6.3.6. Transformers 4.45.2¶
备注
本文档是自 v4.23.1 版本到本版本的变动部分
Tutorials¶
Load pretrained instances with an AutoClass¶
备注
其他 AutoXXX 参见原始transformers文档
AutoBackbone¶
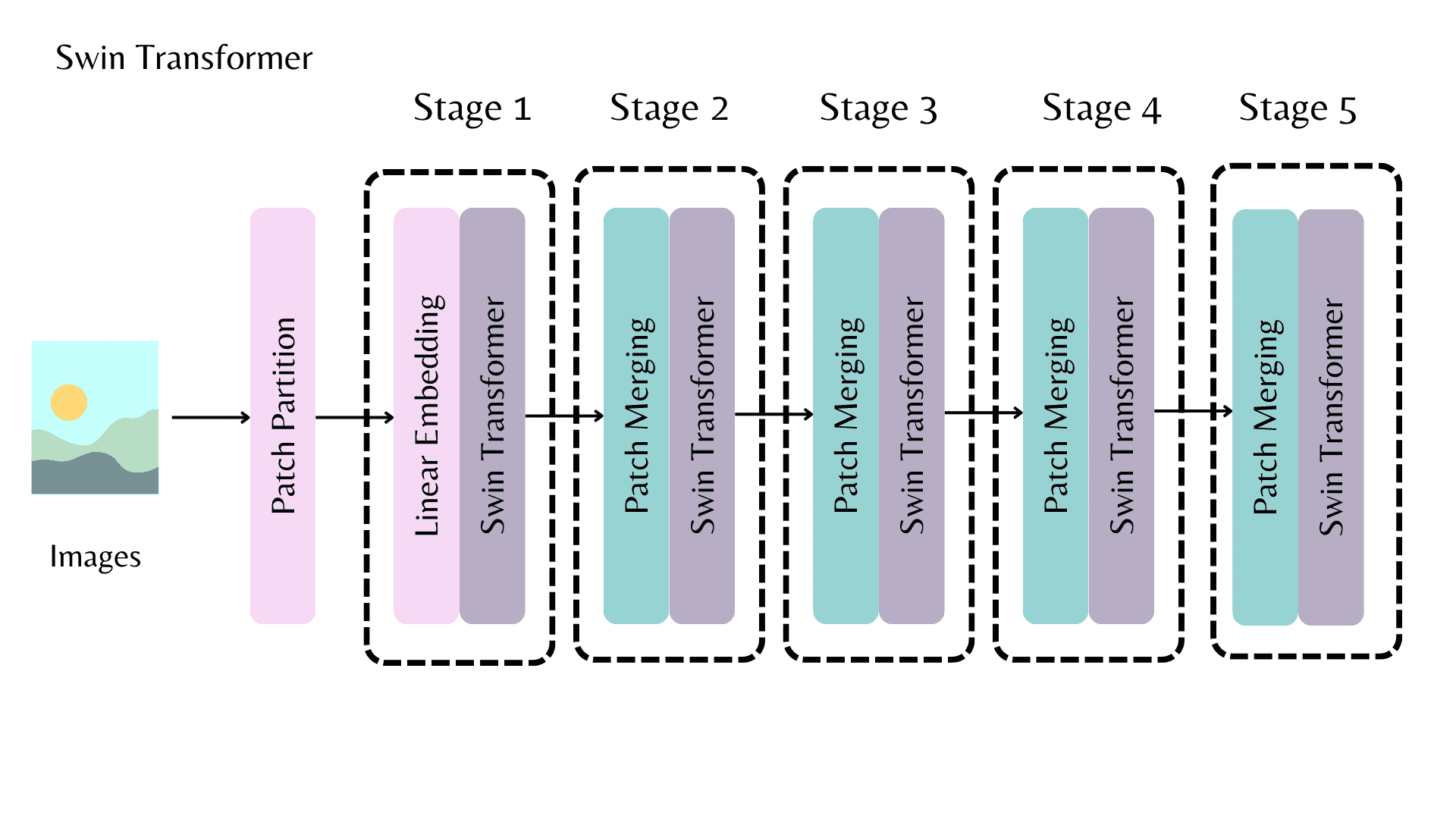
A Swin backbone with multiple stages for outputting a feature map.¶
AutoBackbone 允许您使用预训练模型作为主干,从主干的不同阶段获取特征图。
- from_pretrained() 函数有两个参数:
out_indices 是要从中获取特征图的层的索引
out_features 是要从中获取特征图的图层的名称
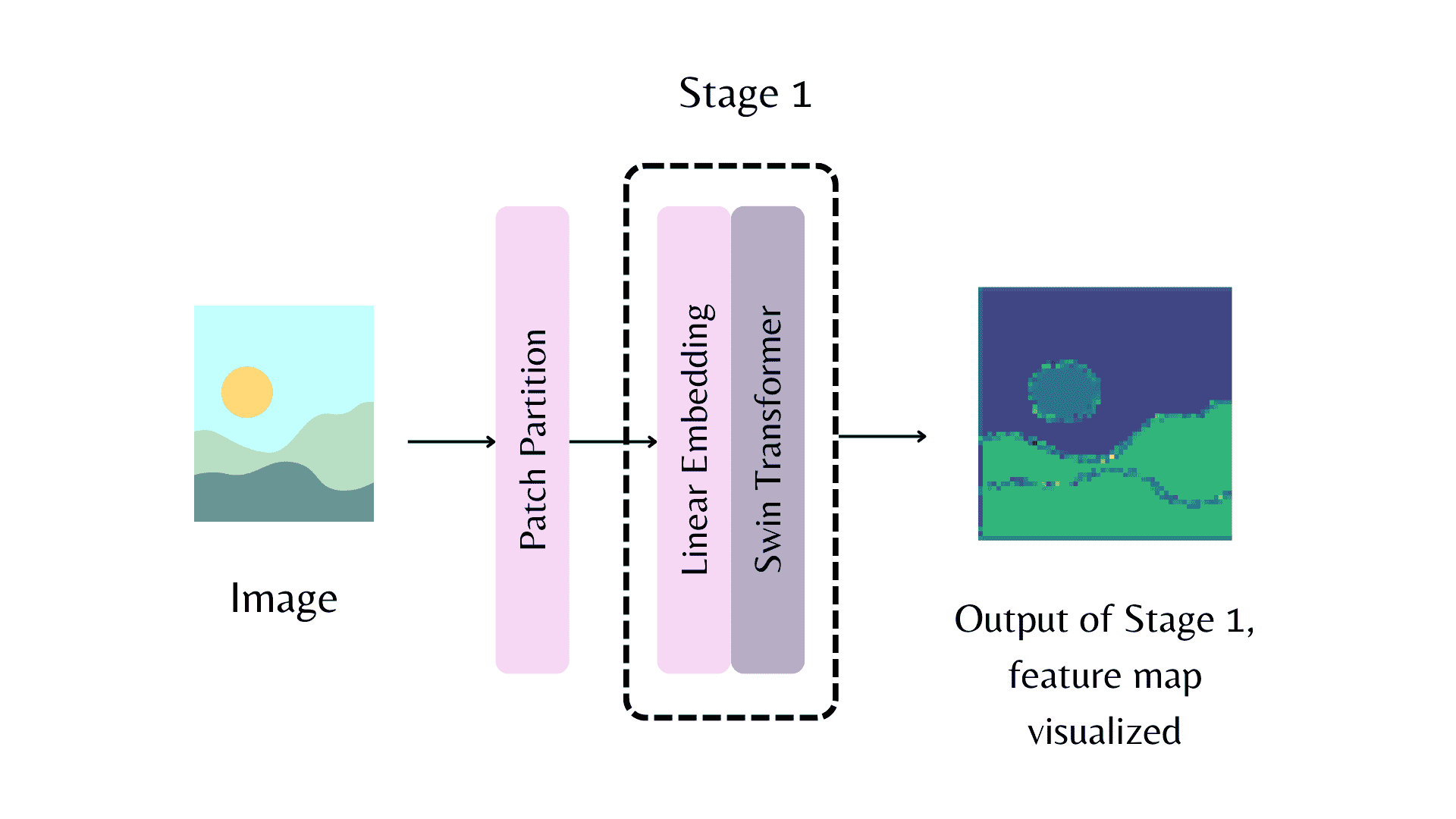
A feature map from the first stage of the backbone. The patch partition refers to the model stem.¶
from transformers import AutoImageProcessor, AutoBackbone
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
inputs = processor(image, return_tensors="pt")
outputs = model(**inputs)
feature_maps = outputs.feature_maps
>> list(feature_maps[0].shape)
Generation with LLMs¶
安装所有必要的库:
pip install transformers bitsandbytes>=0.39.0 -q
Generate text¶
针对
causal language modeling进行训练的语言模型将一系列文本标记作为输入,并返回下一个标记的概率分布。
以迭代方式重复,直到达到某个停止条件。理想情况下,停止条件由模型决定,模型应该学习何时输出序列结束 (EOS) 令牌。如果不是这种情况,则当达到某个预定义的最大长度时,生成将停止。
加载模型:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
)
说明:
device_map 确保将模型移动到您的 GPU
load_in_4bit 应用 4 位动态量化,大幅降低资源需求
preprocess your text input with a tokenizer:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
call the generate() method to returns the generated tokens:
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 'A list of colors: red, blue, green, yellow, orange, purple, pink,'
批处理,这将以较小的延迟和内存成本大大提高吞吐量:
tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
model_inputs = tokenizer(
["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
# ['A list of colors: red, blue, green, yellow, orange, purple, pink,',
# 'Portugal is a country in southwestern Europe, on the Iber']
Common pitfalls¶
备注
生成策略有很多,有时默认值可能不适合您的使用案例
示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
)
Generated output is too short/long¶
如果未在 GenerationConfig 文件中指定,则 generate 默认最多返回 20 个令牌
强烈建议在 generate 调用中手动设置 max_new_tokens 以控制它可以返回的最大新令牌数。
备注
LLMs(更准确地说,仅解码器模型)也会将输入提示作为输出的一部分返回。Keep in mind LLMs (more precisely, decoder-only models) also return the input prompt as part of the output.
示例:
model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
# By default, the output will contain up to 20 tokens
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出
'A sequence of numbers: 1, 2, 3, 4, 5'
# Setting `max_new_tokens` allows you to control the maximum length
generated_ids = model.generate(**model_inputs, max_new_tokens=50)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
Incorrect generation mode¶
默认情况下,除非在 GenerationConfig 文件中指定,否则 generate 在每次迭代(贪婪解码)时选择最可能的 token。
根据您的任务,选择不同的方法
像聊天机器人或写论文这样的创造性任务适合指定
do_sample=True而音频转录或翻译等基于输入的任务受益于贪婪解码。
示例:
# Set seed for reproducibility -- you don't need this unless you want full reproducibility
from transformers import set_seed
set_seed(42)
model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
# LLM + greedy decoding = repetitive, boring output
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出:
'I am a cat. I am a cat. I am a cat. I am a cat'
# With sampling, the output becomes more creative!
generated_ids = model.generate(**model_inputs, do_sample=True)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出
'I am a cat. Specifically, I am an indoor-only cat. I'
Wrong padding side¶
LLMs are decoder-only architectures, meaning they continue to iterate on your input prompt.
If your inputs do not have the same length, they need to be padded.(下面示例里面的123和ABCDE长度不同)
Since LLMs are not trained to continue from pad tokens, your input needs to be left-padded.
Make sure you also don’t forget to pass the attention mask to generate!
示例:
# The tokenizer initialized above has right-padding active by default: the 1st sequence,
# which is shorter, has padding on the right side. Generation fails to capture the logic.
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="right") # 默认是right
model_inputs = tokenizer(
["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出
# '1, 2, 33333333333'
# With left-padding, it works as expected!
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
model_inputs = tokenizer(
["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
).to("cuda")
generated_ids = model.generate(**model_inputs)
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出
# '1, 2, 3, 4, 5, 6,'
Wrong prompt¶
某些模型和任务需要某种输入提示格式才能正常工作。
有关提示的更多信息,包括哪些模型和任务需要小心,请参阅
Task Guides -> Prompting -> LLM prompting guide。下面看一个
chat templating例子(使用tokenizer.apply_chat_template()函数)
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
model = AutoModelForCausalLM.from_pretrained(
"HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
)
set_seed(0)
prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
input_length = model_inputs.input_ids.shape[1]
generated_ids = model.generate(**model_inputs, max_new_tokens=20)
print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
# 输出
# "I'm not a thug, but i can tell you that a human cannot eat"
# 说明
# Oh no, it did not follow our instruction to reply as a thug!
# write a better prompt and use the right template for this model
# (through `tokenizer.apply_chat_template`)
set_seed(0)
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a thug",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
input_length = model_inputs.shape[1]
generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
# 输出
# 'None, you thug. How bout you try to focus on more useful questions?'
# 说明
# As we can see, it followed a proper thug style 😎
Chatting with Transformers¶
Choosing a chat model¶
“8B”或“70B”。这是模型中的参数数。如果没有量化,每个参数大约需要 2 字节的内存。这意味着具有 80 亿个参数的“8B”模型将需要大约 16GB 的内存来适应参数,再加上一些额外的其他开销。它非常适合具有 24GB 显存
“Mixed of Experts” 模型。这些可能会以不同的方式列出它们的尺寸,例如“8x7B”或“141B-A35B”。这里的数字有点模糊,但一般来说,你可以把它理解为模型在第一种情况下大约有 56 (8x7) 亿个参数,在第二种情况下有 1410 亿个参数。
相关代码¶
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Prepare the input as before
chat = [
{"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
{"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
]
# 1: Load the model and tokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
# 2: Apply the chat template
formatted_chat = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
print("Formatted chat:\n", formatted_chat)
# 3: Tokenize the chat (This can be combined with the previous step using tokenize=True)
inputs = tokenizer(formatted_chat, return_tensors="pt", add_special_tokens=False)
# Move the tokenized inputs to the same device the model is on (GPU/CPU)
inputs = {key: tensor.to(model.device) for key, tensor in inputs.items()}
print("Tokenized inputs:\n", inputs)
# 4: Generate text from the model
outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.1)
print("Generated tokens:\n", outputs)
# 5: Decode the output back to a string
decoded_output = tokenizer.decode(outputs[0][inputs['input_ids'].size(1):], skip_special_tokens=True)
print("Decoded output:\n", decoded_output)
Performance, memory and hardware¶
Memory considerations¶
大多数现代语言模型都以“bfloat16”精度进行训练,每个参数仅使用 2 个字节,而不使用占 4 个字节的float32
使用 “quantization” 可以降低到 16 位以下,这是一种有损压缩模型权重的方法。这允许将每个参数压缩到 8 位、4 位甚至更少。
量化:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True) # You can also try load_in_4bit
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", quantization_config=quantization_config)
Performance considerations¶
聊天模型生成文本相对不同,因为它的瓶颈是 内存带宽 而不是 计算能力 ,因为它必须为模型生成的每个 token 从内存中读取每一个active parameter。这意味着您每秒可以从聊天模型生成的 token 数量通常与它这个表达式成正比:
内存总带宽除以模型的大小。一个8B的模型,以 bfloat16 精度加载时,模型大小为 ~16GB。这意味着必须为模型生成的每个令牌从内存中读取 16GB。总内存带宽从消费类 CPU 的
20-100GB/秒到消费类 GPU、Intel Xeon、AMD Threadripper/Epyc 或高端 Apple Silicon 等专用 CPU 的200-900GB/秒不等,最后高达2-3TB/秒的数据中心 GPU,如 Nvidia A100 或 H100。这应该可以让您很好地了解这些不同硬件类型的生成速度。assisted generation的变体:也称为 “推测性采样(speculative sampling)”,通常使用较小的“草稿模型(draft model)”尝试一次猜测多个未来的 token,然后用聊天模型确认这些generations。如果通过聊天模型验证了猜测结果,则每次forward pass可以生成多个 Token,大大缓解了带宽瓶颈,提高了生成速度。
MoE 模型:几种流行的聊天模型,如 Mixtral、Qwen-MoE 和 DBRX,都是 MoE 模型。在这些模型中,并非每个参数对于生成的每个 Token 都处于活动状态。因此,MoE 模型通常具有低得多的内存带宽要求,即使它们的总大小可能相当大。因此,它们可以比相同大小的普通 “密集” 模型快几倍。然而,像辅助生成(assisted generation)这样的技术通常对这些模型无效,因为每个新的推测令牌都会有更多的参数变得活跃,这将抵消 MoE 架构提供的带宽和速度优势。
TASK GUIDES¶
COMPUTER VISION¶
Image-to-Image¶
image enhancement (super resolution, low light enhancement, deraining and so on)
图像增强(超分辨率、弱光增强、去污等)
image inpainting
图像修复
Image Feature Extraction¶
image similarity
图像相似度
image retrieval
图像检索
remove the task-specific head (image classification, object detection etc) and get the features
These features are very useful on a higher level: edge detection, corner detection and so on.
