b+树¶
B+树为了控制树的高度,只在叶子节点存储数据(这样非叶子节点每一页可以存储更多的关键字,进而很可能不用下沉到叶子节点就能找到我们想要的信息,也大概率减少了寻道次数),当然非叶子节点里面的数据是冗余的,即非叶子节点关键字是由叶子节点里面的关键字中的最小的数组成的.
备注:B+树,是假如为m阶,则每个节点最多会有m个关键字
4阶B+树¶
相关参考¶
链接:
Mongo与MySQL索引对比<index-db>
B-树和B+树的区别¶
1. 时间复杂度¶
B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
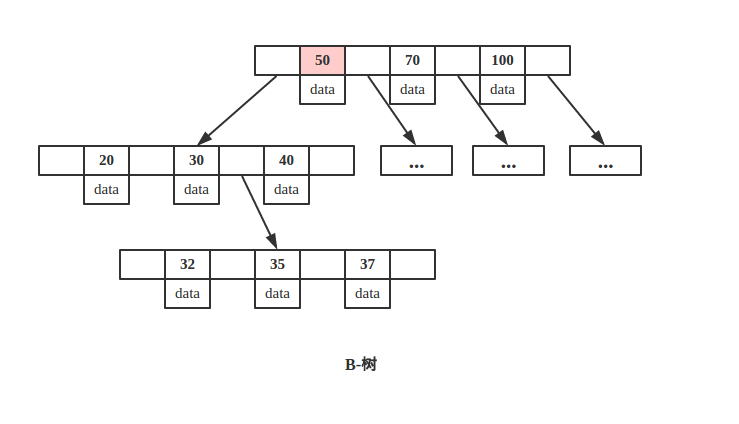
从上图可以看出,key 为 50 的节点就在第一层,B-树只需要一次磁盘 IO 即可完成查找。所以说B-树的查询最好时间复杂度是 O(1)
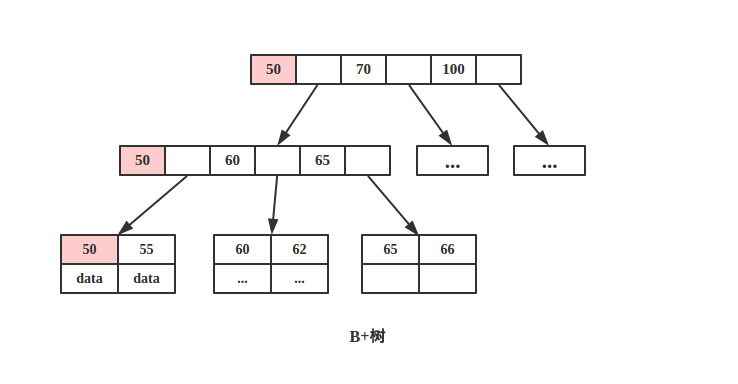
由于B+树所有的 data 域都在根节点,所以查询 key 为 50的节点必须从根节点索引到叶节点,时间复杂度固定为 O(log n)。
2. 区间访问性¶
B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
B+树可以很好的利用局部性原理,若我们访问节点 key为 50,则 key 为 55、60、62 的节点将来也可能被访问,我们可以利用磁盘预读原理提前将这些数据读入内存,减少了磁盘 IO 的次数。 当然B+树也能够很好的完成范围查询。比如查询 key 值在 50-70 之间的节点。
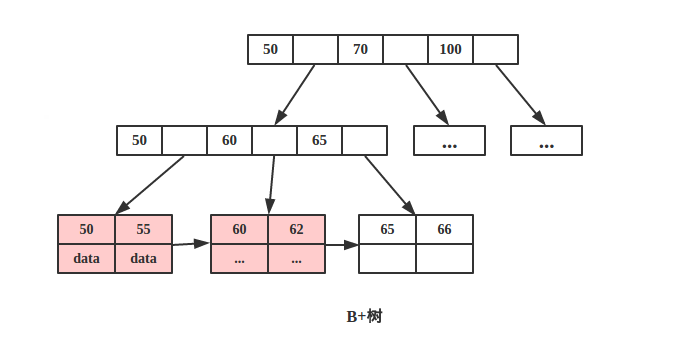
3. 内节点有无data¶
B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
由于B-树节点内部每个 key 都带着 data 域,而B+树节点只存储 key 的副本,真实的 key 和 data 域都在叶子节点存储。前面说过磁盘是分 block 的,一次磁盘 IO 会读取若干个 block,具体和操作系统有关,那么由于磁盘 IO 数据大小是固定的,在一次 IO 中,单个元素越小,量就越大。这就意味着B+树单次磁盘 IO 的信息量大于B-树,从这点来看B+树相对B-树磁盘 IO 次数少