融实验¶
ablation
在机器学习和人工智能领域,消融实验是一种通过逐步移除或禁用系统的某个组件,来研究该组件对整体系统性能或行为的影响的方法。