They may also contain information about the real world (e.g. what a cat looks like) depending on how deep the model is.
Therefore, these outputs can be used to train new classifiers on a specific dataset.
Mask Generation¶
Mask Generation 为图像生成语义上有意义的掩模的任务。该任务与图像分割非常相似,但存在许多差异。图像分割模型在标记数据集上进行训练,并且仅限于它们在训练期间看到的类;给定图像,它们返回一组掩码和相应的类。
Mask generation is the task of generating semantically meaningful masks for an image. This task is very similar to image segmentation, but many differences exist.
Image segmentationmodels are trained on labeled datasets and are limited to the classes they have seen during training; they return a set of masks and corresponding classes, given an image.
Mask generation models are trained on large amounts of data and operate in two modes:
1. Prompting mode:
模型接收图像和提示,其中提示可以是对象内图像中的 2D 点位置(XY 坐标)或对象周围的边界框。
在提示模式下,模型仅返回提示所指向的对象上的mask
2. Segment Everything mode:
给定一张图像,模型会生成图像中的每个蒙版。
为此,将生成一个点网格并将其叠加在图像上以进行推理。
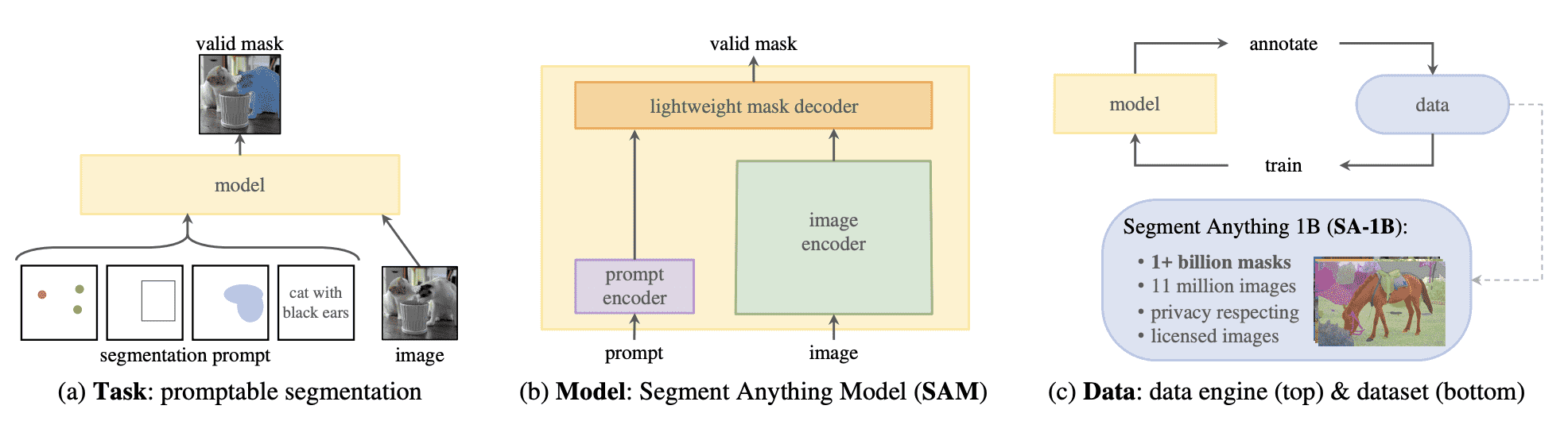
Point Prompting
Box Prompting
备注
具体细看文档吧(有空运行一下相关代码再细分析吧)
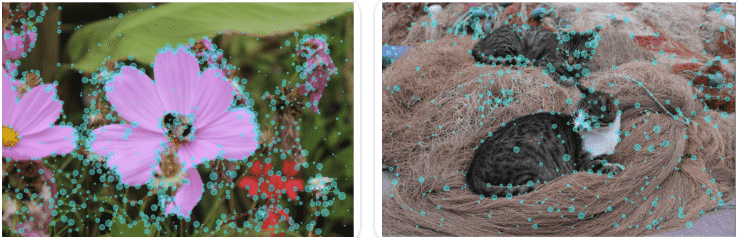
Keypoint Detection¶
关键点检测识别并定位图像中的特定兴趣点。这些关键点也称为地标,代表对象的有意义的特征,例如面部特征或对象部分。
Keypoint detection identifies and locates specific points of interest within an image. These keypoints, also known as landmarks, represent meaningful features of objects, such as facial features(面部特征) or object parts(对象部位).
These models take an image input and return the following outputs:
1. Keypoints and Scores:
兴趣点及其置信度分数
Points of interest and their confidence scores.
2. Descriptors:
每个关键点周围的图像区域的表示形式,捕获其纹理、渐变、方向和其他属性
A representation of the image region surrounding each keypoint,
capturing its texture, gradient, orientation and other properties.
Knowledge Distillation for Computer Vision¶
Knowledge distillation is a technique used to transfer knowledge from a larger, more complex model (teacher) to a smaller, simpler model (student).
MULTIMODAL¶
Visual Question Answering: 基于图像回答开放式问题的任务。支持此任务的模型的输入通常是图像和问题的组合,输出是用自然语言表达的答案。
Image-text-to-tex: 也称为视觉语言模型 (VLM: vision language models),是采用图像输入的语言模型。这些模型可以处理各种任务,从视觉问答(visual question answering)到图像分割(image segmentation)。此任务与图像到文本(image-to-text)有许多相似之处,并且在一些使用场景上有重叠,如:图像字幕(image captioning)。图像到文本(Image-to-text)模型仅接受图像输入并且通常完成特定任务,而 VLM 接受开放式文本和图像输入,并且是更通用的模型。
Video-text-to-text: 也称为视频语言模型(video language models)或具有视频输入的视觉语言模型(vision language models with video input),是采用视频输入的语言模型。这些模型可以处理各种任务,从视频问答(video question answering)到视频字幕(video captioning)。
Generation¶
Text generation strategies¶
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy that the generate() method will use.
选择输出token来生成文本的过程称为 decoding ,您可以自定义generate()方法将使用的解码策略(decoding strategy)
修改解码策略不会改变任何可训练参数的值。但是,它会对生成的输出的质量产生显着影响。
Default text generation configuration¶
当您显式加载模型时,您可以通过 model.generation_config 检查模型附带的生成配置:
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256
}
备注
打印model.generation_config仅显示与默认生成配置不同的值,并且不列出任何默认值。
default generation configuration:
input prompt to a maximum: 20 token
default decoding strategy is greedy search
Customize text generation¶
通过将参数及其值直接传递给generate方法来覆盖任何generation_config:
my_model.generate(**inputs, num_beams=4, do_sample=True)
经常调整的参数:
1. max_new_tokens:
要生成的最大令牌数(the maximum number of tokens to generate)
输出序列的大小,不包括输入prompt
2. num_beams:
通过指定大于 1 的波束数量,您可以有效地从贪婪搜索切换到波束搜索
3. do_sample:
如果设置为True ,此参数启用解码策略,例如多项式采样、波束搜索多项式采样、Top-K 采样和 Top-p 采样。
4. num_return_sequences:
每个输入返回的序列候选数
该选项仅适用于支持多个序列候选的解码策略,例如波束搜索(beam_search)和 采样(sampling)
贪婪搜索(greedy_search)和对比搜索(contrastive_search)等解码策略返回单个输出序列
Save a custom decoding strategy with your model¶
specific generation configuration:
from transformers import AutoModelForCausalLM, GenerationConfig
model = AutoModelForCausalLM.from_pretrained("my_account/my_model")
generation_config = GenerationConfig(
max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
)
generation_config.save_pretrained("my_account/my_model")
如果您想为单个模型存储多个生成配置(例如,一种用于通过采样生成创意文本,一种用于通过集束搜索进行摘要)时会很有用:
# 使用GenerationConfig.save_pretrained()中的config_file_name参数将多个生成配置存储在单个目录中。
# 使用GenerationConfig.from_pretrained()实例化它们
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
translation_generation_config = GenerationConfig(
num_beams=4,
early_stopping=True,
decoder_start_token_id=0,
eos_token_id=model.config.eos_token_id,
pad_token=model.config.pad_token_id,
)
# 说明:通过指令配置文件名把相关配置写入到指定文件和从指定文件加载
translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
outputs = model.generate(**inputs, generation_config=generation_config)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
Streaming¶
警告
流媒体类的 API 仍在开发中,将来可能会发生变化。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
streamer = TextStreamer(tok)
# Despite returning the usual output, the streamer will also print the generated text to stdout.
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
# 输出:
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
Watermarking¶
论文: On the Reliability of Watermarks for Large Language Models: https://arxiv.org/abs/2306.04634
Decoding strategies¶
常见解码策略的工作原理: https://huggingface.co/blog/how-to-generate
影响模型的generate()结果有2
解码策略(decoding strategies)主要基于 Logits(下一个标记的概率分布),因此选择一个好的 Logits操作策略(logits manipulation strategy)可以大有帮助!
除了选择解码策略之外,操作逻辑(manipulating the logits)是您可以采取的另一个方法。流行的 logits 操作策略包括top_p 、 min_p和repetition_penalty
Greedy Search¶
默认使用贪婪搜索解码,因此您不必传递任何参数来启用它。
这意味着参数num_beams设置为 1 且do_sample=False 。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "I look forward to"
checkpoint = "distilbert/distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
# 输出
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
Contrastive search¶
论文A Contrastive Framework for Neural Text Generation: https://arxiv.org/abs/2202.06417
启用和控制对比搜索行为的两个主要参数是penalty_alpha和top_k
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "openai-community/gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Hugging Face Company is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
# ['Hugging Face Company is a family owned and operated business. .... We look forward to hearing from you!']
Multinomial sampling¶
与总是选择概率最高的标记作为下一个标记的贪婪搜索相反,多项式采样(也称为祖先采样)根据模型给出的整个词汇表的概率分布随机选择下一个标记。
每个具有非零概率的令牌都有被选择的机会,从而降低了重复的风险。
设置do_sample=True和num_beams=1
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(0) # For reproducibility
checkpoint = "openai-community/gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Today was an amazing day because"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
Beam-search decoding¶
与贪婪搜索不同,波束搜索解码在每个时间步保留多个假设,并最终选择整个序列总体概率最高的假设。
这样做的优点是可以识别以较低概率初始标记开始的高概率序列,并且会被贪婪搜索忽略。
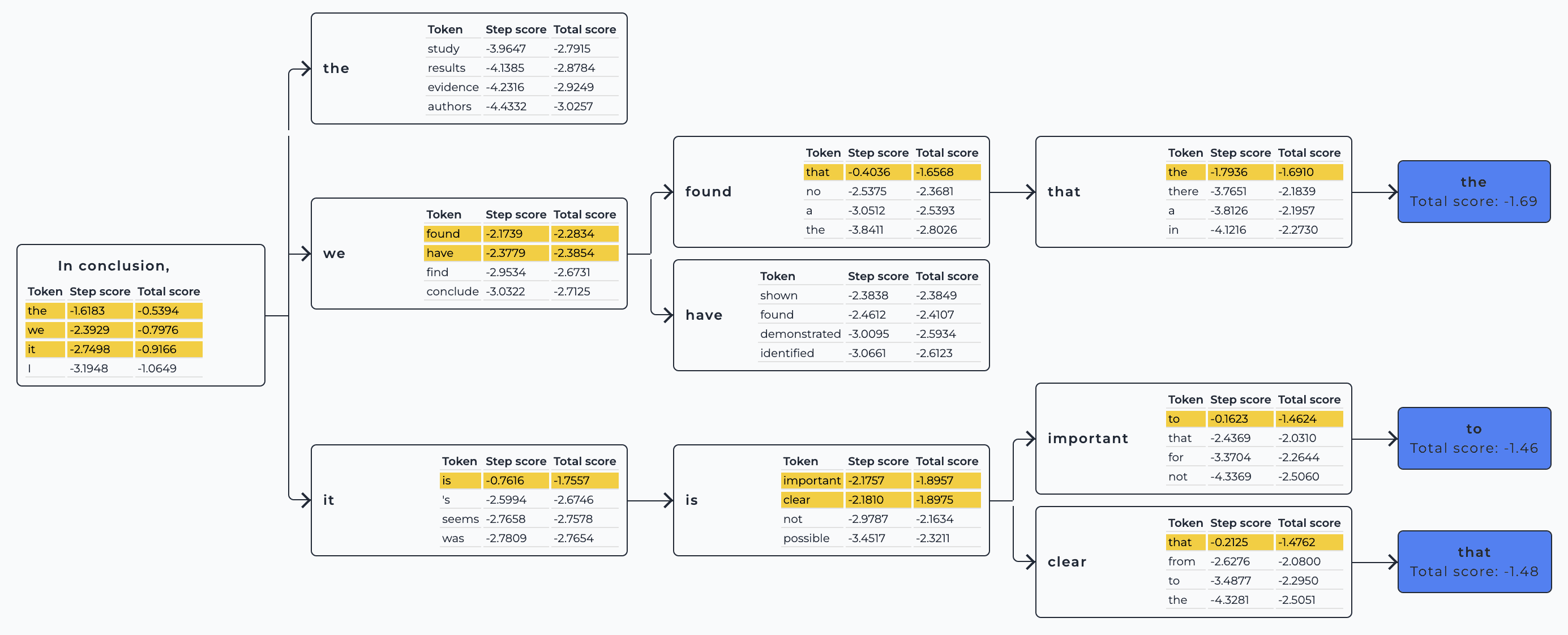
交互式演示: https://huggingface.co/spaces/m-ric/beam_search_visualizer
要启用此解码策略,请指定大于 1 的num_beams (也称为要跟踪的假设数)
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "It is astonishing how one can"
checkpoint = "openai-community/gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
Beam-search multinomial sampling¶
这种解码策略将波束搜索与多项式采样相结合。
指定num_beams大于 1,并设置do_sample=True才能使用此解码策略。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
set_seed(0) # For reproducibility
prompt = "translate English to German: The house is wonderful."
checkpoint = "google-t5/t5-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, do_sample=True)
tokenizer.decode(outputs[0], skip_special_tokens=True)
Diverse beam search decoding¶
多样化波束搜索解码策略是波束搜索策略的扩展,允许生成更多样化的波束序列集以供选择。
工作原理,请参阅Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models: https://arxiv.org/pdf/1610.02424.pdf
该方法具有三个主要参数:
num_beams、num_beam_groups和diversity_penalty多样性惩罚确保输出在组之间是不同的,并且在每个组内使用波束搜索。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
checkpoint = "google/pegasus-xsum"
prompt = (
"The Permaculture Design Principles are a set of universal design principles "
...
