编译期后端技术¶
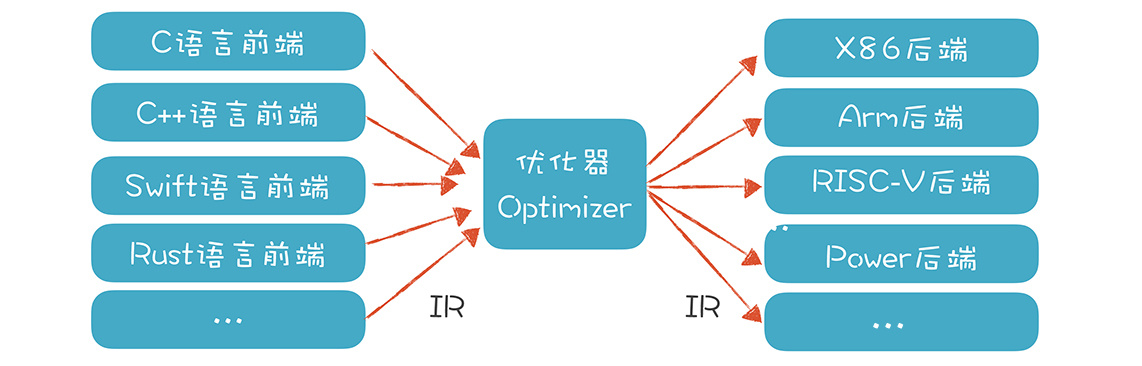
各个语言的前端可以先翻译成 IR,然后再从 IR 翻译成不同硬件架构的汇编代码。如果有 n 个前端语言,m 个后端架构,本来需要做 m*n 个翻译程序,现在只需要 m+n 个了。这就大大降低了总体的工作量。¶
编译器要能够充分利用硬件提供的性能,比如:
1. 寄存器优化
对于频繁访问的变量,最好放在寄存器中,并且尽量最大限度地利用寄存器,不让其中一些空着,
有不少算法是解决这个问题的,教材上一般提到的是染色算法;
2. 充分利用高速缓存
高速缓存的访问速度可以比内存快几十倍上百倍,所以我们要尽量利用高速缓存。
比如,某段代码操作的数据,在内存里尽量放在一起,
这样 CPU 读入数据时,会一起都放到高速缓存中,不用一遍一遍地重新到内存取。
3. 并行性
现代计算机都有多个内核,可以并行计算。
我们的编译器要尽可能把充分利用多个内核的计算能力。
这在编译技术中是一个专门的领域。
4. 流水线
CPU 在处理不同的指令的时候,需要等待的时间周期是不一样的,
在等待某些指令做完的过程中其实还可以执行其他指令。
5. 指令选择
有的时候,CPU 完成一个功能,有多个指令可供选择。
而针对某个特定的需求,采用 A 指令可能比 B 指令效率高百倍。
比如 X86 架构的 CPU 提供 SIMD 功能,也就是一条指令可以处理多条数据,
而不是像传统指令那样一条指令只能处理一条数据。
在内存计算领域,SIMD 也可以大大提升性能
6. 其他优化
比如可以针对专用的 AI 芯片和 GPU 做优化,提供 AI 计算能力
前端和后端的区别:
前端关注的是正确反映了代码含义的静态结构
后端关注的是让代码良好运行的动态结构
作用域是前端的概念
而生存期是后端的概念
优化思路——数据的局部性:
写程序时,尽量把某个操作所需的数据都放在内存中的连续区域中,不要零零散散地到处放,
这样有利于充分利用高速缓存
在现在操作系统中,是每个线程一个栈。如果一个进程里面有多个线程,那就有多个栈。
另外,如果程序是支持协程的,有些实现机制也会给协程提供单独的栈,用来维护协程的状态。
但协程的栈一般是由程序的运行时或库来支持的,而不是由操作系统来维护的。