对现有系统做微服务化改造¶
相比从头开始落地服务,对现有系统做微服务化改造,面临更多的挑战:
1. 应用和数据表紧密耦合在一起,代码模块和表是多对多的依赖关系
一个模块会访问多张表,多个模块也会对同一张表进行访问
而且由于表都在一个数据库里,开发人员往往会随意对表做关联,有时候甚至 Join 5~6 张表以上
这样,代码模块和表之间的关系是剪不断,理还乱
我们很难清晰地划分代码和数据表的边界,也就很难把它们封装成独立的微服务
2. 如何保证系统的平滑过渡
系统现在已经在运行了,我们的改造不能影响业务的稳定性
微服务落地后,现有的系统要怎么对接微服务,数据要怎么迁移
应对这些挑战:
1. 要保证比较合理的服务设计,才能达到优化系统架构的目的
2. 要做到整个过程对现有系统的影响比较小,才能达到系统改造顺利落地的目的
单体系统的维护带来了一系列的问题:
1. 从应用方面来说,各个系统功能重复建设
比如:很多系统都会直接访问库存相关的表,类似的库存逻辑散布在很多地方
另外,如果修改了库存表的某个字段,这些系统同时会受影响,正所谓牵一发而动全身
2. 从数据库方面来说,数据库的可用性是比较差的
如果某个系统有慢查询,它就很可能拖垮整个产品数据库,导致它不可用
还有,这么多系统同时访问产品库,数据库的连接数也经常不够用
微服务改造过程¶
选择要改造的服务:
这里涉及了多个微服务,如果同时进行服务化改造的话,牵扯太大,很难落地。
于是,我们选择从库存微服务开始:
1. 库存的业务很重要,库存的规则也比较复杂,如果我们能够对库存逻辑进行优化,这会带来明显的业务价值
2. 电商的库存概念相对独立,涉及的表也比较少,我们可以相对容易地把它从现有体系中剥离出来
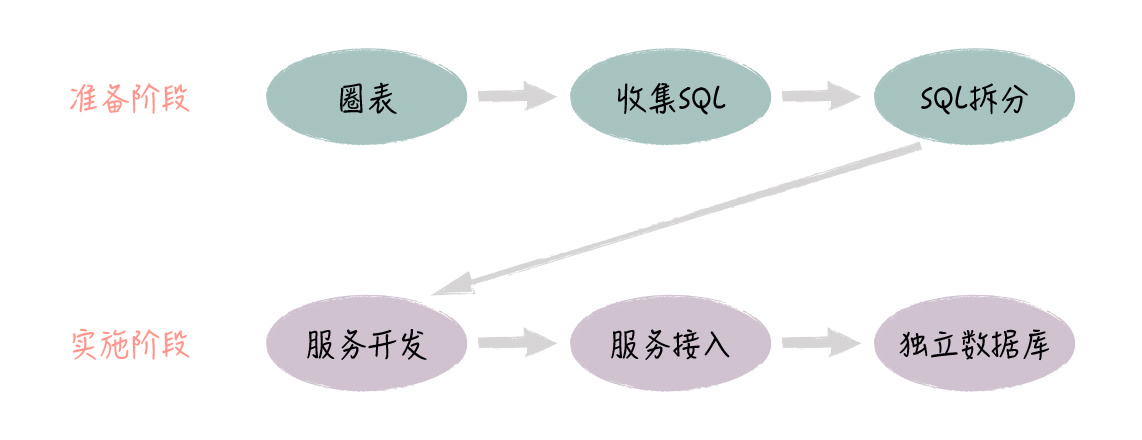