"efficient way possible."
)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
tokenizer.decode(outputs[0], skip_special_tokens=True)
Speculative Decoding¶
推测解码(也称为辅助解码)是上述解码策略的一种修改,它使用辅助模型(最好是更小的模型)来生成一些候选标记。
然后,主模型在一次前向传递中验证候选标记,从而加快解码过程。
如果do_sample=True ,则使用推测解码论文中引入的带有重采样的令牌验证。
辅助解码假设主模型和辅助模型具有相同的分词器,否则,请参阅下面的通用辅助解码。
目前辅助解码仅支持贪婪搜索和采样,辅助解码不支持批量输入。
要了解有关辅助解码的更多信息,请查看此博客文章: https://huggingface.co/blog/assisted-generation
要启用辅助解码,请使用模型设置assistant_model参数。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
outputs = model.generate(**inputs, assistant_model=assistant_model)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
Universal Assisted Decoding¶
通用辅助解码 (UAD) 添加了对具有不同标记器的主模型和辅助模型的支持。
要使用它,只需使用tokenizer和assistant_tokenizer参数传递标记器(见下文)。
在内部,主模型输入标记被重新编码为辅助模型标记,然后在辅助编码中生成候选标记,这些候选标记又被重新编码为主模型候选标记。然后验证按照上面的解释进行。重新编码步骤涉及将令牌 ID 解码为文本,然后使用不同的令牌生成器对文本进行编码。由于重新编码令牌可能会导致令牌化差异,因此 UAD 会找到源编码和目标编码之间的最长公共子序列,以确保新令牌包含正确的提示后缀。
如果主模型和辅助模型具有不同的标记器,请使用通用辅助解码。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
assistant_tokenizer = AutoTokenizer.from_pretrained(assistant_checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
outputs = model.generate(**inputs, assistant_model=assistant_model, tokenizer=tokenizer, assistant_tokenizer=assistant_tokenizer)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
DoLa Decoding¶
Decoding by Contrasting Layers (DoLa) 是一种对比解码策略,旨在提高事实性并减少LLMs的幻觉
如 ICLR 2024 DoLa 的论文所述:Decoding by Contrasting Layers Improves Factuality in Large Language Models: https://arxiv.org/abs/2309.03883
DoLa 是通过对比最终层与早期层获得的 logits 差异来实现的,从而放大了变压器层特定部分的事实知识。
备注
更详细的再细看吗
Best Practices for Generation with Cache¶
What is Cache and why we should care¶
KV Cache
模型一次只能生成一个token,并且每个新预测都取决于先前的上下文
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
# 输出
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
这意味着,要在 Generation 中预测编号为 1000 的token,您需要来自之前 999 个token的信息,这些信息以 token 形式的矩阵乘法计算。
但是要预测令牌编号 1001,您还需要前 999 个令牌中的相同信息,以及令牌编号 1000 中的附加信息。
这就是使用键值缓存(KV Cache)来优化顺序生成过程的地方,方法是存储先前的计算以便在后续中重用令牌,因此不需要再次计算它们。
备注
请注意,缓存只能在推理中使用,并且在训练时应禁用,否则可能会导致意外错误。
Generate with Cache¶
默认情况下,所有模型都使用缓存生成,其中〜DynamicCache类是大多数模型的默认缓存。
如果由于某种原因您不想使用缓存,则可以将use_cache=False传递到generate()方法中。
缓存类可以在生成时使用cache_implementation参数进行设置。
Quantized Cache¶
键和值缓存会占用很大一部分内存,成为长上下文生成的瓶颈,特别是对于大型语言模型。
使用generate()时使用量化缓存可以显着减少内存需求,但代价是速度。
transformers中的
KV Cache量化很大程度上受到此论文启发: KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache: https://arxiv.org/abs/2402.02750如果您使用quanto后端,建议将缓存配置中的axis-key/axis-value参数设置为0;如果您使用HQQ后端,建议将其设置为1 。对于其他配置值,请使用默认值
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"nbits": 4, "backend": "quanto"})
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
out = model.generate(**inputs, do_sample=False, max_new_tokens=20)
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
Offloaded Cache¶
与 KV 缓存量化类似, ~OffloadedCache策略旨在减少 GPU VRAM 使用。
它通过将大多数层的 KV 缓存移至 CPU 来实现这一点。
当模型的forward()方法迭代各层时,该策略会在GPU上维护当前层缓存。同时,它异步预取下一层缓存,并将上一层缓存发送回 CPU。
与 KV 缓存量化不同,此策略始终产生与默认 KV 缓存实现相同的结果。因此,它可以作为它的直接替代品或后备方案。
备注
Cache offloading 需要 GPU,并且可能比 dynamic KV cache 慢。如果您遇到 CUDA 内存不足错误,请使用它。Cache offloading requires a GPU and can be slower than dynamic KV cache. Use it if you are getting CUDA out of memory errors.
示例-如何使用 KV 缓存卸载作为后备策略
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
def resilient_generate(model, *args, **kwargs):
oom = False
try:
return model.generate(*args, **kwargs)
except torch.cuda.OutOfMemoryError as e:
print(e)
print("retrying with cache_implementation='offloaded'")
oom = True
if oom: # 如果OOM,则启动后备策略
torch.cuda.empty_cache()
kwargs["cache_implementation"] = "offloaded"
return model.generate(*args, **kwargs)
>>> ckpt = "microsoft/Phi-3-mini-4k-instruct"
>>> tokenizer = AutoTokenizer.from_pretrained(ckpt)
>>> model = AutoModelForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16).to("cuda:0")
>>> prompt = ["okay "*1000 + "Fun fact: The most"]
>>> inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
>>> beams = { "num_beams": 40, "num_beam_groups": 40, "num_return_sequences": 40, "diversity_penalty": 1.0, "max_new_tokens": 23, "early_stopping": True, }
>>> out = resilient_generate(model, **inputs, **beams)
>>> responses = tokenizer.batch_decode(out[:,-28:], skip_special_tokens=True)
Static Cache¶
由于“DynamicCache”随着每个生成步骤动态增长,因此它会阻止您利用 JIT 优化。
~StaticCache为键和值预先分配特定的最大大小,允许您生成最大长度而无需修改缓存大小。
有关静态缓存和 JIT 编译的更多示例,请查看StaticCache & torchcompile: https://huggingface.co/docs/transformers/main/en/llm_optims#static-kv-cache-and-torchcompile
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="auto")
inputs = tokenizer("Hello, my name is", return_tensors="pt").to(model.device)
# simply pass the cache implementation="static"
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="static")
tokenizer.batch_decode(out, skip_special_tokens=True)[0]
Offloaded Static Cache¶
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="auto")
inputs = tokenizer("Hello, my name is", return_tensors="pt").to(model.device)
# simply pass the cache implementation="static"
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="offloaded_static")
tokenizer.batch_decode(out, skip_special_tokens=True)[0]
Sliding Window Cache¶
警告
注意,您只能将此缓存用于支持滑动窗口的模型,例如 Mistral 模型。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, SinkCache
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16).to("cuda:0")
inputs = tokenizer("Yesterday I was on a rock concert and.", return_tensors="pt").to(model.device)
# can be used by passing in cache implementation
out = model.generate(**inputs, do_sample=False, max_new_tokens=30, cache_implementation="sliding_window")
tokenizer.batch_decode(out, skip_special_tokens=True)[0]
Sink Cache¶
论文: Efficient Streaming Language Models with Attention Sinks: https://arxiv.org/abs/2309.17453
允许您生成长文本序列(根据论文“无限长度”),无需任何微调。这是通过智能处理以前的键和值来实现的,特别是它保留了序列中的一些初始标记,称为“接收器标记”。这是基于这样的观察:这些初始令牌在生成过程中吸引了很大一部分注意力分数。 “接收器令牌”之后的令牌将在滑动窗口的基础上被丢弃,仅保留最新的window_size令牌。通过将这些初始标记保留为“注意力池”,即使在处理很长的文本时,模型也能保持稳定的性能,从而丢弃大部分先前的知识。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, SinkCache
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
inputs = tokenizer("This is a long story about unicorns, fairies and magic.", return_tensors="pt").to(model.device)
# get our cache, specify number of sink tokens and window size
# Note that window size already includes sink tokens, so has to be larger
past_key_values = SinkCache(window_length=256, num_sink_tokens=4)
out = model.generate(**inputs, do_sample=False, max_new_tokens=30, past_key_values=past_key_values)
tokenizer.batch_decode(out, skip_special_tokens=True)[0]
备注
与其他缓存类不同,这个缓存类不能通过指示cache_implementation来直接使用。您必须在调用generate()之前初始化缓存
Encoder-Decoder Cache¶
~EncoderDecoderCache是一个包装器,旨在处理编码器-解码器模型的缓存需求。这种缓存类型是专门为管理自注意力和交叉注意力缓存而构建的,确保存储和检索这些复杂模型所需的过去的键/值。
Model-specific Cache Classes¶
有些模型需要以特定的方式存储以前的键、值或状态,并且不能使用上述缓存类。对于这种情况,我们有几个专为特定模型设计的专用缓存类。
示例包括用于Gemma2系列模型的~HybridCache或用于Mamba架构模型的~MambaCache 。
Prompting¶
Image tasks with IDEFICS¶
对于把图像先转为文本再进行分析的LLM,这种图像类的task也可以像普通的语言LLM一样使用prompt
LLM prompting guide¶
编码器-解码器式模型通常用于输出严重依赖输入的生成任务,例如翻译和摘要。仅解码器模型用于所有其他类型的生成任务。
具体看prompt相关文档
Developer guides¶
Use fast tokenizers from 🤗 Tokenizers¶
PreTrainedTokenizer:这是一个纯 Python 实现的分词器基类,所有的分词和编码操作都是通过 Python 代码执行的。
PreTrainedTokenizerFast:基于 Rust 编写的 🤗 Tokenizers 库,实现了更高效的分词算法。PreTrainedTokenizerFast 通过绑定 Rust 实现,提供了更快的分词速度。
需要注意的是,并非所有模型的分词器都有对应的 “Fast” 实现,特别是基于 SentencePiece 的分词器(如 T5、ALBERT、CamemBERT、XLMRoBERTa 和 XLNet 等模型)目前尚无 “Fast” 版本可用
创建一个虚拟分词器(dummy tokenizer)
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tokenizer.pre_tokenizer = Whitespace()
files = [...]
tokenizer.train(files, trainer)
# 保存
tokenizer.save("tokenizer.json")
Loading directly from the tokenizer object¶
from transformers import PreTrainedTokenizerFast
fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
Loading from a JSON file¶
from transformers import PreTrainedTokenizerFast
fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
Use model-specific APIs¶
Create a custom architecture
AutoClass自动推断模型架构并下载预训练的配置和权重。一般来说,我们 建议 使用AutoClass来生成与检查点无关的代码。
本节主要了解如何创建不使用AutoClass自定义模型
Configuration¶
Configuration 指模型的特定属性。每个模型配置都有不同的属性
示例
DistilBertConfigdisplays all the default attributes used to build a baseDistilBertModel
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
所有属性均可定制,如下示例
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu", # gelu->relu
"attention_dropout": 0.4, # 0.1->0.4
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
保存&加载:
my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
# 保存
my_config.save_pretrained(save_directory="./your_model_save_path")
# 加载
my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
Model¶
加载:
# 将自定义配置属性加载到模型中
# 这将创建一个具有随机值而不是预训练权重的模型
# 注意:在训练该模型之前,您还无法将该模型用于任何有用的事情
from transformers import DistilBertModel
my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
model = DistilBertModel(my_config)
# 自动加载默认模型配置的预训练模型
model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
# 使用自己的模型配置属性
model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
Model heads¶
At this point, you have a base
DistilBERTmodel which outputs thehidden states.The
hidden statesare passed as inputs to amodel headto produce the final output.🤗 Transformers provides a different model head for each task as long as a model supports the task
(i.e., you can’t use DistilBERT for a sequence-to-sequence task like translation).
示例
DistilBertForSequenceClassificationis a baseDistilBERTmodel with asequence classificationhead.The sequence classification head is a linear layer on top of the
pooled outputs.
from transformers import DistilBertForSequenceClassification
model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
通过切换到不同的 model head,可以轻松地将此checkpoint重复用于其他任务。
对于问答任务,您将使用
DistilBertForQuestionAnswering模型头(model head)。The
question answering headis similar to thesequence classification headexcept it is a linear layer on top of thehidden states output.
from transformers import DistilBertForQuestionAnswering
model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
Tokenizer¶
PreTrainedTokenizer :分词器的 Python 实现。
PreTrainedTokenizerFast :来自我们基于 Rust 的🤗 Tokenizer库的 tokenizer。
警告
并非每个模型都支持快速分词器。查看此 表 以检查模型是否具有快速分词器支持。
如果您想训练自己的分词器,则可以从词汇表文件创建一个分词器:
from transformers import DistilBertTokenizer
my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
创建具有预训练模型词汇表的分词器:
from transformers import DistilBertTokenizer
slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
# fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
备注
By default, AutoTokenizer will try to load a fast tokenizer. You can disable this behavior by setting use_fast=False in from_pretrained.
