并发相关-CAP¶
备注
CAP是解决FLP定理的问题,提出的一种Trade-off方式解决分布式问题,通过对系统主要设计指标进行一定的妥协,来设计出一个理论上可行的、可以满足实际需求的分布式系统
备注
CAP 理论的作者已经重新解释了很多人对 CAP 的误解,C A P 三者并不是互斥关系只能选其二,而是在出现网络分区时,可以选择 0.9 + 0.9 + 0.7 之类的措施,在三者间进行平衡取舍。
备注
CAP 是要求各个节点都可以提供读写操作,而不是只做备份复制。但现在大部分的分布式中间件实现基本都是一主多从架构,只有主节点才会接收写请求,主从节点都能接收读请求。而且很多一致性算法都是设定只有主节点才接收写请求,然后把数据同步到从节点。这样做是通过限制主才能写来避免数据一致性问题,但是复杂度转移到如何选举主上去了,但大家普遍认为选举比数据一致性要简单一些。
分布式系统理论基础 - CAP¶
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer’s theorem),是加州大学伯克利分校的计算机科学家埃里克・布鲁尔(Eric Brewer)在2000年PODC会议上提出,是Eric Brewer在Inktomi期间研发搜索引擎、分布式web缓存时得出的关于数据一致性(consistency)、服务可用性(availability)、分区容错性(partition-tolerance)的猜想:
- It is impossible for a web service to provide the three following guarantees :
Consistency, Availability and Partition-tolerance.
2002 年,麻省理工学院的赛斯・吉尔伯特(Seth Gilbert)和南希・林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。
CAP:
数据一致性(consistency)
服务可用性(availability)
分区容错性(partition-tolerance)
一份数据在多个节点有但不是所有节点都有,这是非对称集群;例如 ES
所有数据在所有节点都有,这是对称集群,例如 zookeeper
各类定义¶
https://console.bluemix.net/docs/services/Cloudant/guides/cap_theorem.html:
Consistency
where all nodes see the same data at the same time.
Availability
which guarantees that every request receives a response about whether it succeeded or failed.
Partition tolerance
where the system continues to operate even if any one part of the system is lost or fails.
https://en.wikipedia.org/wiki/CAP_theorem#cite_note-Brewer2012-6:
Consistency
Every read receives the most recent write or an error.
Availability
Every request receives a (non-error) response
– without guarantee that it contains the most recent write.
Partition tolerance
The system continues to operate despite an arbitrary number of messages
being dropped (or delayed) by the network between nodes.
https://www.teamsilverback.com/understanding-the-cap-theorem/:
Consistency
all nodes have access to the same data simultaneously.
Availability
a promise that every request receives a response,
at minimum whether the request succeeded or failed.
Partition tolerance
the system will continue to work
even if some arbitrary node goes offline or can’t communicate.
数据一致性(consistency):
如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;
如果返回失败,那么所有读操作都不能读到这个数据
对调用者而言数据具有强一致性(strong consistency)
(又叫原子性 atomic、线性一致性 linearizable consistency)
代表在任何时刻、任何分布式节点中,我们所看到的数据都是没有矛盾的。
服务可用性(availability):
所有读写请求在一定时间内得到响应,可终止、不会一直等待
代表系统不间断地提供服务的能力。
分区容错性(partition-tolerance):
在网络分区的情况下,被分隔的节点仍能正常对外服务
代表分布式环境中,当部分节点因网络原因而彼此失联(即形成 “网络分区”)时,系统仍能正确地提供服务的能力
Robert Greiner版¶
Any distributed system cannot guaranty C, A, and P simultaneously.
In a distributed system (a collection of interconnected nodes that share data.),
you can only have two out of the following three guarantees across a write/read pair:
Consistency, Availability, and Partition Tolerance - one of them must be sacrificed.
对比两个版本的定义,有几个很关键的差异点:
1. 第二版定义了什么才是 CAP 理论探讨的分布式系统,强调了两点:interconnected 和 share data
因为分布式系统并不一定会互联和共享数据:
如 Memcache 的集群,相互之间就没有连接和共享数据,因此这类分布式系统就不符合 CAP 理论探讨的对象
而 MySQL 集群就是互联和进行数据复制的,因此是 CAP 理论探讨的对象
2. 第二版强调了 write/read pair,这点其实是和上一个差异点一脉相承的
也就是说,CAP 关注的是对数据的读写操作,而不是分布式系统的所有功能
例如,ZooKeeper 的选举机制就不是 CAP 探讨的对象
一. 一致性(Consistency):
第一版解释:
All nodes see the same data at the same time.
