4.2.2. NER-命名实体识别¶
命名实体识别(NER)属于自然语言处理中的最常见的也是最基础的任务,是指从文本中识别出特定命名指向的词,比如人名、地名和组织机构名等。命名实体识别任务做标签方法有很多,包括 BIO、BIOSE、IOB、BILOU、BMEWO、BMEWO + 等,最常见的是 BIO 与 BIOES 这两种。不同做标签的方法会对模型效果有些许影响,例如有些时候用 BIOES 会比 BIO 有些许优势。
技术方法:1. 传统方法:
基于规则和基于统计的方法,使用手工设计的规则或特征进行模型训练;2. 深度学习方法:近年来,深度学习模型如 BiLSTM-CRF、BERT 等在 NER 任务上取得了显著的性能提升,能够更好地捕捉上下文信息和语境关系。主要目标是从文本中识别和抽取出具有特定意义的命名实体,这些命名实体通常是人、地点、组织、日期等具有特定名称的实体。
Named Entity Recognition (NER) is a task of extracting some entities from text, such as dates, addresses, people names, etc. Together with intent classification, NER is often used in dialog systems to extract parameters from user’s utterance.
命名实体识别 (NER) 是从文本中提取某些实体的任务,例如日期、地址、人名等。与意图分类一起,NER 通常用于对话系统中,以从用户的话语中提取参数。
应用场景:
1. 信息检索:通过识别文本中的命名实体,提高搜索引擎的准确性
2. 问答系统:用于从问题中提取关键实体,有助于更准确地回答用户的问题
3. 机器翻译:在翻译过程中正确处理文本中的实体,确保翻译的准确性
4. 社交媒体分析:识别社交媒体文本中的人名、地名等信息,用于社交网络分析
5. 金融领域:用于从金融新闻中提取公司、股票等相关信息
6. 医学领域:在医学文献中识别疾病、药物等实体,用于信息提取和知识图谱构建
传统方法-基于规则¶
基于规则的方法的优点是简单直观,但缺点是对于复杂的文本结构和多样性的实体类别可能效果有限。
示例:
import re
def rule_based_ner(text):
entities = []
# 人名识别规则
person_pattern = re.compile(r"([张李王赵陈刘]先生|[A-Za-z]+\s[A-Za-z]+)")
persons = re.findall(person_pattern, text)
entities.extend([(p, "PERSON") for p in persons])
