3.4.1. Agent¶
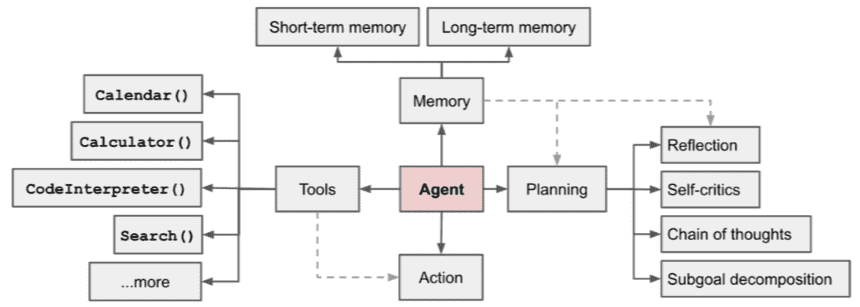
Planning¶
定义:主要作用是对任务进行解析,将任务分解成多个步骤
方案:
Chain of Thought (CoT): 通过逐步推理来增强模型的推理能力和透明度。
Tree of Thought (ToT): 扩展了 CoT 的树形推理方法,允许模型探索多个推理路径。
Graph of Thought (GoT): 通过图形结构组织推理过程,提供更灵活和全面的推理能力。
方案:
LLM+P
通过借助一个外部的经典Planner来进行一个更加长序列的整体规划。
这种方法利用规划域定义语言(Planning Domain Definition Language, PDDL)作为中间接口来描述规划问题。
整个使用过程,首先LLM将问题翻译成“问题PDDL”,接着请求经典Planner根据现有的“领域PDDL”生成一个PDDL Plan,最后将PDDL计划翻译回自然语言(LLM做的)。
根本上讲,Planning Step是外包给外部工具的,当然也有一个前提:需要有特定领域的PDDL和合适的Planner。
Relection and refinement¶
Relfexion¶
(Shinn & Labash 2023)是一个让Agent具备动态记忆和自我反思能力以提高推理能力的框架。Reflexion采用标准的RL设置,其中奖励模型提供简单的二进制奖励,而Action Space则采用ReAct中的设置,即在特定任务的行动空间中加入语言,以实现复杂的推理步骤。在每一个Action at之后,Agent会计算一个启发式函数ht,并根据自我反思的结果决定是否重置环境以开始一个新的循环。
启发式函数判断何时整个循环轨迹是低效的或者何时因为包含了幻觉需要停止。低效规划指的是耗时过长却未成功的循环轨迹。幻觉是指在环境中遇到一连串相同的行动,而这些行动会导致相同的观察结果。
自我反思过程通过给LLM一个two-shot例子创造,每个例子都是一对(失败的轨迹、在计划中指导进一步变化的理想反思)。接着,reflections将会被添加到Agent的工作记忆中作为查询LLM的上下文,最多三个。
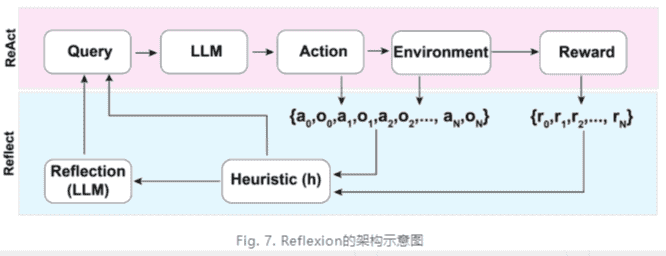
ReAct¶
(Yao et al. 2023)即Reason+Act通过将Action Space扩展为特定任务的离散动作和语言空间的组合,在LLM内部整合了推理(Reasoning)和行动(Action)。前者使LLM能够与环境交互(例如,使用Wikipedia Search的 API),后者通过提示词使得LLM用自然语言生成整体的推理过程。

Memory¶
sensory memory¶
感官记忆:这是记忆的最早期阶段,在接受了原始刺激后保留的感官信息(视觉、听觉等)印象的能力。在LLM中,感官记忆作为对原始输入(包括文本、图像或其他模态)的学习嵌入表示
short-term memory¶
短时记忆(STM)或工作记忆:它存储了我们当前意识到的信息,以及执行复杂认知任务(如学习和推理)所需的信息。短期记忆被认为有大约7个项目的容量,并能够持续20-30秒。在LLM中,短期记忆作为上下文学习。它是短暂且有限的,因为它受到了transformer结构的上下文窗口长度的限制
long-term memory¶
- 长时记忆(LTM):长时记忆可以将信息存储很长时间,从几天到几十年不等,存储容量基本上是无限的。长时记忆分为两种:显性记忆和隐性记忆。在LLM中,长期记忆作为Agent在查询时可以关注的外部向量存储,可以通过快速检索来进行访问