第二版解释:
A read is guaranteed to return the most recent write for a given client.
主要差异点表现在:
1. 第一版从节点 node 的角度描述,第二版从客户端 client 的角度描述
相比来说,第二版更加符合我们观察和评估系统的方式,即站在客户端的角度来观察系统的行为和特征
2. 第一版的关键词是 see,第二版的关键词是 read
第一版解释中的 see,其实并不确切,因为节点 node 是拥有数据,而不是看到数据
第二版从客户端 client 的读写角度来描述一致性,定义更加精确
3. 第一版强调同一时刻拥有相同数据(same time + same data),第二版并没有强调这点
这就意味着实际上对于节点来说,可能同一时刻拥有不同数据(same time + different data)
对于系统执行事务来说,在事务执行过程中,系统其实处于一个不一致的状态,不同的节点的数据并不完全一致
二. 可用性(Availability):
第一版解释:
Every request gets a response on success/failure.
第二版解释:
A non-failing node will return a reasonable response
within a reasonable amount of time (no error or timeout).
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)
主要差异点表现在:
1. 第一版是 every request,第二版强调了 A non-failing node
第一版的 every request 是不严谨的,因为只有非故障节点才能满足可用性要求
如果节点本身就故障了,发给节点的请求不一定能得到一个响应
2. 第一版的 response 分为 success 和 failure,第二版用了两个 reasonable
reasonable response 和 reasonable time,而且特别强调了 no error or timeout
分区容忍性(Partition Tolerance):
第一版解释: System continues to work despite message loss or partial failure. 第二版解释: The system will continue to function when network partitions occur.
主要差异点表现在:
1. 第一版用的是 work,第二版用的是 function
work 强调 “运行”,只要系统不宕机,可以说系统在 work,返回错误也是 work,拒绝服务也是 work
而 function 强调 “发挥作用”“履行职责”,这点和可用性是一脉相承的
也就是说,只有返回 reasonable response 才是 function。相比之下,第二版解释更加明确
2. 第一版描述分区用的是 message loss or partial failure,第二版直接用 network partitions
分区现象: 可能是丢包,也可能是连接中断,还可能是拥塞
一致性¶
从强到弱:
1. 线性一致性
2. 顺序一致性
3. 因果一致性
4. 单调一致性
5. 最终一致性
线性一致性(Linearizability Consistency):