整个改造过程,一共分为两个阶段:
1. 准备阶段
这个阶段为微服务改造做好前期的准备工作,具体步骤包括了:
a. 圈表
b. 收集 SQL
c. SQL 拆分
2. 实施阶段
这个阶段实际落地微服务,具体步骤包括:
a. 微服务开发
b. 服务接入
c. 数据库独立
准备阶段¶
1. 圈表¶
圈表就是用来确定库存微服务具体包含哪些表,也就是确定服务的数据模型:
在确定了表以后,库存微服务就负责这些表的访问:
1. 库存微服务也不会访问其它的表
2. 而业务系统后续将通过库存微服务的接口,实现对这些表的访问
圈表是微服务改造中比较有挑战性的地方:
它实际上对应了服务的边界划分
只是针对老系统做服务化改造的时候,更多的是从数据库表的角度来考虑划分,这样更好落地
要求:
1. 要满足所有的库存访问需求,这些表之间关系紧密,和其它的表关联不大
2. 这些表的数量不能太多,一般不超过十几张
这样,我们既容易拆分数据库,又能控制服务的粒度,保证功能聚焦
重要
在微服务改造中,确定哪些表属于这个服务,会直接影响后续的所有改造工作,这需要有经验的业务架构师和数据架构师参与进来,通过深入地分析现有的业务场景和表的关系,才能对库表进行合理的划分。
对现有系统的改造,服务的边界划分主要是从圈表入手的,而不是从一个服务应该有哪些功能入手的,这一点和新服务设计是有所不同的。这有两方面原因:
1. 如果确定了服务包含哪些表,也就大致确定了服务有哪些功能
而表是现成的,它比业务功能要直观很多,所以从表入手比较高效
2. 如果从表入手,构造的服务和表是对应的,服务包含的是完整的表
不会产生一个表的一部分字段属于库存服务,而另一部分字段属于别的服务的情况
避免表字段的拆分带来额外的复杂性
备注