Image processor¶
todo
图像处理器处理视觉输入。它继承自ImageProcessingMixin基类。
Backbone¶
todo
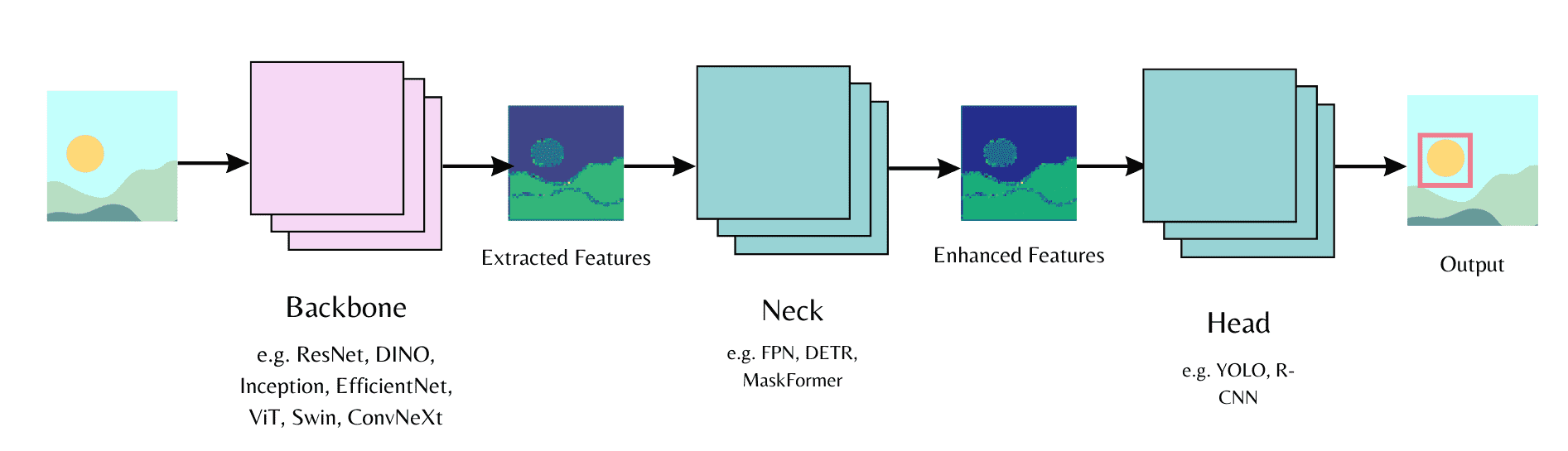
Computer vision models consist of a backbone, neck, and head.¶
backbone 从输入图像中提取特征, neck 组合并增强提取的特征, head 用于主要任务(例如,对象检测)。
首先在模型配置中初始化主干,并指定是否要加载预训练的权重或加载随机初始化的权重。然后您可以将模型配置传递给模型头。
The backbone extracts features from an input image, the neck combines and enhances the extracted features, and the head is used for the main task (e.g., object detection).
Start by initializing a backbone in the model config and specify whether you want to load pretrained weights or load randomly initialized weights. Then you can pass the model config to the model head.
Feature extractor¶
todo
继承自FeatureExtractionMixin基类,也可以继承SequenceFeatureExtractor类来处理音频输入。
Processor¶
todo
对于支持多模式任务的模型,🤗 Transformers 提供了一个处理器类,可以方便地将特征提取器和分词器等处理类包装到单个对象中。
Building custom models¶
讲了如何自己写一个自定义模型
讲了AutoXXX如何实现加载模型的
Chat Templates¶
Introduce¶
An increasingly common use case for LLMs is chat.
在聊天上下文中,该模型不是继续单个文本字符串(如标准语言模型的情况),而是继续由一条或多条消息组成的对话,每条消息都包含一个角色,例如“user”或“assists”,以及消息文本。
与标记化(tokenization)非常相似,不同的模型期望聊天的输入格式截然不同。这就是我们添加聊天模板作为一项功能的原因。
聊天模板是标记器(tokenizer)的一部分。它们指定如何将表示为消息列表的对话转换为模型期望格式的单个可标记字符串。
示例:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
tokenizer.apply_chat_template(chat, tokenize=False)
# 注: 标记 [INST] 和 [/INST] 来指示用户消息的开始和结束
# 其他模型可能使用别的标记来指示
How do I use chat templates¶
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
# 输出
"""
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
"""
模型输出:
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
# 输出
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
Matey, I'm afraid I must .......
核心参数¶
add_generation_prompt 参数¶
类型:bool
功能:是否在聊天模板的末尾添加一个提示,用于指示模型生成下一条消息。这对于一些聊天模型至关重要,因为它们需要一个特定的触发标记来开始生成。
实例:
messages = [
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "Can I ask a question?"}
]
without a generation prompt::
>>> tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
"""
with a generation prompt:
>>> tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant # 添加生成提示
"""
continue_final_message 参数¶
类型:bool
功能:是否在最后一条消息的 content 末尾继续生成。这在需要模型接着未完成的句子生成时很有用。
chat = [
{"role": "user", "content": "Can you format the answer in JSON?"},
{"role": "assistant", "content": '{"name": "'},
]
formatted_chat = tokenizer.apply_chat_template(chat, tokenize=True, return_dict=True, continue_final_message=True)
model.generate(**formatted_chat)
备注
add_generation_prompt添加开始新消息的标记,而continue_final_message从最终消息中删除任何消息结束标记,因此将它们一起使用没有意义。
tokenize 参数¶
备注
默认情况下,某些标记生成器会将特殊标记(如<bos>和<eos>添加到它们标记的文本中。聊天模板应该已经包含它们需要的所有特殊标记,因此额外的特殊标记通常会不正确或重复,这会损害模型性能。
如果您使用以下格式设置文本格式 apply_chat_template(tokenize=False) ,当您稍后标记该文本时,您应该设置参数add_special_tokens=False 。如果你使用 apply_chat_template(tokenize=True) ,你不需要担心这个!
Advanced: How do chat templates work?¶
模型的聊天模板存储在tokenizer.chat_template属性中
示例(Jinja 模板):
{%- for message in messages %}
{{- '<|' + message['role'] + |>\n' }}
{{- message['content'] + eos_token }}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|assistant|>\n' }}
{%- endif %}
示例2:
{%- for message in messages %}
{%- if message['role'] == 'user' %}
{{- bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{%- elif message['role'] == 'system' %}
{{- '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
{%- elif message['role'] == 'assistant' %}
{{- ' ' + message['content'] + ' ' + eos_token }}
{%- endif %}
{%- endfor %}
Advanced: Adding and editing chat templates¶
How do I create a chat template?¶
基于别的token进行修改:
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
一种流行的选择是ChatML格式:
{%- for message in messages %}
{{- '<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n' }}
{%- endfor %}
Advanced: Template writing tips¶
Trimming whitespace¶
强烈建议使用格式:
{%- for message in messages %}
{{- message['role'] + message['content'] }}
{%- endfor %}
不要使用格式:
{% for message in messages %}
{{ message['role'] + message['content'] }}
{% endfor %}
Callable functions¶
1. raise_exception(msg)
2. strftime_now(format_str)
Compatibility with non-Python Jinja¶
备注
非 Python 实现在部署环境中尤其常见,其中 JS 和 Rust 非常流行。
1.Replace Python methods with Jinja filters:
string.lower() => string|lower dict.items() => dict|items string.strip() => string|trim
2.Replace True, False and None, which are Python-specific, with true, false and none.
3.添加tojson过滤器, 避免直接渲染字典或列表可能会在其他实现中给出不同的结果
Jinja内置Filter: https://jinja.palletsprojects.com/en/3.1.x/templates/#builtin-filters
Trainer¶
Basic usage:
1. perform a training step to calculate the loss(执行训练步骤来计算损失)
2. calculate the gradients with the backward method(使用后向方法计算梯度)
3. update the weights based on the gradients(根据梯度更新权重)
4. repeat this process until you’ve reached a predetermined number of epochs(重复此过程,直到达到预定epochs)
class:
Trainer
Seq2SeqTrainer
trl.SFTTrainer
TrainingArguments class:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="your-model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
Export to ONNX¶
🤗 Optimum 是 Transformers 的扩展,可以通过其exporters模块将模型从 PyTorch 导出为序列化格式(serialized format),例如 ONNX 和 TFLite。
ONNX(Open Neural Network eXchange)是一种开放标准,定义了一组通用运算符和通用文件格式,以表示各种框架(包括 PyTorch 和 TensorFlow)中的深度学习模型。当模型导出为 ONNX 格式时,这些运算符用于构建计算图(通常称为中间表示),该计算图表示通过神经网络的数据流。
通过使用标准化运算符和数据类型公开图表,ONNX 可以轻松地在框架之间切换。例如,在 PyTorch 中训练的模型可以导出为 ONNX 格式,然后导入到 TensorFlow 中(反之亦然)。
Exporting a 🤗 Transformers model to ONNX with CLI¶
要将 🤗 Transformers 模型导出到 ONNX,请首先安装额外的依赖项:
$ pip install optimum[exporters]
示例-导出:
# 从 🤗 Hub 导出模型的检查点
$ optimum-cli export onnx --model distilbert/distilbert distilbert/
# 导出本地模型
$ optimum-cli export onnx --model local_path --task question-answering distilbert/
使用ONNX Runtime加载并运行模型:
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("distilbert")
model = ORTModelForQuestionAnswering.from_pretrained("distilbert")
inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
outputs = model(**inputs)
Exporting a 🤗 Transformers model to ONNX with optimum.onnxruntime¶
示例-导出:
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer
model_checkpoint = "distilbert_base_uncased_squad"
save_directory = "onnx/"
# Load a model from transformers and export it to ONNX
ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
# Save the onnx model and tokenizer
ort_model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)
Exporting a model with transformers.onnx¶
警告
transformers.onnx不再维护,请使用上面2节的 🤗 Optimum 导出模型。此部分将在未来版本中删除。
示例-导出:
pip install transformers[onnx]
python -m transformers.onnx --model=distilbert/distilbert-base-uncased onnx/
示例-运行:
from transformers import AutoTokenizer
from onnxruntime import InferenceSession
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
session = InferenceSession("onnx/model.onnx")
# ONNX Runtime expects NumPy arrays as input
inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
FP16 stands for mixed-precision meaning that computations within the model are done using a mixture of 16-bit and 32-bit floating-point operations
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.half
Interoperability with GGUF files¶
The GGUF file format is used to store models for inference with GGML and other libraries that depend on it(如: llama.cpp or whisper.cpp)
它是Hugging Face Hub 支持的一种文件格式,具有允许快速检查文件中的张量(tensors)和元数据(metadata)的功能。
这种文件格式被设计为“单文件格式(single-file-format)”,其中单个文件通常包含配置属性(configuration attributes)、分词器词汇(tokenizer vocabulary)和其他属性,以及要在模型中加载的所有张量。
Supported quantization types:
F32
F16
BF16
Q4_0
Q4_1
Q5_0
Q5_1
Q8_0
Q2_K
Q3_K
Q4_K
Q5_K
Q6_K
IQ1_S
IQ1_M
IQ2_XXS
IQ2_XS
IQ2_S
IQ3_XXS
IQ3_S
IQ4_XS
IQ4_NL
Supported model architectures:
LLaMa
Mistral
Qwen2
Qwen2Moe
Phi3
Example:
# 加载 GGUF 文件格式
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
# 保存模型并将其导出回gguf
tokenizer.save_pretrained('directory')
model.save_pretrained('directory')
!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
Quantization Methods¶
备注
本节简单整理,需要时细看
Quantization¶
Quantization method:
bitsandbytes
GPTQ
AWQ
AQLM
Quanto
EETQ
HQQ
FBGEMM_FP8
Optimum
TorchAO
compressed-tensors
Contribute new quantization method
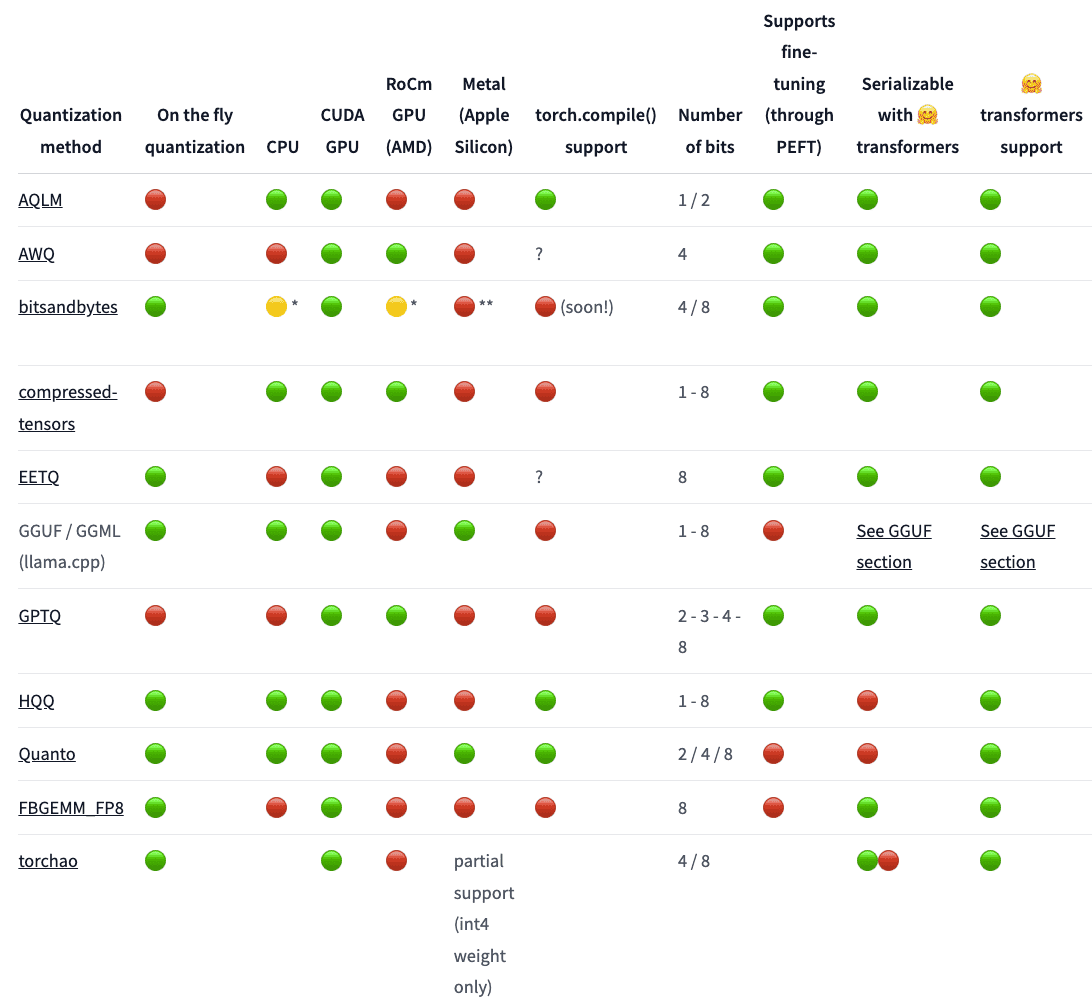
bitsandbytes¶
bitsandbytes is the easiest option for quantizing a model to 8 and 4-bit.
定义:异常值(Outliers)是指在数据集中明显偏离其他数据点的数值。它们与数据集的平均趋势或范围相比,表现得非常异常,可能由于测量错误、极端情况或数据分布中的稀有事件引起。
定义:非异常值(Non-Outliers)是指在数据集中符合总体趋势、范围或分布的数值。它们不会明显偏离数据的主流特征,通常位于数据的平均值附近。
在机器学习中的表现:在神经网络中,某些权重或激活值可能非常大或非常小(相对于其他值),这些值会被称为异常值(Outliers)。如果直接使用低精度(如8-bit)的量化,异常值可能导致较大的精度损失。
处理方式:在8-bit量化过程中,异常值往往不会直接量化为8位整数,因为这样会导致精度损失。通常,这些异常值会保留在更高精度的格式(如FP16)中单独处理。
【量化过程中的作用】在量化神经网络时,outliers 和 non-outliers 被分开处理。非异常值适合直接用8-bit表示,能极大地减少计算和存储的资源需求。而异常值因为可能导致精度损失,通常用更高精度的FP16表示。随后,将这两部分(FP16的异常值和INT8的非异常值)相乘、加总,以保持计算结果的精确性。
备注
通过这种方法,既能利用低精度量化的优势(减少模型大小和加速推理),又能在处理异常值时保持一定的精度。
8 位量化将 fp16 中的异常值(outliers)与 int8 中的非异常值(non-outliers)相乘,将非异常值转换回 fp16,然后将它们相加以返回 fp16 中的权重。这减少了异常值对模型性能的影响。
8-bit quantization multiplies outliers in fp16 with non-outliers in int8, converts the non-outlier values back to fp16, and then adds them together to return the weights in fp16.
