1.7.3. CPython的内存管理架构¶
CPython的内存概念:栈,堆和引用¶
堆:主要负责存储CPython运行时的所有对象实体(也就是Python对象的所有属性数据),例如:
smt='Hello Word' # 这是个字符串对象 ``PyASCIIObject`` n=123456 # 这是一个整数对象 ``PyLongObject`` 它们都是Python对象,赋值符号“=”右边的数据值,CPython会将其存储到堆内存中
栈:在CPython的语义中,又叫数据栈或值栈,它主要负责保存对
堆中Python对象的引用,例如:当CPython在执行smt='Hello Word'这个简单的Python语句, CPython会将'Hello Word'这个字符串实体的内存地址压入栈(对于Python语义级别理解,就是对"Hello Word"的引用), 而不是将'Hello Word'这个字符串值压入栈Python对象的引用:
就是Python变量持有Python对象在堆内存中的内存地址 可以通过python的内置 ``id()`` 函数来获取, 或者可以使用关键字is 来判断两个变量是否对同一个对象的引用。
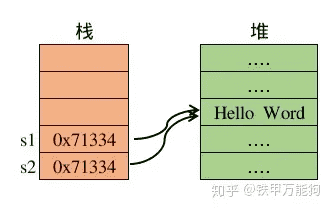
在执行s1=’Hello Word’,将它的内存地址0x71334推入数据栈,那么当CPython碰到同样的语句s2=’Hello Word’,明显是指向同一个Python对象,那么变量s2和s1一样,它自然持有是‘Hello Word’的引用,即s2实质上拥有的‘Hello Word’的堆中的地址。¶
在Python中有两种类型的对象,就是可变对象和不可变对象。
[示例]一个列表作为一个对象存储在堆内存中,如果我们要更改该列表的某些元素,它将仍然是内存中的同一个列表对象:
L = [11, 12, 32, 45]
L[2] = 734
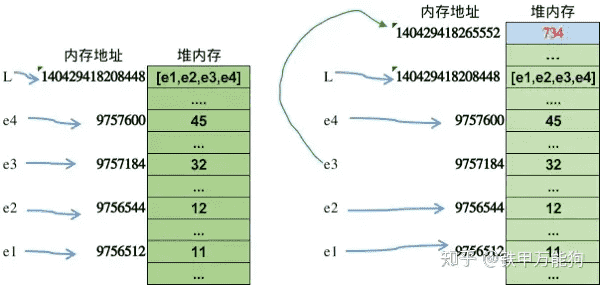
示例说明:对list对象中的某个元素的修改的本质是:把被修改元素指向其他元素的引用,而我们修改该元素时,实际上CPython在堆内存中创建了一个新的对象(本例中的整数734)分配新的内存空间,并且保存该新增的对象(整数734)。L的第三个元素不再对32的引用,更新为对734的引用。但其过程,list类型对象在其元素修改前后,变量L始终引用同一个list对象。¶
可变对象的实质:其内部元素可修改是变更对其他Python对象的引用。其可变对象的元素可以是数字、字符串,甚至可以是其他容器级别的可变对象。