Maurice P. Herlihy 与 Jeannette M. Wing 在 1990 年经典论文《Linearizability: A Correctness Condition for Concurrent Objects》中共同提出, 在顺序一致性前提下加强了进程间的操作排序,形成唯一的全局顺序(系统等价于是顺序执行,所有进程看到的所有操作的序列顺序都一致,并且跟实际发生顺序一致),是很强的原子性保证。 但是比较难实现,目前基本上要么依赖于全局的时钟或锁,要么通过一些复杂算法实现,性能往往不高。 https://en.wikipedia.org/wiki/Linearizability 解读: 就是有一个全局的时间轴,每一个操作都对应到时间轴上的一个时间点,所有客户端看到的都是这个时间轴上的顺序。
顺序一致性(Sequential Consistency)
Leslie Lamport 1979 年经典论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》中提出, 是一种比较强的约束,保证所有进程看到的 全局执行顺序(total order)一致,并且每个进程看自身的执行(local order)跟实际发生顺序一致。 例如,某进程先执行 A,后执行 B,则实际得到的全局结果中就应该为 A 在 B 前面,而不能反过来。 同时所有其它进程在全局上也应该看到这个顺序。 顺序一致性实际上限制了各进程内指令的偏序关系,但不在进程间按照物理时间进行全局排序。 https://en.wikipedia.org/wiki/Sequential_consistency
解读: 没有全局的时间轴,而是每个变量对应一个时间轴,所有客户端看同一个变量在时间轴上的顺序一致。
因果一致性:
是有因果关系的操作对应一个时间轴。 比如,对不同变量的读写之间、对同一变量的读之间,都是没有因果关系的。 但是对于同一个变量的写、与此后对这个变量的读,是有因果关系的。
单调一致性:
todo最终一致性(eventual consistency)
放宽对时间的要求,在被调完成操作响应后的某个时间点,被调多个节点的数据最终达成一致
CAP 关键细节点¶
重要
埃里克・布鲁尔(Eric Brewer)在 《CAP 理论十二年回顾:“规则” 变了》 一文中详细地阐述了理解和应用 CAP 的一些细节点
一. CAP 关注的粒度是数据,而不是整个系统:
C 与 A 之间的取舍可以在同一系统内以非常细小的粒度反复发生,
而每一次的决策可能因为具体的操作,乃至因为牵涉到特定的数据或用户而有所不同。
CAP 理论的定义和解释中,用的都是 system、node 这类系统级的概念,这就给很多人造成了很大的误导,
认为我们在进行架构设计时,整个系统要么选择 CP,要么选择 AP
但在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据选择 CP,有的数据选择 AP
以一个最简单的用户管理系统为例:
用户管理系统包含用户账号数据(用户 ID、密码)、用户信息数据(昵称、兴趣、爱好、性别、自我介绍等)
通常情况下,用户账号数据会选择 CP,而用户信息数据会选择 AP
所以在 CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类
每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
二. CAP 是忽略网络延迟的:
这是一个非常隐含的假设,布鲁尔在定义一致性时,并没有将延迟考虑进去。
也就是说,当事务提交时,数据能够瞬间复制到所有节点。
但实际情况下,从节点 A 复制数据到节点 B,总是需要花费一定时间的
这意味着,CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点 A 和 B 的数据并不一致