4 位量化可以进一步压缩模型,通常与QLoRA一起使用来微调量化的LLMs 。
8bit:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
quantization_config=quantization_config
)
4bit:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
quantization_config=quantization_config
)
GPTQ¶
AutoGPTQ库实现了 GPTQ 算法,这是一种训练后量化技术,其中权重矩阵的每一行都被独立量化,以找到最小化误差的权重版本。
这些权重被量化为 int4,但在推理过程中会即时恢复为 fp16。
These weights are quantized to int4, but they’re restored to fp16 on the fly during inference.
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
# 设置device_map="auto"可自动将模型卸载到 CPU,以帮助将模型放入内存中,并允许模型模块在 CPU 和 GPU 之间移动以进行量化。
ExLlama¶
ExLlama是Llama模型的 Python/C++/CUDA 实现,旨在使用 4 位 GPTQ 权重进行更快的推理
import torch
from transformers import AutoModelForCausalLM, GPTQConfig
gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
仅当整个模型位于 GPU 上时才支持 ExLlama 内核。如果您使用 AutoGPTQ(版本 > 0.4.2)在 CPU 上进行推理,则需要禁用 ExLlama 内核:
import torch
from transformers import AutoModelForCausalLM, GPTQConfig
gptq_config = GPTQConfig(bits=4, use_exllama=False)
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="cpu", quantization_config=gptq_config)
AWQ¶
Activation-aware Weight Quantization(AWQ): https://hf.co/papers/2306.00978
不会量化模型中的所有权重,而是保留对LLM性能很重要的一小部分权重。这显着减少了量化损失,以便您可以以 4 位精度运行模型,而不会出现任何性能下降。
通过对模型的权重进行加权平均处理,能够更精确地捕捉权重分布的特点。AWQ在保留模型性能的同时,能够显著减少推理时的内存使用和计算复杂度。一种改进的量化方法,它针对神经网络的权重分布特点,通过加权平均的方式量化参数,从而更好地保留了模型的精度。在推理时,AWQ 可以使用低精度的权重表示,减少存储和计算的成本,同时保持模型性能的稳定。与传统的量化技术(如直接的逐层或逐通道量化)相比,AWQ 对权重分布的处理更加精细,因此在同等量化精度下能够获得更好的推理结果。(🈳from LLM)
有几个用于使用 AWQ 算法量化模型的库,例如
autoawq: https://github.com/casper-hansen/AutoAWQ>
optimization-intel:
Fused modules:
import torch
from transformers import AwqConfig, AutoModelForCausalLM
model_id = "TheBloke/Mistral-7B-OpenOrca-AWQ"
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512,
do_fuse=True,
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
AQLM¶
Additive Quantization of Language Models (AQLM): 一种大型语言模型压缩方法。它将多个权重一起量化并利用它们之间的相互依赖性。 AQLM 将 8-16 个权重组表示为多个矢量代码的总和。
from transformers import AutoTokenizer, AutoModelForCausalLM
quantized_model = AutoModelForCausalLM.from_pretrained(
"ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("ISTA-DASLab/Mixtral-8x7b-AQLM-2Bit-1x16-hf")
Quanto¶
Quanto库是一个多功能的 pytorch 量化工具包。使用的量化方法是线性量化
EETQ¶
EETQ库支持 NVIDIA GPUS 的 int8 每通道仅权重量化。
高性能GEMM和GEMV内核来自FasterTransformer和TensorRT- LLM 。
它不需要校准数据集,也不需要预先量化您的模型。此外,由于每通道量化,精度下降可以忽略不计。
HQQ¶
Half-Quadratic Quantization (HQQ): 通过快速鲁棒优化(fast robust optimization)实现动态量化(on-the-fly quantization)。
它不需要校准数据,可用于量化任何模型。
FBGEMM FP8¶
the weights will be quantized in 8bit (FP8) per channel
the activation will be quantized in 8bit (FP8) per token
Optimum¶
Optimum库支持 Intel、Furiosa、ONNX Runtime、GPTQ 和较低级别 PyTorch 量化函数的量化。
如果您使用特定的优化硬件(例如 Intel CPU、Furiosa NPU 或 ONNX Runtime 等模型加速器),请考虑使用 Optimum 进行量化。
TorchAO¶
TorchAO是 PyTorch 的架构优化库,它提供了用于推理和训练的高性能数据类型、优化技术和内核,具有与torch.compile 、 FSDP 等原生 PyTorch 功能的可组合性。
Compressed Tensors¶
提供了一种通用且有效的方法来存储和管理压缩模型检查点。
该库支持各种量化和稀疏方案,使其成为处理不同模型优化的统一格式,例如 GPTQ、AWQ、SmoothQuant、INT8、FP8、SparseGPT 等。
Performance and scalability¶
LLM inference optimization¶
Static kv-cache and torch.compile¶
使用 kv-cache 来存储过去的键和值,而不是每次都重新计算它们。
然而,由于 kv-cache 在每个生成步骤都是动态且变化的,因此它会阻止您利用 torch.compile ,这是一个功能强大的优化工具,可将 PyTorch 代码融合到快速且优化的内核中。
kv-cache 的完整指南: 参见上面的
Best Practices for Generation with Cachestatic kv-cache 通过将 kv-cache 大小预先分配为最大值来解决此问题,这允许您将其与torch.compile结合使用,最高可提高 4 倍的速度。目前,只有Llama和其他一些模型支持 static kv-cache 和torch.compile 。
静态 kv 缓存的使用分为三种类型,具体取决于任务的复杂性:
1. Basic usage: simply set a flag in generation_config (recommended);
2. Advanced usage: handle a cache object for multi-turn generation or a custom generation loop;
3. Advanced usage: compile the entire generate function into a single graph, if having a single graph is relevant for you.
Speculative decoding¶
推测解码
深入参见博客文章: Assisted Generation: a new direction toward low-latency text generation: https://hf.co/blog/assisted-generation
自回归的另一个问题是,对于每个输入标记,您需要在前向传递过程中每次加载模型权重。
对于拥有数十亿参数的LLMs来说,这既缓慢又麻烦。推测性解码通过使用第二个更小、更快的辅助模型来生成候选标记,并在单次前向传递中由更大的LLM进行验证,从而缓解了这种速度下降的情况。
如果验证的令牌是正确的, LLM基本上可以“免费”获得它们,而不必自己生成它们。
Prompt lookup decoding¶
Prompt lookup decoding 是推测解码的一种变体
提示查找对于基于输入的任务(例如摘要)特别有效,其中提示和输出之间经常存在重叠的单词。这些重叠的 n 元语法被用作LLM候选token。
Attention optimizations¶
Transformer 模型的一个已知问题是,自注意力机制在计算和内存中随着输入标记的数量呈二次方增长。
这种限制会在处理更长序列的LLMs中被放大。
为了解决这个问题,请尝试 FlashAttention2 或 PyTorch 的缩放点积注意力 (scaled dot product attention, SDPA),它们是内存效率更高的注意力实现,可以加速推理。
FlashAttention-2¶
FlashAttention 和FlashAttention-2将注意力计算分解为更小的块,并减少对 GPU 内存的中间读/写操作的数量,以加快推理速度。
FlashAttention-2 通过在序列长度维度上并行化以及更好的硬件分区工作来改进原始 FlashAttention 算法,以减少同步和通信开销。
PyTorch scaled dot product attention¶
PyTorch 2.0 中自动启用了缩放点积注意力 (SDPA),它支持 FlashAttention、xFormers 和 PyTorch 的 C++ 实现。
如果您使用 CUDA 后端,SDPA 会选择性能最佳的注意力算法。对于其他后端,SDPA 默认使用 PyTorch C++ 实现。
只要您安装了最新的 PyTorch 版本,SDPA 就支持 FlashAttention-2。
Quantization¶
如果您不受 GPU 的限制,则不一定需要量化模型,因为量化和反量化权重所需的额外步骤可能会产生较小的延迟成本(AWQ 和融合 AWQ 模块除外)。
Efficient training techniques¶
Methods and tools for efficient training on a single GPU¶
在训练大型模型时,需要同时考虑两个方面:
1. Data throughput/training time 数据吞吐量/训练时间
2. Model performance 模型性能
Method/tool与对应的效果:
+----------------------------------------+-------------------------+------------------------------+
| Method/tool | Improves training speed | Optimizes memory utilization |
+========================================+=========================+==============================+
| Batch size choice | Yes | Yes |
+----------------------------------------+-------------------------+------------------------------+
| Gradient accumulation | No | Yes |
+----------------------------------------+-------------------------+------------------------------+
| Gradient checkpointing | No | Yes |
+----------------------------------------+-------------------------+------------------------------+
| Mixed precision training | Yes | Maybe* |
+----------------------------------------+-------------------------+------------------------------+
| torch_empty_cache_steps | No | Yes |
+----------------------------------------+-------------------------+------------------------------+
| Optimizer choice | Yes | Yes |
+----------------------------------------+-------------------------+------------------------------+
| Data preloading | Yes | No |
+----------------------------------------+-------------------------+------------------------------+
| DeepSpeed Zero | No | Yes |
+----------------------------------------+-------------------------+------------------------------+
| torch.compile | Yes | No |
+----------------------------------------+-------------------------+------------------------------+
| Parameter-Efficient Fine Tuning (PEFT) | No | Yes |
+----------------------------------------+-------------------------+------------------------------+
Batch size choice¶
为了实现最佳性能,首先要确定适当的批量大小。建议使用大小为 2^N 的批量大小和输入/输出神经元计数。通常它是 8 的倍数,但也可能更高,具体取决于所使用的硬件和模型的数据类型。
作为参考,请查看 NVIDIA 对于全连接层(涉及 GEMM(通用矩阵乘法))的 输入/输出神经元计数 和 批量大小 的建议。
For reference, check out NVIDIA’s recommendation for input/output neuron counts and batch size for fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
张量核心要求根据数据类型和硬件定义乘数。例如,对于 fp16 数据类型,建议使用 8 的倍数,除非是 A100 GPU,在这种情况下使用 64 的倍数。
Gradient Accumulation¶
梯度累积方法旨在以较小的增量计算梯度,而不是一次计算整个批次的梯度。
这种方法涉及通过向前和向后遍历模型并在此过程中累积梯度来迭代计算较小批次的梯度。一旦积累了足够数量的梯度,就会执行模型的优化步骤。
通过采用梯度累积,可以将有效批量大小(effective batch size)增加到超出 GPU 内存容量的限制。
然而,值得注意的是,梯度累积引入的额外前向和后向传递可能会减慢训练过程。
示例:
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
# 说明
1. 通过将gradient_accumulation_steps参数添加到TrainingArguments来启用梯度累积
2. 有效批量大小变为 4
Gradient Checkpointing¶
即使批量大小设置为 1 并使用梯度累积,一些大型模型仍然可能面临内存问题。这是因为还有其他组件也需要内存存储。
保存前向传递中的所有激活以便在后向传递期间计算梯度可能会导致显着的内存开销。另一种方法是在向后传递过程中丢弃激活并在需要时重新计算它们,这会带来相当大的计算开销并减慢训练过程。
梯度检查点 提供了这两种方法之间的折衷方案,并在整个计算图中保存了战略选择的激活,因此只需为梯度重新计算一小部分激活。有关梯度检查点的深入解释,请参阅这篇 精彩文章
示例:
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
Mixed precision training¶
混合精度训练 是一种旨在通过对某些变量使用较低精度的数值格式来优化训练模型的计算效率的技术。传统上,大多数模型使用 32 位浮点精度(fp32 或 float32)来表示和处理变量。然而,并非所有变量都需要如此高精度才能获得准确的结果。通过将某些变量的精度降低为较低的数值格式,例如 16 位浮点(fp16 或 float16),我们可以加快计算速度。由于在这种方法中,有些计算是以半精度执行的,而有些计算仍然是全精度的,因此该方法称为混合精度训练。
最常见的混合精度训练是通过使用 fp16 (float16) 数据类型来实现的,但是,一些 GPU 架构(例如 Ampere 架构)提供 bf16 和 tf32(CUDA 内部数据类型)数据类型。查看 NVIDIA博客
fp16¶
混合精度训练的主要优点来自于以半精度(fp16)保存激活。尽管梯度也是以半精度计算的,但它们在优化步骤中会转换回全精度,因此此处不会节省内存。
虽然混合精度训练可以加快计算速度,但它也会导致使用更多 GPU 内存,特别是对于小批量大小。这是因为该模型现在以 16 位和 32 位精度(GPU 上原始模型的 1.5 倍)呈现在 GPU 上。
要启用混合精度训练,请将fp16标志设置为True:
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
BF16¶
如果您可以使用 Ampere 或更新的硬件,则可以使用 bf16 进行混合精度训练和评估。
虽然 bf16 的精度比 fp16 差,但它的动态范围要大得多。在 fp16 中,您可以拥有的最大数字是65504 ,任何高于该数字的数字都会导致溢出。 bf16 数字可以大到3.39e+38 (!),这与 fp32 大致相同 - 因为两者都有 8 位用于数字范围。
在 🤗 Trainer 中启用 BF16:
training_args = TrainingArguments(bf16=True, **default_args)
TF32¶
Ampere 硬件使用一种名为 tf32 的神奇数据类型。
它具有与 fp32(8 位)相同的数值范围,但不是 23 位精度,而是只有 10 位(与 fp16 相同),并且总共只使用 19 位。
它的“神奇”之处在于,您可以使用普通的 fp32 训练和/或推理代码,并且通过启用 tf32 支持,您可以获得高达 3 倍的吞吐量提升。
您需要做的就是将以下内容添加到您的代码中:
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
示例:
TrainingArguments(tf32=True, **default_args)
备注
tf32 无法直接通过tensor.to(dtype=torch.tf32)访问,因为它是内部 CUDA 数据类型。您需要torch>=1.7才能使用 tf32 数据类型。
Flash Attention 2¶
可以通过在 Transformer 中使用 Flash Attention 2 集成来加速训练吞吐量
具体参见后面的推理优化(Optimizing inference)
Optimizer choice¶
用于训练 Transformer 模型的最常见优化器是 Adam 或 AdamW(带有权重衰减的 Adam)。
Adam通过存储之前梯度的滚动平均值实现了良好的收敛;然而,它增加了模型参数数量数量级的额外内存占用。为了解决这个问题,您可以使用替代优化器。例如,如果您为 NVIDIA GPU 安装了NVIDIA/apex ,或为 AMD GPU 安装了ROCmSoftwarePlatform/apex , adamw_apex_fused将为您提供所有受支持的 AdamW 优化器中最快的训练体验。
Trainer集成了各种可立即使用的优化器: adamw_hf 、 adamw_torch 、 adamw_torch_fused 、 adamw_apex_fused 、 adamw_anyprecision 、 adafactor或adamw_bnb_8bit 。可以通过第三方实现插入更多优化器。
Data preloading¶
默认情况下,一切都发生在主进程中,它可能无法足够快地从磁盘读取数据,从而产生瓶颈,导致 GPU 利用率不足
DeepSpeed ZeRO¶
DeepSpeed 是一个开源深度学习优化库,与 🤗 Transformers 和 🤗 Accelerate 集成。它提供了广泛的功能和优化,旨在提高大规模深度学习训练的效率和可扩展性。
如果您的模型适合单个 GPU 并且您有足够的空间来容纳小批量大小,则不需要使用 DeepSpeed,因为它只会减慢速度。
但是,如果模型不适合单个 GPU,或者您无法适应小批量,则可以利用 DeepSpeed ZeRO + CPU Offload 或 NVMe Offload 来处理更大的模型。
Using torch.compile¶
示例:
training_args = TrainingArguments(torch_compile=True, **default_args)
torch.compile uses Python’s frame evaluation API to automatically
create a graphfrom existing PyTorch programs. After capturing the graph,可以部署不同的后端来将图表降低到优化的引擎。create a graph: 通过 torch.compile 自动将现有的 PyTorch 程序转换成计算图(computation graph)
具体来说,PyTorch 通常是动态计算的(即动态图,也叫 eager execution),这意味着每个操作(如张量加法、矩阵乘法等)都会立即执行。
而 torch.compile 使用 Python 的 “frame evaluation API”,将这些动态的操作捕获下来,并将它们组合成一个优化后的静态计算图(static computation graph)。
这个计算图包含了整个模型的操作顺序和依赖关系,相当于一种高效的表达方式。通过将模型的操作变成图结构,后端可以对其进行优化和加速,利用硬件更好地执行这些操作,比如通过编译成更高效的代码或者在不同的硬件架构上执行。
因此,”create a graph” 的意思是:torch.compile 将原本按步骤执行的模型代码转换为一个可优化的图结构,便于进一步的性能优化。
最常用的后端:
1. Debugging backends:
dynamo.optimize("eager")
dynamo.optimize("aot_eager")
2. Training & inference backends:
dynamo.optimize("inductor")
dynamo.optimize("nvfuser")
dynamo.optimize("aot_nvfuser")
dynamo.optimize("aot_cudagraphs")
3. Inference-only backends:
dynamo.optimize("ofi")
dynamo.optimize("fx2trt")
dynamo.optimize("onnxrt")
dynamo.optimize("ipex")
有关将torch.compile与 🤗 Transformer 结合使用的示例,请查看这篇关于使用最新 PyTorch 2.0 功能微调用于文本分类的 BERT 模型的博客文章: https://www.philschmid.de/getting-started-pytorch-2-0-transformers
Using 🤗 PEFT¶
参数高效微调(PEFT)方法在微调期间冻结预训练的模型参数,并在其上添加少量可训练参数(适配器)。
As a result the memory associated to the
optimizer states and gradientsare greatly reduced.