显性/陈述性记忆:对事实和事件的记忆,指那些可以有意识地回忆起的记忆,包括外显记忆(事件和经历)和语义记忆(事实和概括)。
隐形/程序性记忆:这种记忆是无意识的,设计自动执行的技能和例行程序,如骑车、在键盘上打字。
Tools¶
定义:为可被Agent调用的工具,一般以函数或API的形式
Tool Use框架¶
MRKL:
"模块化推理、知识和语言"(Modular Reasoning,Knowledge and Language)的简称,是一种用于自主代理的神经符号架构。
MRKL 系统包含一系列 "专家 "模块,而通用 LLM 则充当路由器,将查询路由到最合适的专家模块。
这些模块可以是神经模块(如深度学习模型),也可以是符号模块(如数学计算器、货币转换器、天气 API)。
HuggingGPT:
(Shen et al. 2023)是一个使用 ChatGPT 作为任务规划器的框架,用于根据模型描述选择 HuggingFace 平台中可用的模型,并根据执行结果总结响应。
包括四个阶段:
1. 任务规划(Task planning)
LLM 充当大脑,将用户请求解析为多个任务
每个任务都有四个相关属性
任务类型、ID、依赖关系和参数
他们使用少量的示例来指导 LLM 进行任务解析和规划
2. 模型选择(Model selection)
LLM 将任务分配给专家模型,其中的要求是一个多选题
LLM 会收到一份可供选择的模型列表
由于上下文长度有限,因此需要进行基于任务类型的过滤
3. 任务执行(Task execution)
专家模型执行特定任务并记录结果
4. 返回结果(Response generation)
LLM 接收执行结果,并向用户提供汇总结果
Tool Use微调¶
TALM:
工具增强型语言模型Tool Augmented Language Models; Parisi et al. 2022)
首先,训练语言模型根据问题输出需要使用的工具和工具相关的参数。
然后,根据模型的输出相应的外部工具并返回相关结果。
最后,训练模型根据问题和外部工具返回的结果,输出最终的答案。
为了能够解决样例不足的问题,作者提出了self-play技术。
首先,使用一个较小的数据集合D训练得到一个TALM,
然后针对数据集中的每一个样例,尝试使用不同的工具来解决这个问题。
如果TALM能够正确的解决这个问题,那么就把这条数据及其相关的工具加入到数据集合D中,
不断对训练集进行扩充,以得到一个大规模的数据集。
Toolformer:
Toolformer的主要工作在于基于LLM构造增强数据集,并让模型进行微调训练。
增强数据集呢主要涉及三个操作:采样、执行、过滤。
采样:从数据集的原始文本中利用上下文学习(in-context learning)采样出潜在的API调用操作及其在原始文本中的位置,基于采样概率利用预先设定的阈值来缓解采样位置错误的问题
执行:即执行API,获取执行结果
过滤:调用的结果有三种,没有调用,调用但未使用执行结果,调用且使用执行结果,基于此可构造正负样本集,进行LLM的微调
参考¶
何谓Agent,为何Agent: https://rv3gbat836y.feishu.cn/docx/GGYxdE7Lho0nNpxnLrZcC21snFq
大模型如何使用工具: https://rv3gbat836y.feishu.cn/docx/IREldifuYoeaVXxWgG1c9ifEnBg