而业务上要求一致性,因此用户的余额、商品的库存,理论上要求选择 CP 而实际做不到 CP,只能选择 CA
也就是说,只能单点写入,其他节点做备份,无法做到分布式情况下多点写入
需要注意的是,这并不意味着这类系统无法应用分布式架构
只是说 “单个用户余额、单个商品库存” 无法做分布式,但系统整体还是可以应用分布式架构的
三. 正常运行情况下,不存在 CP 和 AP 的选择,可以同时满足 CA:
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了 “分区” 现象。
如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),
我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,
这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA
同样以用户管理系统为例,即使是实现 CA,不同的数据实现方式也可能不一样:
用户账号数据可以采用 “消息队列” 的方式来实现 CA
因为消息队列可以比较好地控制实时性,但实现起来就复杂一些
而用户信息数据可以采用 “数据库同步” 的方式来实现 CA
因为数据库的方式虽然在某些场景下可能延迟较高,但使用起来简单
四. 放弃并不等于什么都不做,需要为分区恢复后做准备:
在分区过程中我们无法保证 C 或者 A,但并不意味着什么都不做
因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长
例如,99.99% 可用性(俗称 4 个 9)的系统,一年运行下来,不可用的时间只有 50 分钟
区期间放弃 C 或者 A,并不意味着永远放弃 C 和 A
我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到 CA 的状态
最典型的就是在分区期间记录一些日志:
当分区故障解决后,系统根据日志进行数据恢复,使得重新达到 CA 状态
1. 以用户管理系统为例,对于用户账号数据,假设我们选择了 CP:
则分区发生后,节点 1 可以继续注册新用户,节点 2 无法注册新用户
这里就是不符合 A 的原因,因为节点 2 收到注册请求后会返回 error
此时节点 1 可以将新注册但未同步到节点 2 的用户记录到日志中
当分区恢复后,节点 1 读取日志中的记录,同步给节点 2
当同步完成后,节点 1 和节点 2 就达到了同时满足 CA 的状态
2. 对于用户信息数据,假设我们选择了 AP:
则分区发生后,节点 1 和节点 2 都可以修改用户信息,但两边可能修改不一样
例如:
用户在节点 1 中将爱好改为 “旅游、美食、跑步”
用户在节点 2 中将爱好改为 “美食、游戏”
节点 1 和节点 2 都记录了未同步的爱好数据,当分区恢复后,系统按照某个规则来合并数据
例如:
按照 “最后修改优先规则” 将用户爱好修改为 “美食、游戏”
按照 “字数最多优先规则” 则将用户爱好修改为 “旅游,美食、跑步”
也可以完全将数据冲突报告出来,由人工来选择具体应该采用哪一条
BASE/ACID¶
ACID¶
ACID 中的 C 和 CAP 中的 C 名称虽然都是一致性,但含义完全不一样。ACID 中的 C 是指数据库的数据完整性,而 CAP 中的 C 是指分布式节点中的数据一致性。再结合 ACID 的应用场景是数据库事务,CAP 关注的是分布式系统数据读写。
BASE¶
备注
BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。
CAP 理论和 BASE 相关的两点:
1. CAP 理论是忽略延时的,而实际应用中延时是无法避免的