对于普通 AdamW,优化器状态的内存要求为:
1. fp32 copy of parameters: 4 bytes/param
2. Momentum: 4 bytes/param
3. Variance: 4 bytes/param
一个7B的模型 and 200 million parameters injected with Low Rank Adapters
普通模型优化器状态的内存需求:
12 * 7 = 84 GB
添加 Lora 会稍微增加与模型权重相关的内存,但会将优化器状态的内存需求大幅降低至
12 * 0.2 = 2.4GB
Using 🤗 Accelerate¶
示例:
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
# 完整示例训练循环
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
Multiple GPUs and parallelism¶
采用多种技术来实现并行性,例如数据并行性、张量并行性和管道并行性。需要注意的是,没有一种万能的解决方案,最佳设置取决于您所使用的特定硬件配置。
Scalability strategy:
1. Parallelization strategy for a single Node / multi-GPU setup
Case 1: Your model fits onto a single GPU
DDP - Distributed DataParallel
Zero Redundancy Optimizer (ZeRO): https://arxiv.org/abs/1910.02054
Case 2: Your model doesn’t fit onto a single GPU:
PipelineParallel (PP)
ZeRO
TensorParallel (TP)
Case 3: Largest layer of your model does not fit onto a single GPU
If you are not using ZeRO, you have to use TensorParallel (TP), because PipelineParallel (PP) alone won’t be sufficient to accommodate the large layer.
If you are using ZeRO, additionally adopt techniques from the Methods and tools for efficient training on a single GPU.
2. Parallelization strategy for a multi Node / multi-GPU setup
When you have fast inter-node connectivity (e.g., NVLINK or NVSwitch) consider using one of these options:
ZeRO - as it requires close to no modifications to the model
A combination of PipelineParallel(PP) with TensorParallel(TP) and DataParallel(DP)
When you have slow inter-node connectivity and still low on GPU memory:
Employ a combination of DataParallel(DP) with PipelineParallel(PP), TensorParallel(TP), and ZeRO.
Fully Sharded Data Parallel¶
Fully Sharded Data Parallel (FSDP) : 完全分片数据并行 (FSDP)是一种数据并行方法,可将模型的参数、梯度和优化器状态分片到可用 GPU(也称为工作线程或等级)的数量上。
与DistributedDataParallel(DDP)不同,FSDP通过在每个GPU上进行模型分片而非完整复制,从而降低了内存使用。这提高了 GPU 内存效率,并允许您在更少的 GPU 上训练更大的模型。
Unlike DistributedDataParallel (DDP), FSDP reduces memory-usage because a model is replicated on each GPU. This improves GPU memory-efficiency and allows you to train much larger models on fewer GPUs.
FSDP is integrated with the Accelerate
DeepSpeed¶
DeepSpeed是一个 PyTorch 优化库,可提高分布式训练的内存效率和速度。其核心是零冗余优化器(ZeRO),它可以大规模训练大型模型。
Efficient Training on CPU¶
training_args = TrainingArguments(
output_dir=args.output_path,
+ bf16=True,
+ use_ipex=True,
+ use_cpu=True,
**kwargs
)
Distributed CPU training¶
基于 PyTorch 的 DDP支持进行分布式 CPU 训练
Optimizing inference¶
CPU inference¶
通过一些优化,可以在 CPU 上高效运行大型模型推理。
其中一种优化技术涉及将 PyTorch 代码编译为适用于 C++ 等高性能环境的中间格式。
另一种技术将多个操作融合到一个内核中,以减少单独运行每个操作的开销。
🤗 Optimum¶
ONNX Runtime (ORT) 是一个模型加速器,默认在 CPU 上运行推理。
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2")
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
onnx_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = "What's my name?"
context = "My name is Philipp and I live in Nuremberg."
pred = onnx_qa(question, context)
GPU inference¶
FlashAttention-2¶
警告
FlashAttention-2 是实验性的,在未来的版本中可能会发生很大的变化。
FlashAttention-2是标准注意力机制的更快、更高效的实现,可以通过以下方式显着加速推理:
- additionally parallelizing the attention computation over sequence length - partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
要启用 FlashAttention-2,请传递参数 attn_implementation=”flash_attention_2” 到from_pretrained() :
安装:
pip install flash-attn --no-build-isolation
BetterTransformer¶
BetterTransformer 通过其 fastpath 执行加速推理。fastpath 执行中的两个优化是:
fusion, which combines multiple sequential operations into a single “kernel” to reduce the number of computation steps
skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
bitsandbytes¶
bitsandbytes 是一个量化库,支持 4 位和 8 位量化。与原生全精度版本相比,量化可减小模型大小,从而更轻松地将大型模型安装到内存有限的 GPU 上。
博客- 使用 Hugging Face Transformers、Accelerate 和 BitsandBytes 进行大规模变压器的 8 位矩阵乘法简介: https://huggingface.co/blog/hf-bitsandbytes-integration
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
Others¶
Optimize inference using torch.compile()¶
本节旨在为🤗 Transformers 中的计算机视觉模型的torch.compile()引入的推理加速提供基准。
根据模型和 GPU, torch.compile()在推理过程中可实现高达 30% 的加速
示例:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
Conceptual guides¶
Glossary¶
DataParallel (DP)¶
【原始】Parallelism technique for training on multiple GPUs where the same setup is replicated multiple times, with each instance receiving a distinct data slice. The processing is done in parallel and all setups are synchronized at the end of each training step.
【定义】Data Parallelism(数据并行)是一种常用的并行训练技术,特别是在深度学习中用于多 GPU 的**训练**场景。该技术通过在多个 GPU 上复制相同的模型副本,并将输入数据划分成多个独立的部分,使得每个 GPU 处理不同的数据子集,从而并行执行计算任务。每个 GPU 处理自己的数据块,计算梯度,最终所有 GPU 的梯度会进行汇总(同步),并更新所有模型副本的参数。
【核心思想】将数据分片,模型复制,在多个 GPU 上并行计算。
模型复制:每个 GPU 都会得到一个完全相同的模型副本。所有的 GPU 都使用相同的模型结构和权重进行计算。
数据划分:训练数据被划分为多个子集,每个 GPU 处理不同的子集,完成前向传播和反向传播。
梯度同步:在每个 GPU 上独立计算完梯度后,所有 GPU 之间会通过通信机制将梯度进行汇总或平均,然后更新每个模型副本的参数。这保证了所有 GPU 的模型在每次训练步骤结束后保持同步。
【工作原理】
数据划分:假设你有一个包含 1024 条样本的批次(batch),并且你有 4 个 GPU。Data Parallelism 会将这 1024 条样本划分成 4 个子集(每个子集 256 条样本),并分配到不同的 GPU 上。
模型复制:每个 GPU 上都会有相同的模型副本。这些副本会初始化为相同的权重,并且在每一步训练中,它们的计算都是同步的。
并行计算:每个 GPU 独立地处理自己分配到的数据子集,执行前向传播(forward pass)和反向传播(backward pass)。这一部分计算是并行进行的,每个 GPU 的计算互不干扰。
梯度同步:当每个 GPU 计算完反向传播并得到梯度后,所有 GPU 会进行梯度同步。这意味着各 GPU 之间会通过网络通信,将它们各自计算的梯度汇总(通常是取平均),以确保所有模型副本的参数一致更新。
参数更新:梯度同步完成后,每个 GPU 会更新自己模型的参数。这些参数会通过汇总后的梯度进行更新,从而使得所有 GPU 上的模型在每个训练步骤结束后保持相同的权重。
【优势】
计算加速:通过将大批量数据分成多个小块,并行处理不同的部分,可以显著加速训练过程。理论上,使用 N 个 GPU 进行 Data Parallelism,可以实现近似 N 倍的加速效果(受限于通信开销和负载均衡)。
易于实现:相比其他并行技术(如 Tensor Parallelism 或 Pipeline Parallelism),Data Parallelism 的实现相对简单,因为只需要复制模型,并对数据进行划分和梯度同步。
扩展性:Data Parallelism 可以很容易地扩展到多个 GPU,甚至多个机器(通过分布式训练),适合大规模数据集的处理。
【劣势】
显存压力:每个 GPU 上都需要存储完整的模型副本,这意味着模型参数会被多次复制。如果模型非常大(例如 GPT-3 这样的模型),可能会导致显存不足的问题。
通信开销:在每个训练步骤结束时,所有 GPU 需要同步梯度。随着 GPU 数量的增加,通信开销会逐渐增加,尤其是在多个机器之间进行同步时,网络通信可能会成为瓶颈。
负载均衡:如果数据划分不均匀,某些 GPU 可能需要处理较重的工作,而其他 GPU 则可能处于闲置状态,这会影响并行效率。
【总结】Data Parallelism 是一种将模型副本分配到多个 GPU 并行处理不同数据子集的训练技术。通过在多个 GPU 上并行处理,可以加速模型训练,特别是适用于大型数据集的处理场景。虽然实现相对简单,但显存消耗和通信开销是 Data Parallelism 面临的主要挑战。
PipelineParallel (PP)¶
【原始文档】Parallelism technique in which the model is split up vertically (layer-level) across multiple GPUs, so that only one or several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline and working on a small chunk of the batch. Learn more about how PipelineParallel works here.
【定义】Pipeline Parallelism(流水线并行)是一种在深度学习中常用的并行技术,特别适用于训练大型神经网络模型,它通过将模型按层级进行划分,并将这些划分后的部分分配到不同的 GPU 上,从而在多个设备上并行处理模型的计算任务。每个 GPU 只负责执行模型的一部分(即某些特定的层)。这种划分方式被称为纵向切分(vertical split),相对传统的数据并行(data parallelism),它不是在不同设备上处理相同的模型,而是将模型本身拆分开来。
【工作原理】
1.模型划分(分层):假设你有一个 12 层的深度神经网络模型。你可以将前 4 层放在 GPU 1 上,接下来的 4 层放在 GPU 2 上,最后 4 层放在 GPU 3 上。每个 GPU 只存储和计算模型的一部分。
2.批量处理:Pipeline Parallelism 通常与批处理(batch processing)结合使用。假设输入的 batch 是 128 条样本:GPU 1 处理前 4 层时,它会处理第一小块数据(比如 64 条样本),然后将这些样本的输出传递给 GPU 2。当 GPU 2 开始处理这些样本时,GPU 1 可以开始处理 batch 中的下一小块数据。这样,多个 GPU 能够并行工作,像流水线一样处理数据,这就是流水线并行的名称来源。
流水线机制:各个 GPU 并不是完全独立工作的,而是按顺序处理数据。模型的每一部分(层)依赖于前一部分的输出。虽然各个 GPU 是并行的,但它们工作在同一条流水线上:当 GPU 1 处理第一个数据块时,GPU 2 处于空闲状态;当 GPU 1 处理完第一个数据块并传递给 GPU 2 时,GPU 2 开始处理第一块数据,同时 GPU 1 可以处理第二块数据;如此循环,直到整个 batch 被处理完毕。
【好处】
节省显存:对于非常大的模型,单个 GPU 可能无法一次性容纳整个模型的所有层。通过将模型切分到多个 GPU 上,每个 GPU 只存储一部分模型参数,显著减少了单个 GPU 的显存压力。
并行效率:Pipeline Parallelism 通过让不同的 GPU 同时处理不同的数据块,增加了计算效率。尽管需要一定的通信和同步,但相比于在单个 GPU 上运行完整模型,流水线并行可以加速训练过程。
【挑战】
通信开销:由于不同 GPU 之间需要相互传递数据(即前一层的输出需要传递到下一层的输入),GPU 之间的通信带来了一定的开销,特别是当 GPU 数量较多时,这种开销可能会变得显著。
延迟:流水线并行会有一定的启动延迟(即前一个设备必须先处理完部分数据后,才能将数据传递到下一个设备)。对于小 batch size,这种延迟会更加明显。
负载均衡:模型各层的计算复杂度不同,某些层可能需要更多的计算资源。如果每个 GPU 处理的层数相同,但计算量不同,就会导致某些 GPU 工作负载重,另一些 GPU 闲置,这种负载不均衡也会影响并行效率。
【总结】Pipeline Parallelism 是一种通过将模型纵向拆分(按层划分)并分布到多个 GPU 上处理的并行技术。每个 GPU 负责计算模型的一部分层,并且各 GPU 像流水线一样处理批量数据,这既能减少单个 GPU 的显存消耗,又能通过并行处理加速计算。但同时也带来了通信开销和负载均衡等挑战。
Tensor Parallelism (TP)¶
【原始】Parallelism technique for training on multiple GPUs in which each tensor is split up into multiple chunks, so instead of having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. Shards gets processed separately and in parallel on different GPUs and the results are synced at the end of the processing step. This is what is sometimes called horizontal parallelism, as the splitting happens on horizontal level. Learn more about Tensor Parallelism here.