因为这是对现有系统的改造,为了避免一下子引入太多变化,我们先不对库存的表结构进行调整,表结构的优化可以放在服务的升级版里做,这样对业务系统的影响也最小
2. 收集 SQL¶
在确定了哪些表属于库存服务后,我们会收集所有业务系统访问这些表的 SQL 语句:
包括它的业务场景说明、访问频率等等。
库存微服务后续就针对这些 SQL 进行封装,提供相应的接口给业务系统使用。
这里,服务开发团队负责提供 SQL 收集的 Excel 模板,各业务系统开发团队负责收集具体的 SQL。
3. 拆分 SQL¶
对于收集过来的 SQL 语句,有些 SQL 不仅仅访问圈定的这几张库存表,还会和产品库中的其他表进行关联。
对于这样的 SQL 语句,我们就要求各个业务团队先进行拆分,保证最后提供给服务开发团队的 SQL,只包含访问库存的相关表。通过 SQL 拆分,我们切断了库存表和其他表的直接联系,等后面微服务落地后,业务系统就可以通过接入微服务,完成现有 SQL 的替换。 SQL 拆分,会涉及一定的业务系统改造,这部分工作主要由各个研发团队负责,一般情况下,性能可能会受些影响,但问题不是很大。
实施阶段¶
4. 构建微服务¶
包括:
接口设计、代码开发、功能测试等步骤
对业务方提供的 SQL 进行梳理,然后对接口做一定的通用化设计,
避免为每个 SQL 定制一个单独的接口,以此保证服务的复用能力
这部分工作由微服务开发团队负责:
第一版的服务主要是:
1. 做好接口设计
2. 聚焦业务功能
以保证服务能够落地,业务系统能够顺利对接为目标
将来:
服务可以持续迭代,内部做各种技术性优化,
只要服务的接口保持不变,就不会影响业务系统
5. 接入微服务¶
库存服务经过功能和性能验证以后,会由各个业务开发团队逐步接入,替换原来的 SQL 语句。
备注
这部分工作主要由业务研发团队负责,难度不大,但需要耗费比较多的时间。