# 地名识别规则
location_pattern = re.compile(r"(北京|上海|广州|深圳|[\u4e00-\u9fa5]+[市省])")
locations = re.findall(location_pattern, text)
entities.extend([(l, "LOCATION") for l in locations])
# 组织机构名识别规则
org_pattern = re.compile(r"(公司|集团|[\u4e00-\u9fa5]+[公司])")
orgs = re.findall(org_pattern, text)
entities.extend([(o, "ORGANIZATION") for o in orgs])
return entities
text = "张先生在北京的公司工作,与李女士一起参加了上海的会议。"
entities = rule_based_ner(text)
print(entities)
# [('张先生', 'PERSON'), ('北京', 'LOCATION'), ('上海', 'LOCATION'), ('张先生在北京的公司', 'ORGANIZATION')]
传统方法-基于统计¶
通过词频统计判断每个词是否可能是人名、地名或组织机构名。这种方法的优点是简单易懂,缺点是可能对于一些出现频率较低但仍然重要的实体难以识别。
BiLSTM+CRF¶
BiLSTM¶
双向长短时记忆
BiLSTM 是一种循环神经网络(RNN)的变体,具有前向和后向两个方向的隐藏状态。
作用: 用于捕捉输入序列中的上下文信息,对文本进行双向建模,更好地理解词汇之间的依赖关系。
CRF¶
条件随机场
定义: CRF 是一种概率图模型,用于对序列标签进行建模。
作用: 在 NER 任务中,CRF 用于建模标签之间的转移概率,确保生成的标签序列是合理的。
BiLSTM+CRF¶
结合方式: BiLSTM 用于提取输入序列的特征,而 CRF 用于对标签序列进行建模,结合了上下文信息和标签间的关系。
优势: 具有更强大的建模能力,特别适用于需要考虑上下文信息和标签关系的序列标注任务,如 NER。
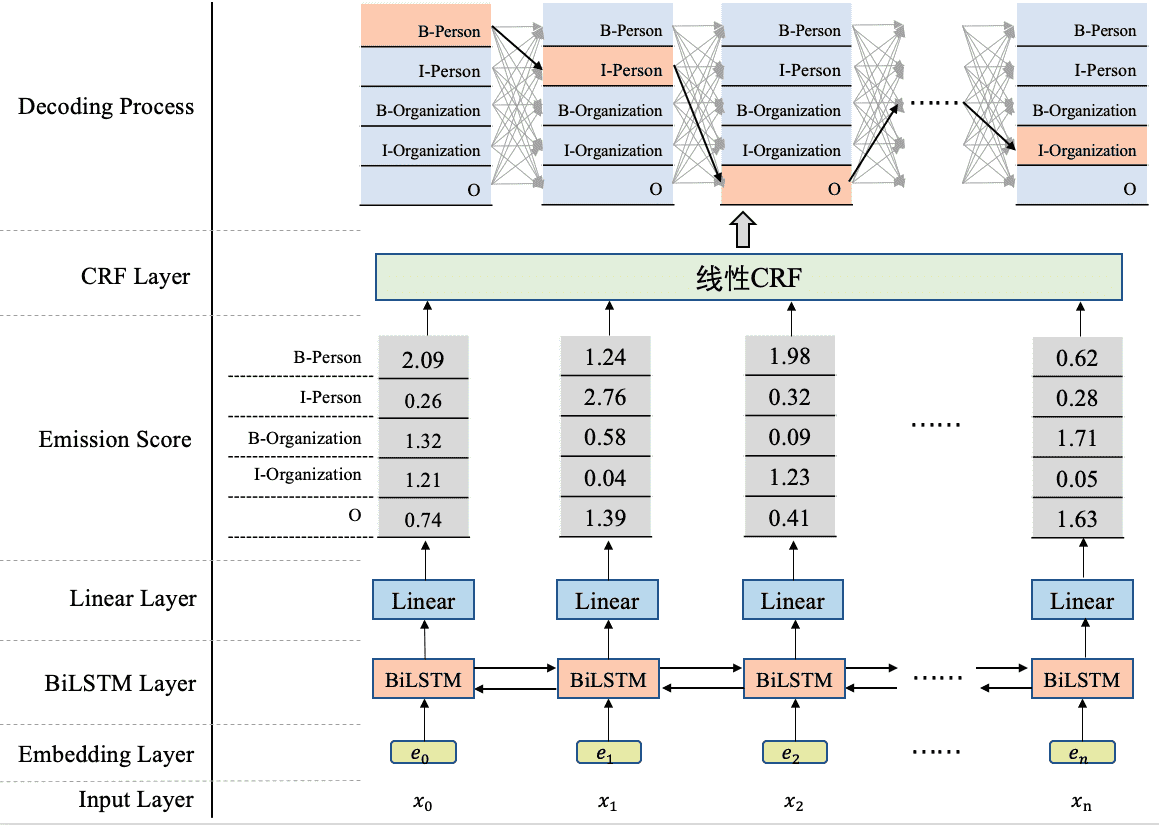
使用 BiLSTM+CRF 实现 NER:在 BiLSTM 上方添加了一个 CRF 层。具体地,在基于 BiLSTM 获得各个位置的标签向量之后,这些标签向量将被作为 发射分数 传入 CRF 中。这些发射分数(标签向量)传入 CRF 之后,CRF 会据此解码出一串标签序列。CRF 的作用就是在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出。¶
备注
总结一下,使用 BiLSTM+CRF 模型架构实现 NER 任务,大致分为两个阶段:使用 BiLSTM 生成发射分数(标签向量),基于发射分数使用 CRF 解码最优的标签路径。