【定义】Tensor Parallelism(张量并行)是一种在深度学习中常用的并行计算技术,主要用于将模型的张量切分为多个部分,并将这些部分分布到不同的 GPU 上进行并行处理。与 Pipeline Parallelism 不同,Tensor Parallelism 不将模型按层级划分,而是将每个张量(如权重矩阵或输入数据)水平切分(horizontally split),因此也被称为水平并行(horizontal parallelism)。
【核心思想】将模型的张量(包括参数、激活值等)切分为多个块(shards),并将这些块分布到不同的 GPU 上进行并行计算。这样可以减少每个 GPU 的计算负载和显存压力,同时加速训练。
【工作原理】
张量切分:假设你有一个张量(例如权重矩阵)大小为 (1024, 1024),而你有 4 个 GPU。你可以将这个张量水平切分成 4 个部分,每个部分的大小为 (256, 1024),分别放置在 4 个不同的 GPU 上。这样,张量的不同部分会分别在不同的 GPU 上进行处理。
并行计算:每个 GPU 处理张量的不同部分,并进行独立的计算。例如,在前向传播时,每个 GPU 会处理其分配到的张量部分。在反向传播时,梯度也在各自的 GPU 上计算。
结果同步:在每个计算步骤(如前向传播或反向传播)结束时,各个 GPU 会将它们的部分结果进行同步,以确保模型更新时所有张量部分的计算结果能够汇总。同步的过程是通过通信机制完成的,通常使用分布式框架(如 NVIDIA 的 NCCL 库)来高效传递数据。
【优势】
减少显存占用:通过将大的张量分成多个小块,每个 GPU 只需要存储和计算自己负责的张量部分,显著减少了单个 GPU 的显存消耗。这在处理大型模型(如 GPT-3)时非常重要,因为单个 GPU 无法容纳整个模型的权重。
加速计算:由于每个 GPU 只负责一部分张量,计算可以在多个 GPU 上并行进行,理论上可以线性加速训练过程。
【挑战】
通信开销:每个计算步骤结束时,各个 GPU 需要同步结果。对于较大的模型和较频繁的同步操作,这会导致显著的通信开销,影响整体性能。
负载均衡:在实际应用中,某些张量可能较小,切分后不同的 GPU 上计算量可能不均衡,导致某些 GPU 计算较慢,进而拖慢整个训练过程。
实现复杂度:相比 Data Parallelism,Tensor Parallelism 的实现更为复杂,因为涉及到张量的切分、分配、并行计算和同步等多个步骤。
【总结】Tensor Parallelism 是一种通过水平切分模型张量来分配到多个 GPU 进行并行计算的技术。这种技术可以显著减少显存消耗,尤其适合处理非常大的模型。它通过在不同 GPU 上并行处理张量的不同部分来加速计算,并在每个计算步骤后通过通信机制同步结果。与其他并行技术相比,Tensor Parallelism 在处理超大模型时非常有效,但也面临通信开销和实现复杂度的挑战。
Tensor Parallelism vs. Data Parallelism vs. Pipeline Parallelism¶
Tensor Parallelism:张量(如权重矩阵)被切分成多个小块,分布在不同的 GPU 上并行计算。适用于非常大的张量,能显著减少显存压力。
Data Parallelism:相同的模型副本运行在每个 GPU 上,但每个 GPU 处理不同的输入数据。在每个 GPU 计算完梯度后,梯度会进行平均并更新所有模型副本的参数。优点是实现相对简单,但显存压力依然很大,因为每个 GPU 都需要存储完整的模型参数。
Pipeline Parallelism:模型按层级切分,不同的层分配到不同的 GPU,多个 GPU 以流水线的方式处理批次数据。适合非常深的网络,但需要解决流水线启动和同步的问题。
Zero Redundancy Optimizer (ZeRO)¶
【原始】Parallelism technique which performs sharding of the tensors somewhat similar to TensorParallel, except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn’t need to be modified. This method also supports various offloading techniques to compensate for limited GPU memory. Learn more about ZeRO here.
【定义】Zero Redundancy Optimizer (ZeRO) 是由 DeepSpeed 框架提出的一种分布式优化策略。是一种优化器并行技术,旨在大幅减少深度学习模型训练中的内存使用,特别是在多 GPU 环境下。它通过 分片(sharding)管理 模型参数、梯度和优化器状态,极大地提高了 GPU 的内存效率,从而允许更大规模的模型在有限的 GPU 资源上进行训练。ZeRO 是一种与 Tensor Parallelism 相似的技术,但有一些独特的特性,使其能够进一步优化内存使用。
【核心思想】只在计算需要时才将张量重新构建,而在计算完成后将其再次分片到各个 GPU。因此,整个模型的张量不需要一直驻留在单个 GPU 上,从而有效减少了显存的占用。
【三个阶段】
Stage 1:Optimizer State Sharding(优化器状态分片)在训练过程中,优化器会维护很多状态信息(例如动量、二阶梯度等),这些状态会消耗大量的内存。在 Stage 1,ZeRO 将这些优化器状态分片到不同的 GPU 上,每个 GPU 只维护一部分优化器状态。因此,内存消耗从所有 GPU 都需要存储完整的优化器状态,变成每个 GPU 只存储一部分。
Stage 2:Gradient Sharding(梯度分片)梯度通常在反向传播过程中计算并存储。Stage 2 将这些梯度也进行分片,各个 GPU 只存储一部分的梯度。这样,反向传播中的梯度计算仍然是并行的,但存储的内存显著减少。
Stage 3:Parameter Sharding(参数分片)在 Stage 3,模型的参数本身也被分片。每个 GPU 只存储模型参数的一部分,而不是整个模型的副本。在前向传播和反向传播的过程中,模型的参数只会在需要计算的时刻被重构和使用,之后再重新分片和同步。
【原理】在 ZeRO 中,模型参数、梯度和优化器状态不再被每个 GPU 完整地复制,而是被划分成多个块(shards),分布在不同的 GPU 上。当模型进行前向传播、反向传播或者更新参数时:
在需要计算的时候,ZeRO 会将分片的张量重构(reconstruct)成完整的张量,进行计算。
计算结束后,张量会再次被切分并分配回各个 GPU,这样整个训练过程中每个 GPU 只需要处理一部分的张量。
ZeRO 与 Tensor Parallelism 的区别:Tensor Parallelism 是在前向传播和反向传播过程中将张量水平切分,不同 GPU 并行处理张量的不同部分,然后同步计算结果。ZeRO 通过分片模型参数、梯度和优化器状态,使得每个 GPU 不需要同时存储整个模型的副本。在计算时,ZeRO 动态重构张量,计算完后再进行分片,而不是一开始就将张量水平切分并固定下来。
【优势】无需对模型结构进行修改,而只需要调整张量的存储和处理方式,因此模型本身不需要特别为 ZeRO 进行重写。不仅通过分片减少 GPU 内存的占用,还支持offloading 技术,这意味着可以将部分计算或数据从 GPU 卸载到 CPU,甚至 NVMe 存储(硬盘),通过这种技术,即使 GPU 内存非常有限,也能支持大模型训练:
【总结】Zero Redundancy Optimizer (ZeRO) 是一种高效的并行优化技术,它通过 分片(sharding) 模型的参数、梯度和优化器状态,将这些信息分布在多个 GPU 上,从而极大地减少了单个 GPU 的内存占用。它能够支持训练非常大的模型,同时保持较高的计算效率。与 Tensor Parallelism 不同,ZeRO 允许动态重构张量,且不需要对模型进行修改。此外,ZeRO 还支持将计算和存储卸载到 CPU 或硬盘,进一步优化有限资源上的模型训练。
Fully Sharded Data Parallel¶
备注
参见上面相关章节
Optimizing LLMs for Speed and Memory¶
effective techniques for efficient LLM deployment:
1. Lower Precision
降低精度(即8 位和 4 位)运行可以实现计算优势,而不会显着降低模型性能
2. Flash Attention
注意力算法的一种变体,它不仅提供了一种更节省内存的方法,而且由于优化了 GPU 内存利用率而实现了效率的提高
3. Architectural Innovations
模型架构中最重要的进步有:
Alibi, Rotary embeddings, Multi-Query Attention (MQA) and Grouped-Query-Attention (GQA).
1. Lower Precision¶
所有量化技术的工作原理:
1. Quantize all weights to the target precision
将所有权重量化到目标精度
2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
加载量化权重,并以 bfloat16 精度传递向量的输入序列
3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
将权重动态反量化为 bfloat16,以使用 bfloat16 精度的输入向量执行计算
备注
使用量化权重时,先把权重反量化为 bfloat16,输入序列还是 bfloat16,计算两者乘积。所以,推理时间通常不会减少,反而会增加。总之,重要的是要记住,模型量化以准确性和在某些情况下牺牲推理时间为代价提高内存效率。
2. Flash Attention¶
对于大型输入上下文,默认的自注意力算法很快就会变得非常昂贵的内存消耗。
通过跟踪 softmax 归一化统计数据并使用一些智能数学,与默认的自注意力层相比,Flash Attention 提供了相同的数值输出,而内存成本仅随时间线性增加 N
而且与默认注意力相比,闪存注意力的推理速度要快得多,这是因为它能够显着减少对 GPU (VRAM) 较慢、高带宽内存的需求,而是专注于更快的片上内存 (SRAM) 。
实际上,目前绝对没有理由不使用 Flash Attention(如果可用)。该算法在数学上给出相同的输出,并且速度更快且内存效率更高。
3. Architectural Innovations¶
3.1 Improving positional embeddings of LLMs¶
位置嵌入(positional embeddings) 是自注意力机制的核心组成部分,负责帮助模型理解文本序列中不同 token 之间的顺序关系
【背景:位置嵌入的必要性】**自注意力机制**中的 Softmax(QK^T) 操作将每个 token 与序列中的其他 token 进行关联,但默认情况下它无法理解 token 之间的相对顺序。没有位置嵌入的模型难以区分不同的输入顺序。例如,模型无法区分 “Hello I love you” 和 “You love I hello”,因为它们在没有位置信息的情况下看起来是等价的。
因此,位置嵌入(positional embeddings)被引入,用来编码每个 token 在句子中的位置信息,使模型能够区分输入文本的顺序。
传统方法主要有两种:固定位置嵌入(sinusoidal embeddings) 和 学习的绝对位置嵌入(learned positional embeddings)。
【问题:传统位置嵌入的局限性】1.对长文本表现较差:绝对位置嵌入为每个位置生成一个唯一的编码(例如 0 到 N 的位置编号),但对于长文本,模型难以有效建模 token 之间的远距离关系。2.固定输入长度问题:如果使用学习的绝对位置嵌入,模型只能处理与训练时长度相同的输入。如果输入长度超出训练时的最大长度,模型无法很好地进行推断。
【解决:相对位置嵌入:RoPE 和 ALiBi】为了解决上述问题,研究者提出了相对位置嵌入(relative positional embeddings),这种方法不再为每个位置分配绝对值,而是关注 token 之间的相对距离。两种流行的相对位置嵌入方法是 RoPE(Rotary Position Embedding) 和 ALiBi(Attention with Linear Biases)。它们通过修改自注意力机制中的 QK^T 矩阵来引入位置信息。
3.2 The key-value cache¶
这是一个非常有效的优化策略,特别适用于处理长序列或生成大量文本的场景。
【背景:自回归文本生成】在 LLM 中,自回归文本生成通过逐步生成下一个 token 来完成。每次输入先前生成的 token 序列,然后模型预测下一个 token,并将其加入输入序列中,如此循环直到生成结束。在这种逐步生成的过程中,随着序列长度的增加,每次都需要对整个序列重新计算
QK^T矩阵,进而得到注意力权重。这意味着每一步的计算复杂度会随着序列长度的增加而增大。【问题:重复计算的效率低下】对于自回归生成来说,模型在生成下一个 token 时,每一步都需要重新计算所有之前的 token 的 key 和 value,尽管这些值在之前的步骤中已经计算过了。重复计算这些不必要的 key-value 对会导致计算资源的浪费,并且在生成长序列时显著增加计算复杂度和显存占用。
【解决方案:Key-Value Cache】通过缓存每一层的 key 和 value 向量(即 K 和 V),避免重复计算,从而提高效率。
【原理】**QK^T 矩阵优化**:在标准 Transformer 模型中,QK^T 矩阵是通过将每个 token 的 query 向量(Q)与所有 key 向量(K)进行点积计算得出的。然而,对于自回归生成,我们每次只需要为新增的 token 计算 query (q_c)与之前缓存的 key(K)进行相乘,而不需要重新计算所有的 key 和 value。缓存机制:在每一步生成过程中,将之前的 key-value 对保存在缓存中,下一步生成时只需计算当前新 token 的 query,然后与缓存中的 key 进行计算。这样避免了重复计算整个序列的 key-value 对。
3.2.1 Multi-round conversation¶
键值缓存对于聊天等需要多次自动回归解码的应用程序特别有用
示例:
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
在此聊天中, LLM运行自回归解码两次:
第一次,键值缓存为空,输入提示为 “User: How many people live in France?” 模型自动回归生成文本 “Roughly 75 million people live in France” 同时在每个解码步骤增加键值缓存。
第二次输入提示是 “User: How many people live in France? n Assistant: Roughly 75 million people live in France n User: And how many in Germany?” 。由于缓存,前两个句子的所有键值向量都已经计算出来。因此输入提示仅包含 “User: And how many in Germany?” 。在处理缩短的输入提示时,其计算出的键值向量被连接到第一次解码的键值缓存。第二次回答 “Germany has ca. 81 million inhabitants” 然后使用由编码的键值向量组成的键值缓存自动生成 “User: How many people live in France? n Assistant: Roughly 75 million people live in France n User: And how many are in Germany?” 。
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values, # ❇️
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
3.2.2 Multi-Query-Attention (MQA)¶
【定义】一种优化自注意力机制的技术,旨在减少key-value 缓存的内存占用并提高计算效率。该方法由 Noam Shazeer 在论文 “Fast Transformer Decoding: One Write-Head is All You Need” 中提出,核心思想是共享 key-value 投影,从而大幅降低多头注意力(Multi-Head Attention)的内存开销。
【背景:传统多头注意力机制的内存瓶颈】在传统的**多头注意力机制(Multi-Head Attention)**中,模型会为每个注意力头(attention head)计算独立的 key-value 对。具体来说,n 个注意力头意味着需要计算并存储 n 组 key-value 向量,通常会显著增加内存和计算开销。大规模语言模型(LLMs)中,通常有 20 到 100 个注意力头,因此当缓存这些 key-value 对时,内存消耗非常高,尤其是在长文本生成或多轮对话中。
【核心思想】关键在于:所有注意力头共享一个 key-value 投影,即每个头仍然拥有独立的 query(查询向量),但 key 和 value 向量在所有注意力头中是相同的。这样可以显著减少存储和计算的开销,而不会显著影响模型的性能。
【应用】MQA 技术已经被许多主流的大规模语言模型(LLMs)所采用,包括:Falcon,PaLM,MPT,BLOOM
3.2.3 Grouped-Query-Attention (GQA)¶
【定义】由 Google 研究员 Ainslie 等人在论文中提出的注意力机制优化方法,它旨在解决 Multi-Query Attention (MQA) 带来的性能下降问题,同时保留大部分内存和计算效率的提升。相比 MQA,GQA 提供了一个更加折中的解决方案,在提升计算效率的同时,减少对模型性能的影响。
【背景:MQA 的局限性】Multi-Query Attention (MQA) 通过为所有注意力头共享一个 key-value 投影,显著减少了内存和计算开销,尤其在自回归生成时提高了推理速度并降低了显存占用。然而,研究发现 MQA 的这种极端共享机制会带来一定的模型性能下降,因为不同的 query 头无法再独立学习与 key-value 的对应关系,导致注意力机制的灵活性受限。
【核心思想】Grouped-Query Attention (GQA) 提出了一个折衷方案:减少注意力头的 query 投影数量,但不将其完全合并为一个。具体来说,GQA 提出将注意力头分组,多个头共享一组 key-value 投影,而不是每个头都使用完全独立的投影,也不是像 MQA 那样所有头共享同一组投影。
API¶
Main Classes¶
Auto Classes¶
AutoConfig
AutoTokenizer
AutoFeatureExtractor
AutoImageProcessor
AutoProcessor
Generic model classes:
AutoModel
Generic pretraining classes:
AutoModelForPreTraining
Natural Language Processing:
AutoModelForCausalLM
AutoModelForMaskedLM
AutoModelForMaskGeneration
AutoModelForSeq2SeqLM
AutoModelForSequenceClassification
AutoModelForMultipleChoice
AutoModelForNextSentencePrediction
AutoModelForTokenClassification
AutoModelForQuestionAnswering
AutoModelForTextEncoding
Computer vision:
AutoModelForDepthEstimation
AutoModelForImageClassification
AutoModelForVideoClassification
AutoModelForKeypointDetection
AutoModelForMaskedImageModeling
AutoModelForObjectDetection
AutoModelForImageSegmentation
AutoModelForImageToImage
AutoModelForSemanticSegmentation