6. 数据库独立¶
备注
当服务接入完成,所有的 SQL 语句都被替换后,业务系统已经不会直接访问这些库存的表。这时,我们就可以把库存相关的表,从原来的产品库中迁移出来,部署成为一个物理上独立的数据库。业务系统是通过服务来访问数据库的,因此,这个数据迁移对于业务系统来说是透明的,业务团队甚至都不用关心这些表的新位置。
通过库存表独立成库,我们可以从物理层面,切断业务团队对这些表的依赖,同时,也可以大幅度降低产品库的压力,特别是大促的时候,库存读写压力是非常大的,数据库独立也为库存服务后续的技术优化打下了基础。
备注
这部分工作主要由微服务开发团队和 DBA 一起配合完成,主要是要避免业务系统还有遗漏的 SQL 语句,避免它们还在直接访问库存的表。我们可以在迁库前,通过代码扫描做好相应的检查工作。
总结¶
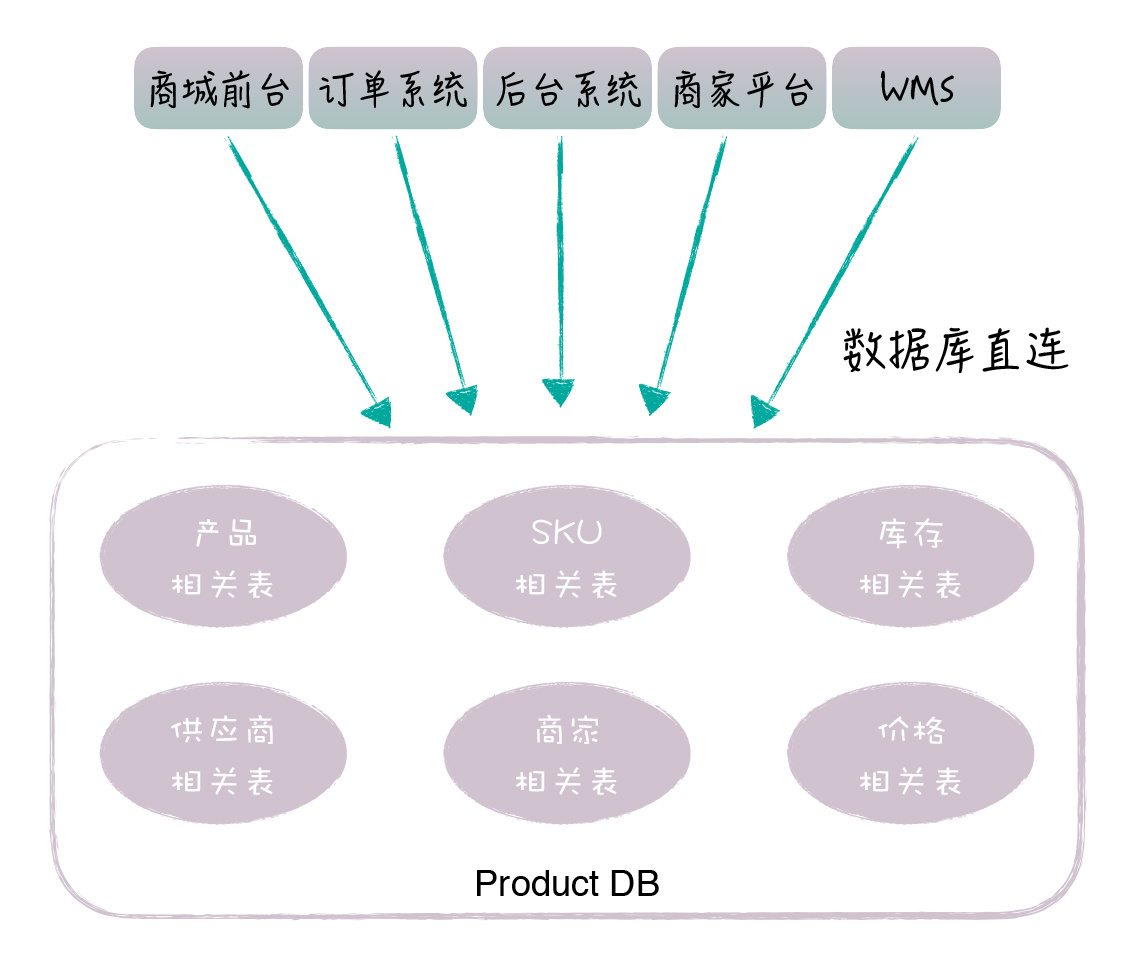
改造前架构图¶
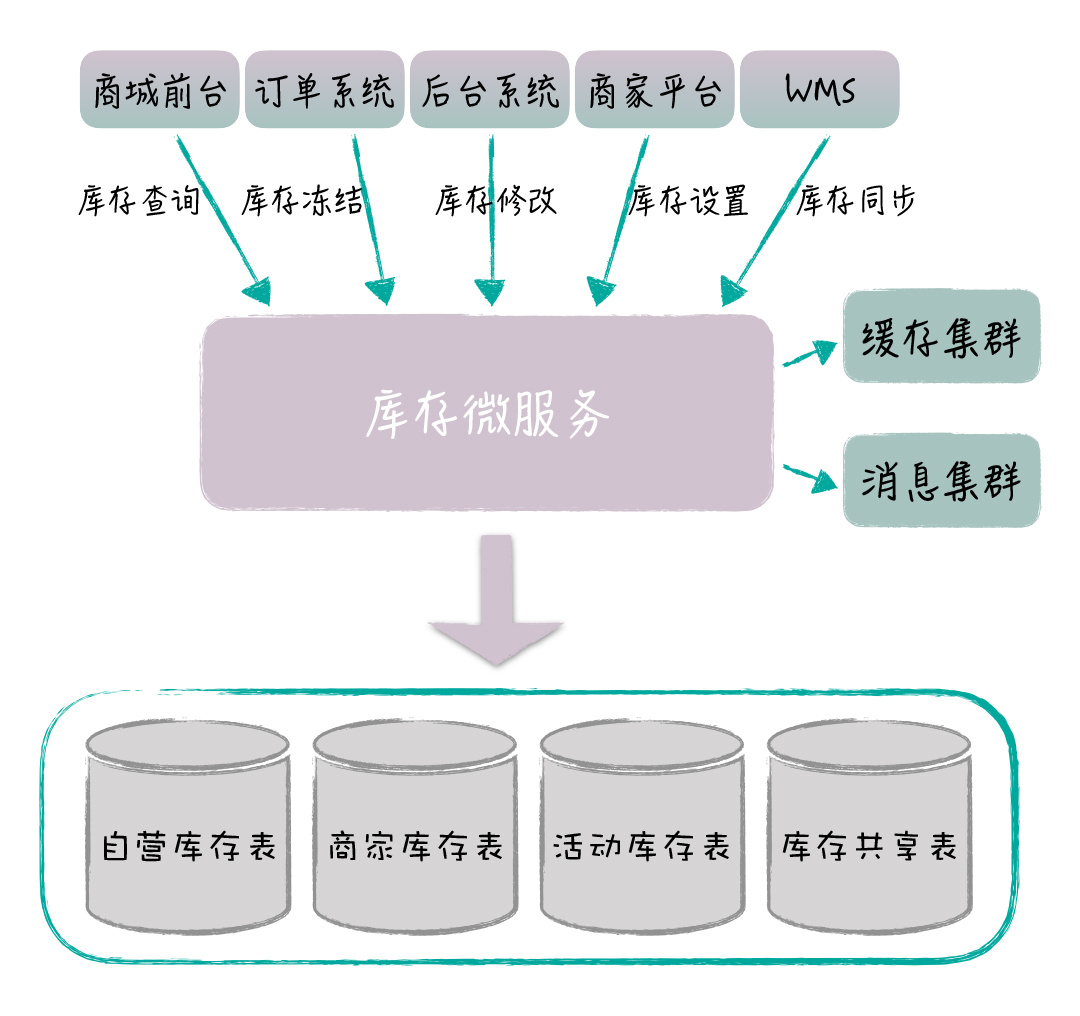
改造后架构图¶
重要
系统改造不会产生直接的业务价值,对于业务开发团队来说,他们往往还需要承担大量新需求的开发工作。所以,从项目推进的角度来看,这种核心服务的改造,很多时候都是技术一把手工程。 在微服务改造过程中,老板要高度重视,大家事先定好时间计划,每周 Review 进度,协调各个团队工作的优先级,确保改造的顺利落地。
重要
基于现有系统进行改造和全新的服务设计是有所不同的,我们不能追求理想化和一步到位,而是要考虑到系统的平滑过渡,先实现微服务的顺利落地,后续再考虑各种优化。
参考¶
【极客】架构实战案例-可复用架构案例(二):如何对现有系统做微服务改造: https://time.geekbang.org/column/article/209597