可靠事件队列¶
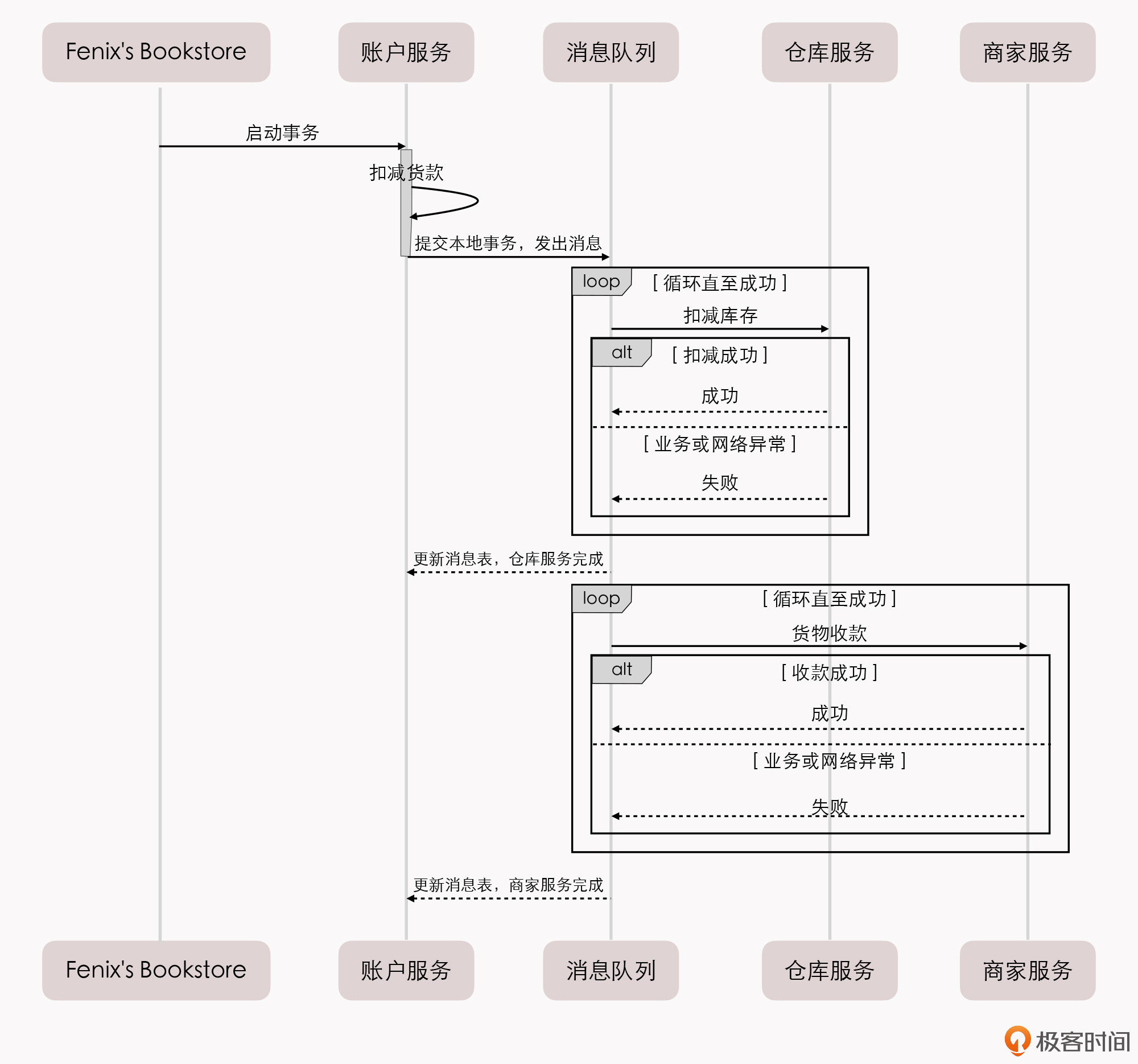
可靠事件队列时序图¶
操作步骤:
1. 最终用户向 Fenix's Bookstore 发送交易请求:购买一本价值 100 元的《深入理解 Java 虚拟机》
2. Fenix's Bookstore 应该对用户账户扣款、商家账户收款、库存商品出库这三个操作有一个出错概率的先验评估
根据出错概率的大小来安排它们的操作顺序(这个一般体现在程序代码中,有一些大型系统也可能动态排序)
比如:
最有可能出错的地方,是用户购买了,但是系统不同意扣款,或者是账户余额不足;
其次是商品库存不足;
最后是商家收款一般不会遇到什么意外
最后的顺序就应该是最容易出错的最先进行,即:账户扣款 → 仓库出库 → 商家收款
3. 账户服务进行扣款业务
如果扣款成功,就在自己的数据库建立一张消息表,里面存入一条消息:
事务 ID:UUID;
账户扣款:100 元(状态:已完成);
仓库出库《深入理解 Java 虚拟机》:1 本(状态:进行中)
某商家收款:100 元(状态:进行中)
注意:
这个步骤中 “扣款业务” 和 “写入消息” 是依靠同一个本地事务写入自身数据库的
4. 系统建立一个消息服务
定时轮询消息表,将状态是 “进行中” 的消息同时发送到库存和商家服务节点中去
定时轮询过程会产生以下几种情况:
1. 商家和仓库服务成功完成了收款和出库工作, 向用户账户服务器返回成功执行结果
用户账户服务把消息状态从 “进行中” 更新为 “已完成”
整个事务宣告顺利结束,达到最终一致性的状态
2. 商家或仓库服务有某些或全部因网络原因,未能收到来自用户账户服务的消息
此时,由于用户账户服务器中存储的消息状态,一直处于 “进行中”
所以消息服务器将在每次轮询的时候,持续地向对应的服务重复发送消息
注意:
所有被消息服务器发送的消息都必须具备幂等性
通常我们的设计是让消息带上一个唯一的事务 ID,以保证一个事务中的出库、收款动作只会被处理一次
3. 商家或仓库服务有某个或全部无法完成工作
比如仓库发现《深入理解 Java 虚拟机》没有库存了
此时,仍然是持续自动重发消息,直至操作成功(比如补充了库存),或者被人工介入为止
4. 商家和仓库服务成功完成了收款和出库工作,但回复的应答消息因网络原因丢失
此时,用户账户服务仍会重新发出下一条消息,但因消息幂等,所以不会导致重复出库和收款
只会导致商家、仓库服务器重新发送一条应答消息。
此过程会一直重复,直至双方网络恢复。
说明:
有一些支持分布式事务的消息框架,如 RocketMQ
原生就支持分布式事务操作,这时候前面提到的情况 2、4 也可以交给消息框架来保障
备注
这种靠着持续重试来保证可靠性的操作,在计算机中就非常常见,它有个专门的名字,叫做 “最大努力交付”(Best-Effort Delivery),比如 TCP 协议中的可靠性保障,就属于最大努力交付。
备注
『可靠事件队列』被称为 “最大努力一次提交”(Best-Effort 1PC),意思就是系统会把最有可能出错的业务,以本地事务的方式完成后,通过不断重试的方式(不限于消息系统)来促使同个事务的其他关联业务完成。
缺点:
可靠消息队列的整个实现过程完全没有任何隔离性可言