AutoModelForInstanceSegmentation
AutoModelForUniversalSegmentation
AutoModelForZeroShotImageClassification
AutoModelForZeroShotObjectDetection
Audio:
AutoModelForAudioClassification
AutoModelForAudioFrameClassification
AutoModelForCTC
AutoModelForSpeechSeq2Seq
AutoModelForAudioXVector
AutoModelForTextToSpectrogram
AutoModelForTextToWaveform
Multimodal:
AutoModelForTableQuestionAnswering
AutoModelForDocumentQuestionAnswering
AutoModelForVisualQuestionAnswering
AutoModelForVision2Seq
Backbone¶
backbone(主干)是一种用于为更高级别的计算机视觉任务(例如对象检测和图像分类)进行特征提取的模型。
Transformers 提供了一个
AutoBackbone类,用于根据预训练的模型权重初始化 Transformers 主干两个实用程序类:
AutoBackbone BackboneMixin BackboneConfigMixin TimmBackbone TimmBackboneConfig
Callbacks¶
Callbacks 是可以在 PyTorch Trainer中自定义训练循环行为的对象(该功能尚未在 TensorFlow 中实现),可以检查训练循环状态(用于进度报告、登录 TensorBoard 或其他 ML 平台……)并做出决策(如提前停止)。
Configuration¶
base class:
PretrainedConfig
通用属性有:
hidden_size
num_attention_heads
num_hidden_layers
文本模型进一步实现: vocab_size
Data Collator¶
Data collators 是通过使用数据集元素列表作为输入来形成批次的对象。这些元素与train_dataset或eval_dataset的元素具有相同的类型。
DefaultDataCollator
DataCollatorWithPadding
DataCollatorForTokenClassification
DataCollatorForSeq2Seq
DataCollatorForLanguageModeling
DataCollatorForWholeWordMask
DataCollatorForPermutationLanguageModeling
DataCollatorWithFlattening
Logging¶
默认是WARNING
修改代码:
import transformers
transformers.logging.set_verbosity_info()
环境变量 TRANSFORMERS_VERBOSITY:
TRANSFORMERS_VERBOSITY=error ./myprogram.py
环境变量来禁用一些warnings TRANSFORMERS_NO_ADVISORY_WARNINGS
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
Models¶
基类:
PreTrainedModel 、 TFPreTrainedModel和FlaxPreTrainedModel
ModuleUtilsMixin
PushToHubMixin
Text Generation¶
每个框架都有一个用于文本生成的生成方法,在各自的
GenerationMixin类中实现:
GenerationConfig
WatermarkingConfig
GenerationMixin
from transformers import GenerationConfig
# Download configuration from huggingface.co and cache.
generation_config = GenerationConfig.from_pretrained("openai-community/gpt2")
# E.g. config was saved using *save_pretrained('./test/saved_model/')*
generation_config.save_pretrained("./test/saved_model/")
generation_config = GenerationConfig.from_pretrained("./test/saved_model/")
# You can also specify configuration names to your generation configuration file
generation_config.save_pretrained("./test/saved_model/", config_file_name="my_configuration.json")
generation_config = GenerationConfig.from_pretrained("./test/saved_model/", "my_configuration.json")
# If you'd like to try a minor variation to an existing configuration, you can also pass generation
# arguments to `.from_pretrained()`. Be mindful that typos and unused arguments will be ignored
generation_config, unused_kwargs = GenerationConfig.from_pretrained(
"openai-community/gpt2", top_k=1, foo=False, do_sample=True, return_unused_kwargs=True
)
generation_config.top_k # 1
unused_kwargs # {'foo': False}
ONNX¶
三个抽象类:
We provide three abstract classes that you should inherit from, depending on the type of model architecture you wish to export:
OnnxConfig
OnnxConfigWithPast
OnnxSeq2SeqConfigWithPast
ONNX Features:
Each ONNX configuration is associated with a set of features that enable you to export models for different types of topologies or tasks.
FeaturesManager
Optimization¶
The .optimization module provides:
an optimizer with weight decay fixed that can be used to fine-tuned models, and
一个固定权重衰减的优化器,可用于微调模型
several schedules in the form of schedule objects that inherit from `_LRSchedule`:
a gradient accumulation class to accumulate the gradients of multiple batches
一个梯度累积类,用于累积多个批次的梯度
AdamW
Implements Adam algorithm with weight decay fix
AdaFactor
can be used as a drop in replacement for Adam original fairseq code
Schedules
SchedulerType
Model outputs¶
所有模型的输出都是ModelOutput子类的实例。
All models have outputs that are instances of subclasses of ModelOutput. Those are data structures containing all the information returned by the model, but that can also be used as tuples or dictionaries.
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
# outputs对象是一个SequenceClassifierOutput
ModelOutput
BaseModelOutput
BaseModelOutputWithPooling
BaseModelOutputWithCrossAttentions
BaseModelOutputWithPoolingAndCrossAttentions
BaseModelOutputWithPast
BaseModelOutputWithPastAndCrossAttentions
Seq2SeqModelOutput
CausalLMOutput
CausalLMOutputWithCrossAttentions
CausalLMOutputWithPast
MaskedLMOutput
Seq2SeqLMOutput
NextSentencePredictorOutput
SequenceClassifierOutput
Seq2SeqSequenceClassifierOutput
MultipleChoiceModelOutput
TokenClassifierOutput
QuestionAnsweringModelOutput
Seq2SeqQuestionAnsweringModelOutput
Seq2SeqSpectrogramOutput
SemanticSegmenterOutput
ImageClassifierOutput
ImageClassifierOutputWithNoAttention
DepthEstimatorOutput
Wav2Vec2BaseModelOutput
XVectorOutput
Seq2SeqTSModelOutput
Seq2SeqTSPredictionOutput
SampleTSPredictionOutput
Pipelines¶
pipe = pipeline("text-classification")
pipe("This restaurant is awesome")
Processors¶
Multi-modal processors¶
任何多模态模型都需要一个对象来编码或解码将多种模态(modalities)(文本、视觉和音频)分组的数据。
这是由称为
processors的对象来处理的,它将两个或多个处理对象(processing objects)组合在一起,例如分词器(用于文本模态)、图像处理器(用于视觉)和特征提取器(用于音频)。
ProcessorMixin
Quantization¶
量化技术通过使用 8 位整数 (int8) 等较低精度的数据类型表示权重和激活来减少内存和计算成本。这可以加载通常无法装入内存的更大模型,并加快推理速度。 Transformers 支持 AWQ 和 GPTQ 量化算法,并且支持 8 位和 4 位量化(bitsandbytes)。
QuantoConfig
AqlmConfig
AwqConfig
EetqConfig
GPTQConfig
BitsAndBytesConfig
HfQuantizer
HqqConfig
FbgemmFp8Config
CompressedTensorsConfig
TorchAoConfig
Tokenizer¶
PreTrainedTokenizer
PreTrainedTokenizerFast
BatchEncoding
Trainer¶
Trainer
Seq2SeqTrainer
TrainingArguments
Seq2SeqTrainingArguments
Models¶
Text models¶
Qwen2¶
Qwen2 is the new model series of large language models from the Qwen team.
Qwen2Config
Qwen2Tokenizer
Qwen2TokenizerFast
Qwen2Model
Qwen2ForCausalLM
Qwen2ForSequenceClassification
Qwen2ForTokenClassification
Qwen2_VL¶
Qwen2VLConfig
Qwen2VLImageProcessor
Qwen2VLProcessor
Qwen2VLModel
Qwen2VLForConditionalGeneration
CPM¶
The CPM model was proposed in CPM: A Large-scale Generative Chinese Pre-trained Language Model
DPR¶
Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research.
It was introduced in Dense Passage Retrieval for Open-Domain Question Answering by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
相关论文: Dense Passage Retrieval for Open-Domain Question Answering(https://arxiv.org/abs/2004.04906)
开放域问答依赖于高效的段落检索来选择候选上下文,其中传统的稀疏向量空间模型(如 TF-IDF 或 BM25)是事实上的方法。在这项工作中,我们表明检索可以单独使用密集表示实际实现,其中嵌入是通过一个简单的双编码器框架从少量问题和段落中学习的。在广泛的开放域 QA 数据集上进行评估时,我们的密集检索器在前 20 名传代检索准确率方面比强大的 Lucene-BM25 系统高出 9%-19%,并帮助我们的端到端 QA 系统在多个开放域 QA 基准上建立新的最先进的技术。
Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.
DPR consists in three models:
1. Question encoder: encode questions as vectors
2. Context encoder: encode contexts as vectors
3. Reader: extract the answer of the questions inside retrieved contexts, along with a relevance score
(high if the inferred span actually answers the question).
Dense Passage Retrieval (DPR) 是一种用于信息检索的深度学习方法,尤其适合回答开放领域的问题。DPR通过双塔结构(dual encoder)的神经网络模型来实现文本的向量化表示,主要由两部分组成:一个查询编码器和一个文档编码器。这两个编码器通常使用预训练的BERT模型或其他Transformer模型,分别对用户查询和候选文档进行编码,生成固定维度的密集向量(dense vector)。
通过在大规模数据集(例如,Wikipedia passages)上进行监督学习训练,DPR可以在各种任务(如问答系统、文档检索)中实现高效和准确的文本检索。相比于传统的稀疏向量检索(如TF-IDF或BM25),DPR的密集表示可以更好地捕捉词汇的语义相似性,因此在需要更精准语义匹配的任务中表现更佳。
DPR的工作原理如下:
1. 查询编码:将用户输入的自然语言查询(如问题或关键词)转化为密集向量。 2. 文档编码:将候选文档库中的每个文档转化为密集向量。 3. 相似度计算:利用向量相似度度量(如内积或余弦相似度)计算查询与文档之间的相似度分数,从而选出最相关的文档。
Related Models:
dpr-reader-single-nq-base
dpr-ctx_encoder-single-nq-base
dpr-question_encoder-single-nq-base
dpr-ctx_encoder-multiset-base
dpr-question_encoder-multiset-base
dpr-reader-multiset-base
说明:
single-nq-base: 适合专注于Natural Questions(NQ)数据集的问题回答,通常在特定领域的问答任务中表现更佳
multiset-base: 在多个数据集上训练,具备跨领域问答的能力,更加通用
dpr-reader: 用于答案抽取的阅读器模型。它在DPR的检索后处理阶段使用,以从选定的候选段落中找到具体的答案。这种模型基于BERT或类似的Transformer架构,经过训练可以从候选文本中提取出最有可能的答案片段。一般来说,它依赖于查询编码器和文档编码器筛选出的候选段落作为输入。
dpr-ctx_encoder: 用于将文档或段落编码为密集向量的文档(或上下文)编码器。其作用是将大量候选文档或段落转换为固定维度的密集向量表示。通过这种方式,系统可以利用向量检索方法(如内积或余弦相似度)在大规模文档库中快速检索出与查询最相关的文档。
dpr-question_encoder: 用于将用户问题编码为密集向量的查询编码器。这个模型将自然语言查询转换为密集向量,以便与文档编码器生成的文档向量进行相似度匹配,找到最相关的候选文档。
DPR 模型的流程:
Step 1: 用户输入的问题通过 dpr-question_encoder 编码为密集向量。
Step 2: 候选文档通过 dpr-ctx_encoder 编码为密集向量。
Step 3: 通过计算查询向量与文档向量之间的相似度(通常是内积),检索到相关度最高的候选文档。
Step 4: 将这些候选文档交给 dpr-reader,由其从中抽取具体答案片段。
其他-fromGPT¶
Transformer 的主要组成部分包括:
1. Attention Block、
注意力模块,最核心的模块
2. Feed-Forward Network (FFN)
在每个 Transformer 层中,注意力模块后面是一个前馈神经网络(Feed-Forward Network),通常是一个两层的全连接网络
FFN 对每个位置独立操作,主要负责非线性变换,增强模型的表示能力。
FFN 的参数规模通常很大,因此也是计算开销的一个主要来源。
3. Embedding Layer
Embedding 层用于将输入的离散标记(tokens)转化为连续的向量表示。
在 NLP 模型中,输入和输出通常都有 embedding 层,分别将输入标记转为向量和将输出向量转回标记。
对于 NLP 模型,词汇表的大小会影响 embedding 层的参数规模。
4. Positional Encoding
Transformer 不具备内在的序列位置感知,因此需要加入位置编码(positional encoding)来表示序列中每个位置的信息。
位置编码可以是固定的(例如通过正弦和余弦函数生成)或是可训练的向量。
虽然位置编码不包含很多参数,但它在 Transformer 中至关重要,帮助模型区分序列中的位置。
5. Layer Normalization
每个 Transformer 层通常包含一个或多个层归一化(Layer Normalization)步骤,用于加速训练收敛,稳定模型性能。
虽然 Layer Normalization 的参数很少,但对模型的稳定性和性能有较大影响。
6. Residual Connections
在每个模块(如 Attention 和 FFN)中,通常使用残差连接(residual connections)来连接输入和输出,以避免梯度消失和梯度爆炸问题。
残差连接本身没有参数,但在计算图中增加了对输入的直接引用。