完美的 CP 场景是不存在的,即使是几毫秒的数据复制延迟
在这几毫秒时间间隔内,系统是不符合 CP 要求的
因此 CAP 中的 CP 方案,实际上也是实现了最终一致性,只是 “一定时间” 是指几毫秒而已
2. AP 方案中牺牲一致性只是指分区期间,而不是永远放弃一致性
这一点其实就是 BASE 理论延伸的地方,分区期间牺牲一致性,
但分区故障恢复后,系统应该达到最终一致性。
备注
ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。
CAP的取舍¶
说明:
1. 在某时刻如果满足AP,分隔的节点同时对外服务但不能相互通信,将导致状态不一致,即不能满足C
2. 如果满足CP,网络分区的情况下为达成C,请求只能一直等待,即不满足A
3. 如果要满足CA,在一定时间内要达到节点状态一致,要求不能出现网络分区,则不能满足P
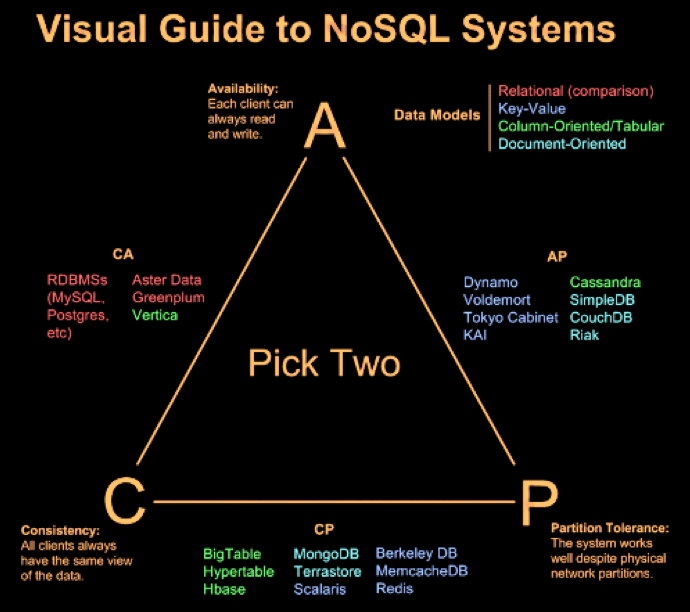
知名分布式系统的主场景设计权衡¶
CAP定理能够将这些一致性算法的集合进行归类:
C+A: CA without P
以2阶段提交(2 phase commit)为代表的严格选举协议。
当通信中断时算法不具有终止性(即不具备分区容忍性);
C+P: 以Paxos、Raft为代表的多数派选举算法。
当不可用的执行过程超过半数时,算法无法得到正确结果(即会出现不可用的情况);
A+P: 以Gossip协议为代表的冲突解决协议。
当网络分区存在和执行过程正确时,只能等待分区消失才保持一致性(即不具备强一致性)
CA without P:
假设节点之间的通讯永远是可靠的
可是永远可靠的通讯在分布式系统中必定是不成立的,这不是你想不想的问题,而是网络分区现象始终会存在
所以『CA without P』处理的是非分布式问题,如: 传统的单机数据库
实例:
主流的 RDBMS(关系数据库管理系统)集群通常就是采用放弃分区容错性的工作模式。
以 Oracle 的 RAC 集群为例:
它的每一个节点都有自己的 SGA(系统全局区)、重做日志、回滚日志等,
但各个节点是共享磁盘中的同一份数据文件和控制文件的,
也就是说,RAC 集群是通过共享磁盘的方式来避免网络分区的出现。
CP without A:
假设一旦发生分区,节点之间的信息同步时间可以无限制地延长
相当于退化到全局事务的场景,即一个系统可以使用多个数据源
可以通过 2PC/3PC 等手段,同时获得分区容错性和一致性。
实例:
1. DTP 模型的分布式数据库事务
2. 著名的 HBase 也是属于 CP 系统
假如某个 RegionServer 宕机了,这个 RegionServer 持有的所有键值范围都将离线
直到数据恢复过程完成为止,这个时间通常会是很长的
AP without C:
假设一旦发生分区,节点之间所提供的数据可能不一致
AP 系统目前是分布式系统设计的主流选择
实例:
大多数的 NoSQL 库和支持分布式的缓存都是 AP 系统
以 Redis 集群为例:
如果某个 Redis 节点出现网络分区,那也不妨碍每个节点仍然会以自己本地的数据对外提供服务。
但这时有可能出现这种情况,即请求分配到不同节点时,返回给客户端的是不同的数据
原因:
P 是分布式网络的天然属性,你不想要也无法丢弃
A 通常是建设分布式的目的
备注
基于CAP定理,我们需要根据不同场景的不同业务要求来进行算法上的权衡。对于分布式存储系统来说,网络连接故障是无法避免的。在设计分布系统时不得不考虑分区容忍性,所以我们实际上只能在一致性和可用性之间进行权衡。
备注
