常用¶
开源项目¶
antlr命令¶
Hello.g4:
lexer grammar Hello; //lexer关键字意味着这是一个词法规则文件,名称是Hello,要与文件名相同
//关键字
If : 'if';
Int : 'int';
//字面量
IntLiteral: [0-9]+;
StringLiteral: '"' .*? '"' ; //字符串字面量
//操作符
AssignmentOP: '=' ;
RelationalOP: '>'|'>='|'<' |'<=' ;
Star: '*';
Plus: '+';
Sharp: '#';
SemiColon: ';';
Dot: '.';
Comm: ',';
LeftBracket : '[';
RightBracket: ']';
LeftBrace: '{';
RightBrace: '}';
LeftParen: '(';
RightParen: ')';
//标识符
Id : [a-zA-Z_] ([a-zA-Z_] | [0-9])*;
//空白字符,抛弃
Whitespace: [ \t]+ -> skip;
Newline: ( '\r' '\n'?|'\n')-> skip;
使用:
$ antlr Hello.g4
说明:
让 Antlr 编译规则文件,并生成 Hello.java 文件和其他两个辅助文件
生成的词法分析器(即Hello.class 文件):
$ javac *.java
hello.play:
int age = 45;
if (age >= 17+8+20){
printf("Hello old man!");
}
调用了我们刚才生成的词法分析器,即 Hello 类,打印出对 hello.play 词法分析的结果:
$ grun Hello tokens -tokens hello.play
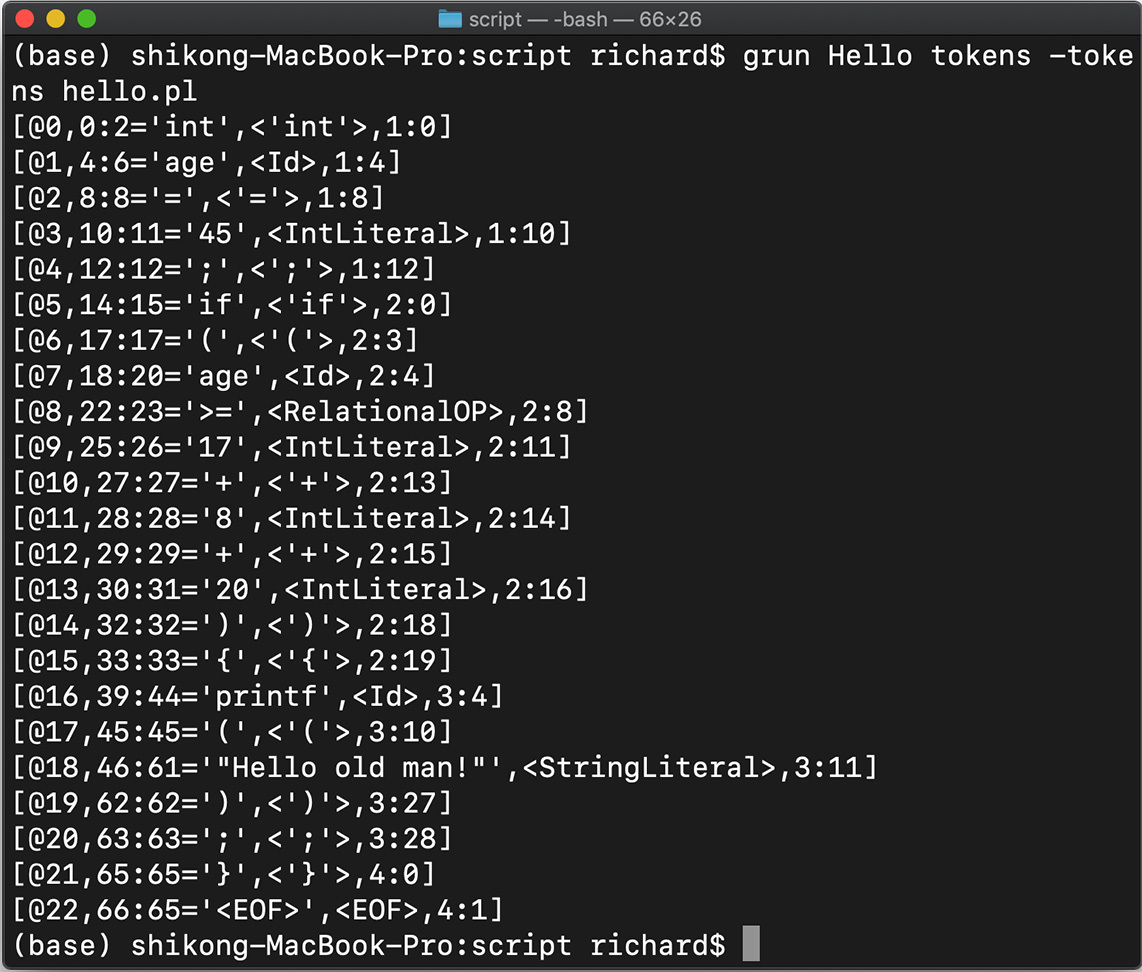
说明(以第二行[@1, 4:6=‘age’,< Id >,1:4]为例):
@1 是 Token 的流水编号,表明这是 1 号 Token;
4:6 是 Token 在字符流中的开始和结束位置;
age 是文本值,
Id 是其 Token 类别;
最后的 1:4 表示这个 Token 在源代码中位于第 1 行、第 4 列
GC¶
推荐你看两个 GC 的源代码:
1. 一个是 Lua 的
2. 一个是 Juila 的
场景¶
1. 监控报警系统,用户可以自定义规则
如 request_timeout > 10s | cpu_usage > 2
2. “低代码开发”或“零代码开发”
通过图形化的界面,进行可视化的编程
参考¶
The Definitive ANTLR 4 Reference: https://github.com/antlr/antlr4/blob/master/doc/index.md
ANTLR SQLite: https://github.com/antlr/grammars-v4/tree/7c2f67b5d042e091ee82344ddfc778aa0dad0f35/sql/sqlite
How Desmos uses Pratt Parsers: https://engineering.desmos.com/articles/pratt-parser/