6.3.8. Text Generation Inference¶
From: https://huggingface.co/docs/text-generation-inference/index
GitHub: https://github.com/huggingface/text-generation-inference/
专门用于部署和服务高度优化的LLMs进行推理的库。它包括 Transformers 中未包含的面向部署的优化功能,例如用于提高吞吐量的连续批处理和用于多 GPU 推理的张量并行性。
Hugging Face also provides Text Generation Inference (TGI), a library dedicated to deploying and serving highly optimized LLMs for inference. It includes deployment-oriented optimization features not included in Transformers, such as continuous batching for increasing throughput and tensor parallelism for multi-GPU inference.
备注
这个本质其实是做了一个推理的应用。
Getting started¶
Text Generation Inference¶
Text Generation Inference (TGI) is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and T5.
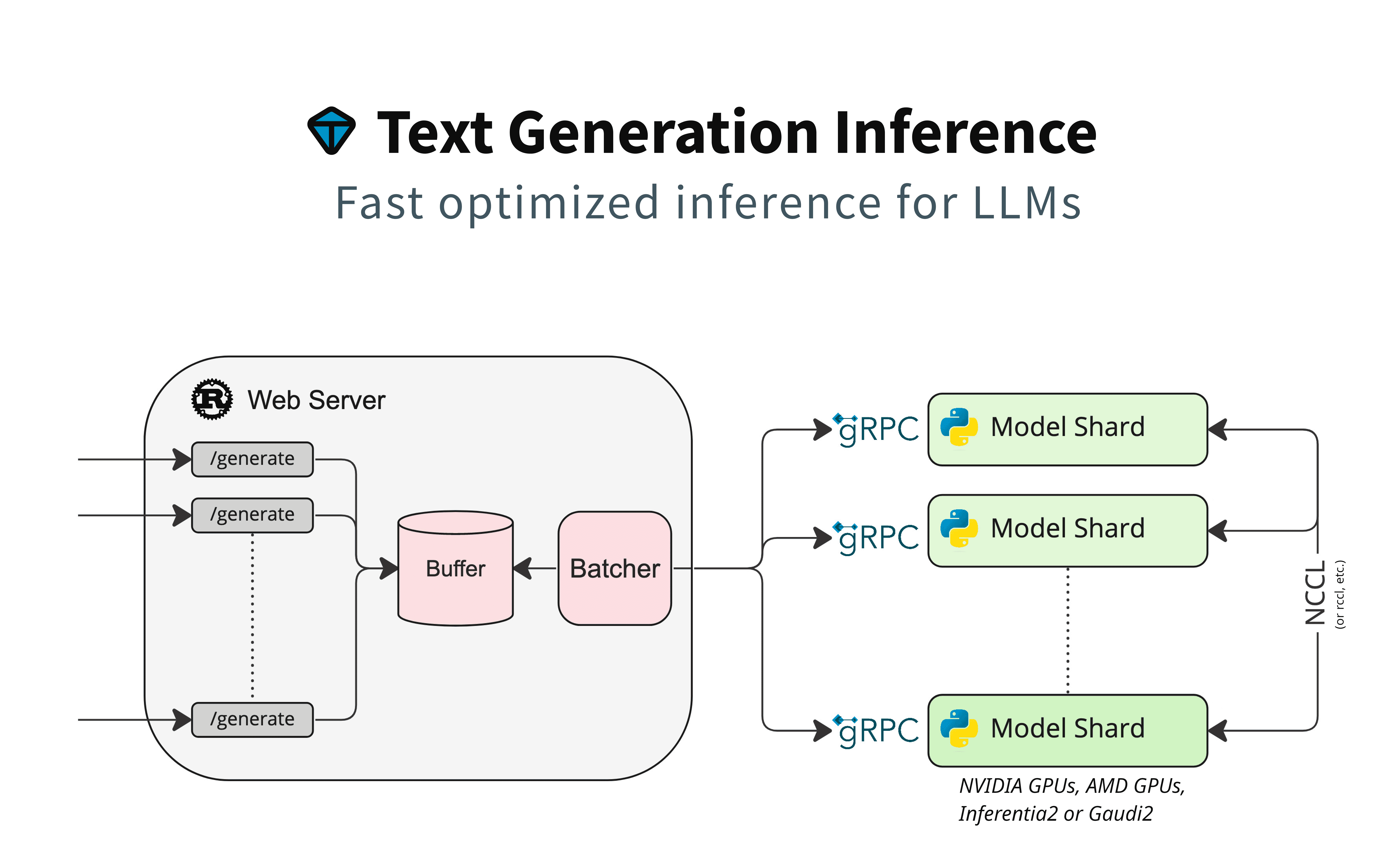
Quick Tour¶
Launching TGI:
model=teknium/OpenHermes-2.5-Mistral-7B
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data \
ghcr.io/huggingface/text-generation-inference:2.4.0 \
--model-id $model
Consuming TGI:
import requests
headers = {
"Content-Type": "application/json",
}
data = {
'inputs': 'What is Deep Learning?',
'parameters': {
'max_new_tokens': 20,
},
}
response = requests.post('http://127.0.0.1:8080/generate', headers=headers, json=data)
print(response.json())
# {'generated_text': '\n\nDeep Learning is a subset of Machine Learning that is concerned with the development of algorithms that can'}
Installation from source¶
Install CLI:
git clone https://github.com/huggingface/text-generation-inference.git && cd text-generation-inference
make install
备注
需要先安装protobuf和rust