不可变对象:Python中的原始数据类型,例如数字类型(int,float)、字符串(str)、字节数组(bytes)。
在Python中,一切事物都是对象,不论是整数,字符串,甚至是其他容器级别的数据类型,都由CPython的C底层由一个叫struct PyObject结构体所封装。PyObject的结构体在CPython运行时存储在堆内中,对于C底层来说,任意的PyObject结构体能够返回内存地址因此是一个左值,但对于Python语义来说,不存在静态语言中的左值和右值,它只能理解的是PyObject这个C实现的对象。
当多个Python变量引用同一个Python对象就涉及到概念就引用计数器,引用计数器属于内存垃圾回收的范畴,由引用计数又会牵涉到CPython一个致命的诟病,GIL:全局解释器锁,为什么多年来CPython不能去掉GIL,很大原因跟引用计数器有关。
CPython的内存管理架构-L1¶
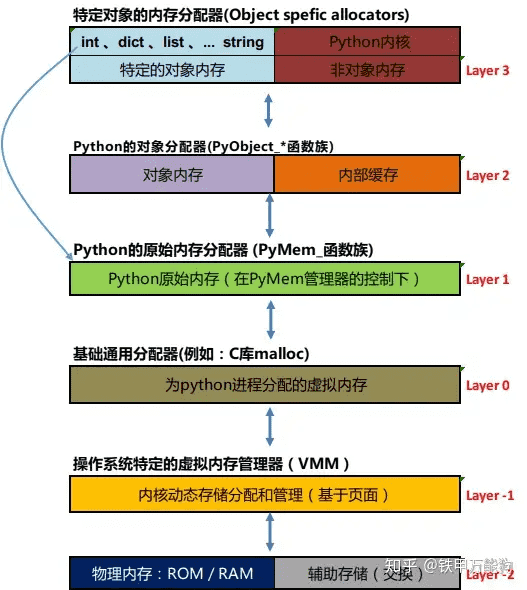
Python内存体系结构各层的介绍¶
CPython的内存管理架构-L2¶
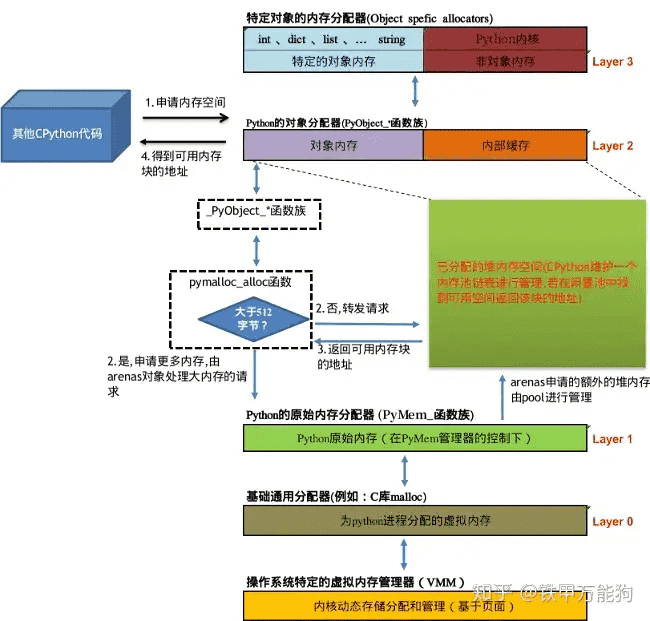
Layer 1与Layer 2的内存APIs的交互¶
引入两个CPython的专业术语,CPython根据内存分配的尺寸的阀值512字节可以分为,对Python对象做如下分类:
大于``512字节``的Python对象,称为``大型对象(Big)``,CPython会选择调用
PyMem_RawMalloc()或PyMem_RawRealloc()为其分配内存,换句话就是通过第0层去调用C库的malloc分配器少于或等于``512字节``的Python对象,称为``小型对象(Small)`` ,小型对象的内存请求按该对象的类型尺寸分组,这些分组按8个字节对齐,由于返回的地址必须有效对齐。这些类型尺寸的对象的内存请求由4KB的内存池提供内存分配,当然前提是该内存池有闲置的块。
CPython的内存分配策略¶
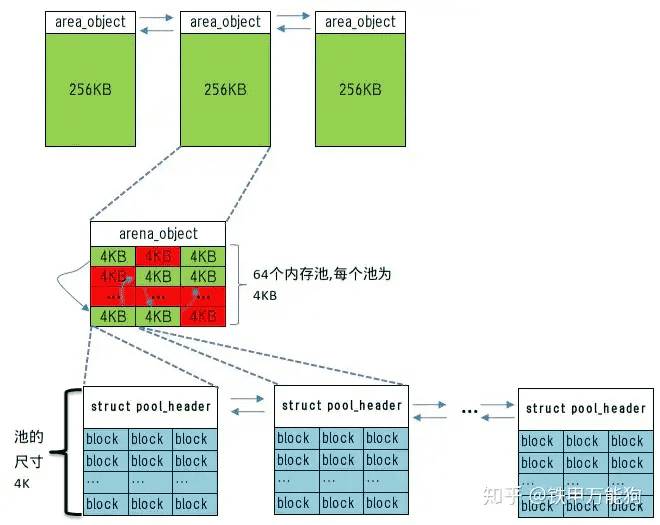
CPython的内存管理策略,分3个不同级别的对象,分别是Arenas->pool->block(Arenas->pool->block堆内存托管模型)¶
每个Arenas对象包装包含64个内存池,每个Arenas固定大小为256KB,并且该对象头部用两个struct area_object类型的指针在堆中构成Arenas对象的双重链表。(注:Arenas对象的尺寸为256KB就是CPython的大型对象)