特别值得一提的经典设计范例是阿里巴巴的OceanBase系统。它将数据分为了冷数据和热数据两个不同的场景。对于冷数据,规定只读不写。这样就不需要处理分布式写操作带来的一致性问题,只需保证可用性和分区容忍性即可(即AP场景)。而对于新增的热数据,由于用户需要频繁访问,所以采取不同的服务器分片进行服务,本地读写的模式,不需要考虑网络分区的问题(即CA场景)。通过对CAP定理的深刻理解和灵活运用,构建出了满足高并发读写、处理海量金融数据的分布式数据库。
实例讲解CAP¶
事例场景:
Fenix's Bookstore 是一个在线书店。
一份商品成功售出,需要确保以下三件事情被正确地处理:
1. 账号服务: 用户的账号扣减相应的商品款项;
2. 仓库服务: 商品仓库中扣减库存,将商品标识为待配送状态;
3. 商家服务: 商家的账号增加相应的商品款项。
分布式场景: 每一个服务都有多个节点,每一个服务都有着自己的数据库
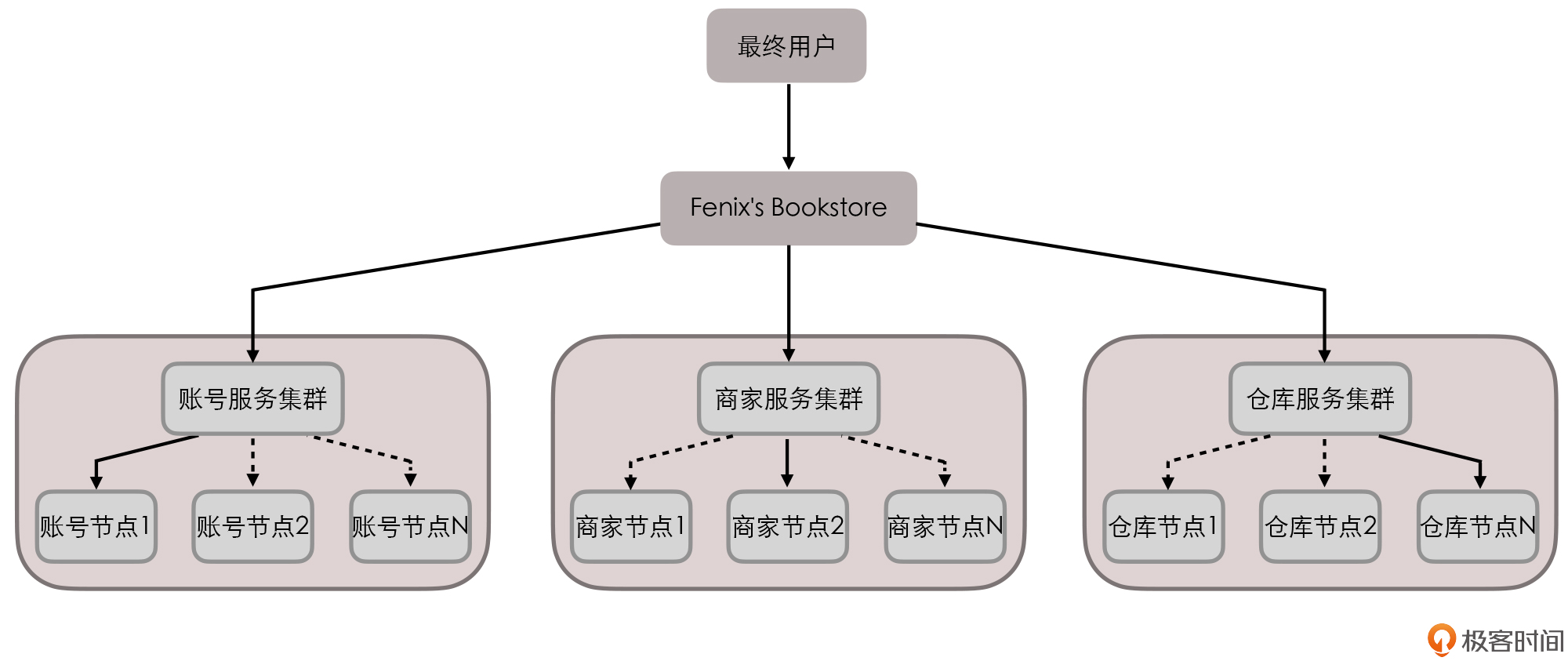
Fenix’s Bookstore 的服务拓扑¶
操作:
假设某次交易请求分别由 “账号节点 1”“商家节点 2”“仓库节点 N” 来进行响应
当用户购买一件价值 100 元的商品后:
1. 账号节点 1 首先应该给用户账号扣减 100 元货款
2. 账号节点 1 在自己的数据库扣减 100 元后,还要把这次交易变动告知账号节点 2 到 N
以及确保能正确变更『商家集群』和『仓库集群』其他账号节点中的关联数据
此时,我们可能会面临以下几种情况:
1. 一致性问题:
如果该变动信息没有及时同步给其他账号节点,
那么当用户购买其他商品时,会被分配给另一个节点处理,
因为没有及时同步,此时系统会看到用户账户上有不正确的余额,从而错误地发生了原本无法进行的交易。
2. 可用性问题:
要把该变动信息同步给其他账号节点,就必须暂停对该用户的交易服务,直到数据同步一致后再重新恢复
那么当用户在下一次购买商品时,可能会因为系统暂时无法提供服务而被拒绝交易。
3. 分区容忍性问题:
如果由于账号服务集群中某一部分节点,因出现网络问题,无法正常与另一部分节点交换账号变动信息
那么此时的服务集群中,无论哪一部分节点对外提供的服务,都可能是不正确的
我们需要考虑能否接受由于部分节点之间的连接中断,而影响整个集群的正确性的情况。
备注
以上还只是涉及到了账号服务集群自身的 CAP 问题,而对于整个 Bookstore 站点来说,它更是面临着来自于账号、商家和仓库服务集群带来的 CAP 问题。
整个 Bookstore 站点面临的CAP问题:
1. 用户账号扣款后,由于没有及时通知仓库服务
导致另一次交易中看到仓库中有不正确的库存数据而发生了超售
一致性问题
2. 因仓库中某商品的交易正进行中,为同步用户、商家和仓库此时的交易变动
而暂时锁定该商品的交易服务
可用性问题
其他¶
Las Vegas” algorithms(这个算法又叫撞大运算法,其保证结果正确,只是在运算时所用资源上进行赌博。一个简单的例子是随机快速排序,它的 pivot 是随机选的,但排序结果永远一致)在每一轮皆有一定机率达成共识,随着时间增加,机率会越趋近于 1。而这也是许多成功的共识演算法会采用的解决办法。
参考¶
数据一致性、服务可用性、分区容错性: https://app.yinxiang.com/fx/12b8f4c1-b55e-4368-a1c3-cc57265df5b1
【极客时间】分布式事务: https://time.geekbang.org/column/article/322287
分布式系统 CAP 理论深入探索和分析: https://blog.csdn.net/u014645192/article/details/90695205
【维基】CAP定理: https://en.wikipedia.org/wiki/CAP_theorem