每个内存池(Pool),固有尺寸为4KB,每个内存池包含尺寸相同的逻辑块,并且并且该对象头部用两个struct pool_header类型的指针构成pool对象的双重链表。
块是封装Python对象的基本单位,对于Areas对象来说都按8字节的块来划分PyMem已分配的所有堆内存(备注:切入点1)。
块(Block)¶
CPython的内存管理策略中,首先定义逻辑上的“块”,并且用8字节对齐的方式确定块的尺寸,换句话说块的尺寸可以看作8的倍数那么大
例如你创建来一个25字节的Python对象,25字节不是8字节的倍数,那么CPython运行时系统会根据内存对齐的原则为该Python对象额外添加7个填充字节,就凑够32字节(8的倍数)
备注
对于CPython3.7之后的版本,小型对象的内存分配的基准是16字节对齐的,而不是8字节。CPython 3.7之后,CPython的开发团队为何要将内存块的对齐基准从8字节调整到16字节: https://github.com/python/cpython/pull/12850
池(Pools)¶
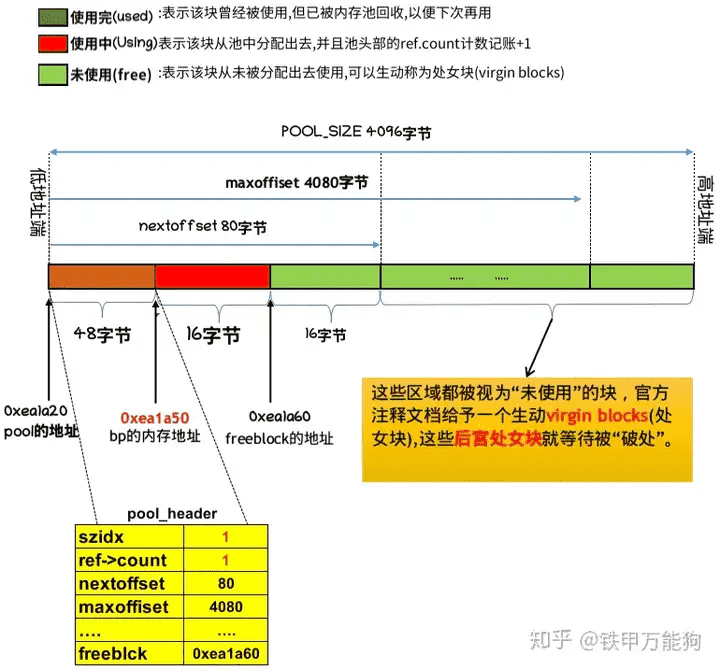
对于CPython 3.6之前的单个内存池内的初始内存布局如图所示,由于是基于8字节对齐的¶
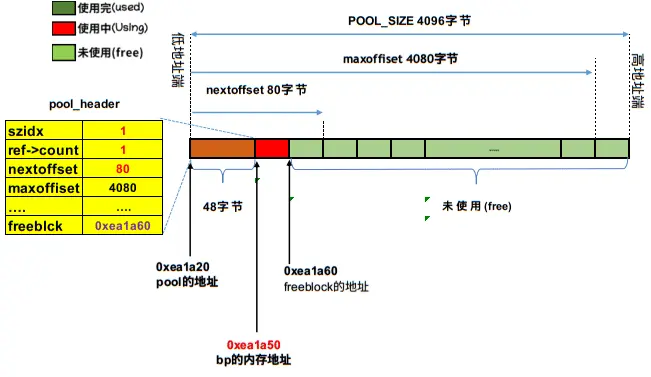
当内存池接收到来自pymalloc_alloc连续分配4个size class为16的内存请求,池分配内存块的过程是一个朝向nextoffset不断指向高地址的过程,也是nextoffset和maxnextoffset的距离越来越少的过程¶
池状态:
1. used
池中至少由一个block已经正在使用,并且至少由一个block还未被使用
这种状态的内存池由CPython的usedpool统一管理
2. full状态
pool中所有block都已正在使用
这种状态的pool在arena托管的池集合内,但不再arena的freepools链表中
3. empty状态
pool中的所有状态都未被使用
处于这个状态的pool的集合通过其pool_header结构体的nextpool构成一个链表,这个链表的表头就是arena_object结构体的freepools指针
Arena¶
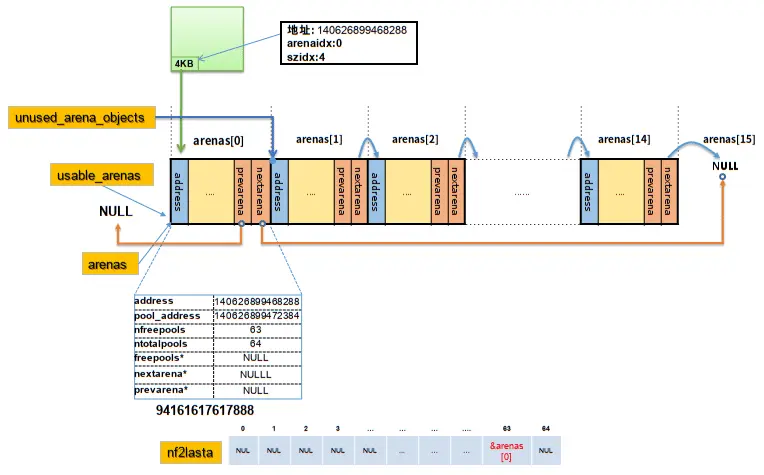
在第一个arena对象托管的内存池集合空间(256KB)里,初始化第一个内存池后,如下图如此类推…第2个、第3个、……¶
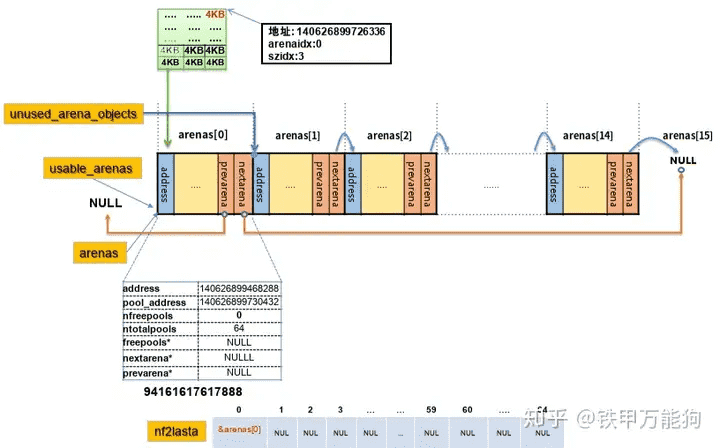
当前arena所托管的内存池集合满载状态(fulled)的情景,也就是说内存池集合所有内存池的状态都是正在使用(using)¶
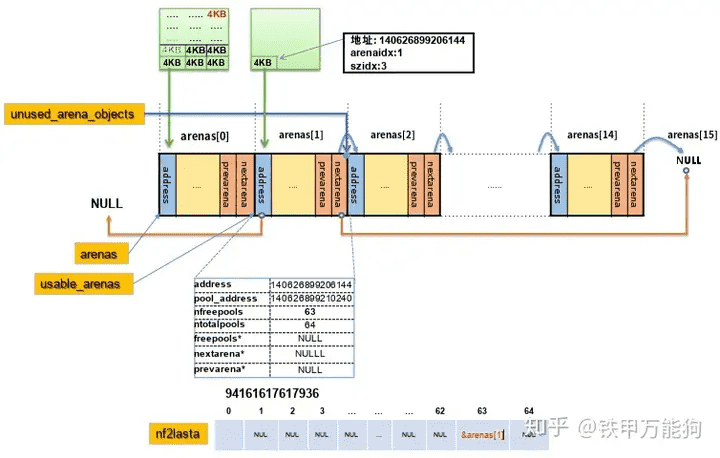
第二个arena对象其内存池集合中第一个内存池初始化后的情景图¶
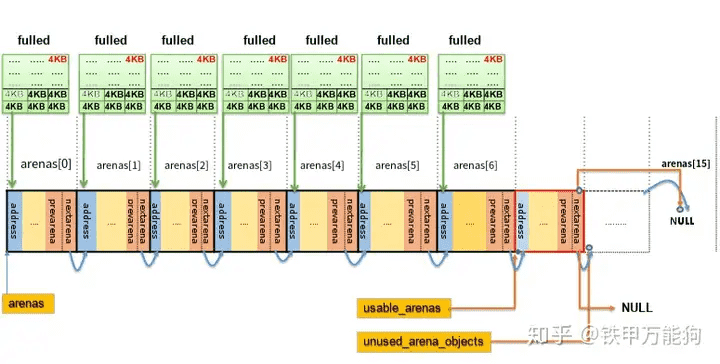
在CPython的7个arena对象初始化完成后,它们托管的内存池集合都完全分配了¶
usedpools¶
在Python3.x中,Python内部默认的小块内存与大块内存的分界点是512字节,我们知道当小于512字节的内存请求,PyObject_Malloc会在内存池中申请内存,当申请的内存大于512字节,PyObject_Malloc的行为会蜕化为malloc的行为。
例如当我们申请一个28字节的内存时,Python内部会在内存池寻找一块能满足需求的pool,并从中取出一个block,而不会去需找arena,这实际上事由pool和arena自身的属性确定的,pool有一个size概念的内存管理抽象体,一个pool中的block总是有确定的类型尺寸.
pool_header结构体定义中有一个szidx就是指定了对应的pool分配出去的块的最小的块单位-类型尺寸(size class),然而arena没有size idx的概念,这意味着同一个arena,在某个时刻,其托管的内存池集合可能是size class为32字节的内存池,而另一个时刻该内存池可能会被重新划分,变为64字节的block。
内存堆栈分配¶
因为是动态语言,python中的所有变量内容都存在堆(heap)中,而变量名只是堆中内容的引用,存放在栈(stack)中,便于用户去间接操作堆中的数据。
做为对比,以javascript为例,基本数据类型,例如数值、字符串、布尔值,直接存在于栈内;而复合数据类型,例如array、object,存在于堆内,栈内存放的是堆地址的引用
不同数据类型内存使用¶
首先必须要知道id()命令可以用来查看变量在堆中的内存地址,同时==只能用来比较两个变量值的大小,而is可以同时比较内存地址和值。
不可变对象¶
python中的不可变对象包括:
int
float
bool
tuple
string
不可变对象一旦变量名和堆中的某个地址绑定以后,再想修改该变量的值,就会重新再将该变量名和另一个堆地址进行绑定。换句话说,对于5种不可变对象,如果变量的值不同,内存地址一定不同。同一个变量修改内容以后内存地址一定改变。
[小整数和大整数]:
python中将介于-5到256的小整数在堆中分配了独立的缓存区, 也就是说当变量引用这些值的时候,只要值相同,不管引用多少次内存地址一定相同。 而对于另外区间的整数,即使是值相同,多次引用也会创造不同的内存地址。 In[1]:int1=1 In[2]:int2=1 In[3]:id(int1) Out[3]:94569156809600 In[4]:id(int2) Out[4]:94569156809600 In[5]:int3=123456 In[6]:int4=123456 In[7]:id(int3) Out[7]:140692865269264 In[8]:id(int4) Out[8]:140692864485680
[短字符串和长字符串]:
python中对于没有空格的字符串认定为短字符串,类似于小整数,只要内容相同,不管引用多少次地址都一样。 而带了空格的,即使内容相同,多次引用的地址也不同。 需要注意的是,如果是中文,不管有没有空格,地址都是不一样的 In[1]:str1='dfkdjf' In[2]:str2='dfkdjf' In[3]:id(str1) Out[3]:140645071595648 In[4]:id(str2) Out[4]:140645071595648 In[5]:str3='dfkdjf rrr' In[6]:str4='dfkdjf rrr' In[7]:id(str3) Out[7]:140645018745904 In[8]:id(str4) Out[8]:140645018373744
浮点数并没有短长的区分,不同的引用地址一定不同:
In[1]:f1=1.23 In[2]:f2=1.23 In[3]:id(f1) Out[3]:139760803510072 In[4]:id(f2) Out[4]:139760803510144
元组和浮点型一样,地址不同:
In[5]:tup1=(1,2,3) In[6]:tup2=(1,2,3) In[7]:id(tup1) Out[7]:139760792784472 In[8]:id(tup2) Out[8]:139760801764336
布尔值一共就两个,所以相同的值在内存中的地址是不变的
可变对象¶
python中的可变对象包括:
list
dict
set
之所以是可变对象,是因为一旦一个变量和堆中的某个地址绑定,即使修改变量的内容,堆中的地址也不会变了。所以对于3种可变对象,不管值是否相同,不同变量对应的内存地址一定不同,但是同一变量对应的内存地址一定不变。
set集:
In[13]:set1={1,2,3}
In[14]:set2={1,2,3}
In[15]:id(set1)
Out[15]:139760793306952
In[16]:id(set2)
Out[16]:139760793308520
dict字典:
In[17]:dic1={}
In[18]:dic2={}
In[19]:id(dic1)
Out[19]:139760801165384
In[20]:id(dic2)
Out[20]:139760800828368
list列表:
In[22]:list1=[1,2]
In[23]:list2=[1,2]
In[24]:id(list1)
Out[24]:139760801034760
In[25]:id(list2)
Out[25]:139760800576904
而同一变量,即使修改了内容,内存地址还是不变:
In[1]:list1=[1,2]
In[2]:id(list1)
Out[2]:139780650584328
In[3]:list1.append(3)
In[4]:id(list1)
Out[4]:139780650584328
变量名赋值给变量¶
既然python中的变量存储的都是堆中数据的地址,就类似于指针,所以将变量名赋值给另一个变量就相当于将新的变量指向了同一个内存地址。至于修改值以后两个变量的值如何改变,只需要根据上面数据类型的内存地址变换规律去推就好了。
不可变对象a和b指向同一个地址,之后修改a的值,同一变量修改内容后的内存地址不一样
可变对象c和d指向同一个地址,,之后修改c的值,c得地址不会变,还是指向源地址,所以c和d得值都改变了
函数传参¶
传参都是将栈中得变量内容传递到函数内,相当于传递一个指针到函数内,所以在函数内对变量得操作也分为可变对象和不可变对象两种情况。
如果传递的是不可变对象,在函数内得修改只是将变量指向了另一个地址,所以不会影响函数外得变量内容;如果传递得是可变对象,在函数内得修改还是在原地址进行修改,所以还会影响到函数外的变量内容。
备注
补充:用javascript做为对比,js中的基础变量都是直接将值保存在栈内,所以相当于传值给函数,函数内的操作不会影响函数外的变量值。而js中的复合变量同样也是将值保存在堆内,所以相当于传递指针,函数内的操作也会影响到函数外的变量值
总结¶
真实数据都是存储在堆中,栈中的变量都只是存储堆中数据的引用
不可变对象: 其中的小整数、短字符串和布尔值,只要值相同内存地址就相同。其余类型不管值是否相同内存地址都不同
可变对象: 对于单个变量不管值如何变,内存地址都是固定的。但是不同的变量,不管值是否相同,内存地址都不同
传参的时候都是传指针,根据修改内容是否改变内存地址来看看是否会影响到外部变量,不可变对象不影响,可变对象会影响
参考¶
Python内存管理机制: https://www.zhihu.com/column/c_1273568922378719232