分库分表¶
备注
读写分离分散了数据库读写操作的压力,但没有分散存储压力,当数据量达到千万甚至上亿条的时候,单台数据库服务器的存储能力会成为系统的瓶颈。
主要体现在这几个方面:
1. 数据量太大,读写的性能会下降,即使有索引,索引也会变得很大,性能同样会下降。
2. 数据文件会变得很大,数据库备份和恢复需要耗费很长时间。
3. 数据文件越大,极端情况下丢失数据的风险越高(例如,机房火灾导致数据库主备机都发生故障)
业务分库¶
备注
业务分库指的是按照业务模块将数据分散到不同的数据库服务器
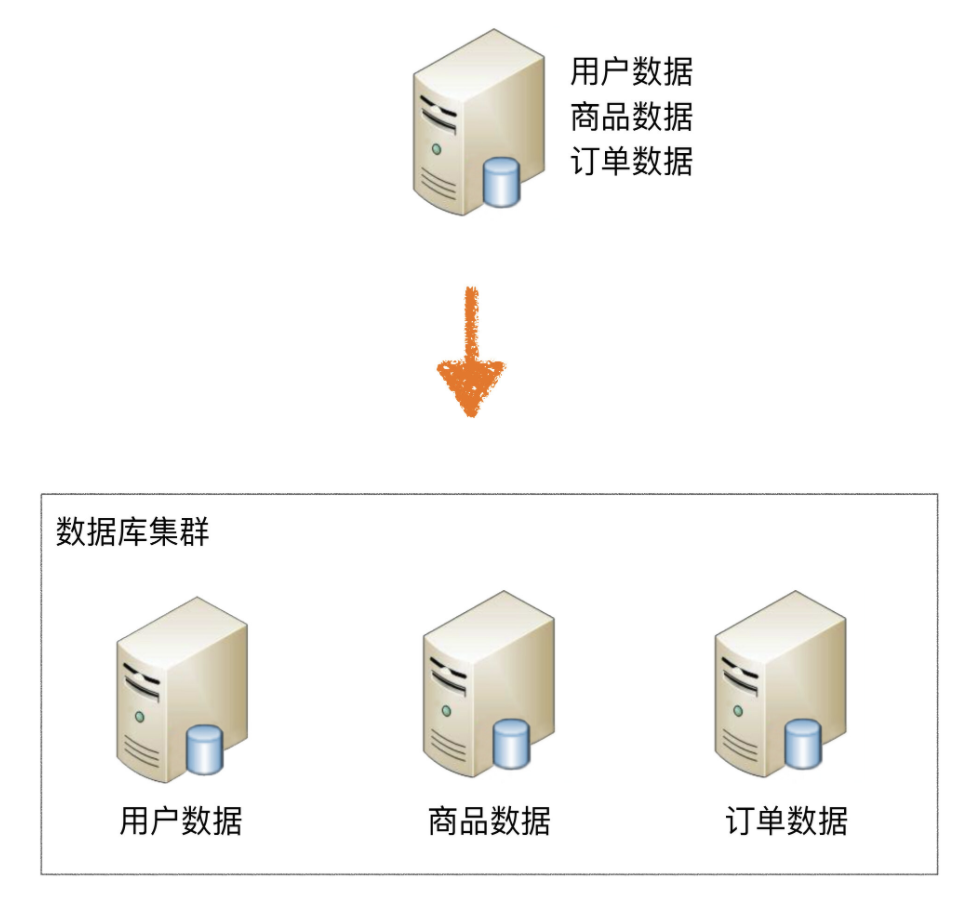
业务分库能够分散存储和访问压力,但同时也带来了新的问题:
1. join 操作问题
2. 事务问题
3. 成本问题
初创业务,并不建议一开始就这样拆分,主要有几个原因:
1. 初创业务存在很大的不确定性,业务不一定能发展起来
业务开始的时候并没有真正的存储和访问压力,业务分库并不能为业务带来价值。
2. 业务分库后,表之间的 join 查询、数据库事务无法简单实现了。
3. 业务分库后,因为不同的数据要读写不同的数据库,代码中需要增加根据数据类型映射到不同数据库的逻辑,增加了工作量。
而业务初创期间最重要的是快速实现、快速验证,业务分库会拖慢业务节奏。
分表¶
备注
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。
备注
单表数据拆分有两种方式:垂直分表 和 水平分表
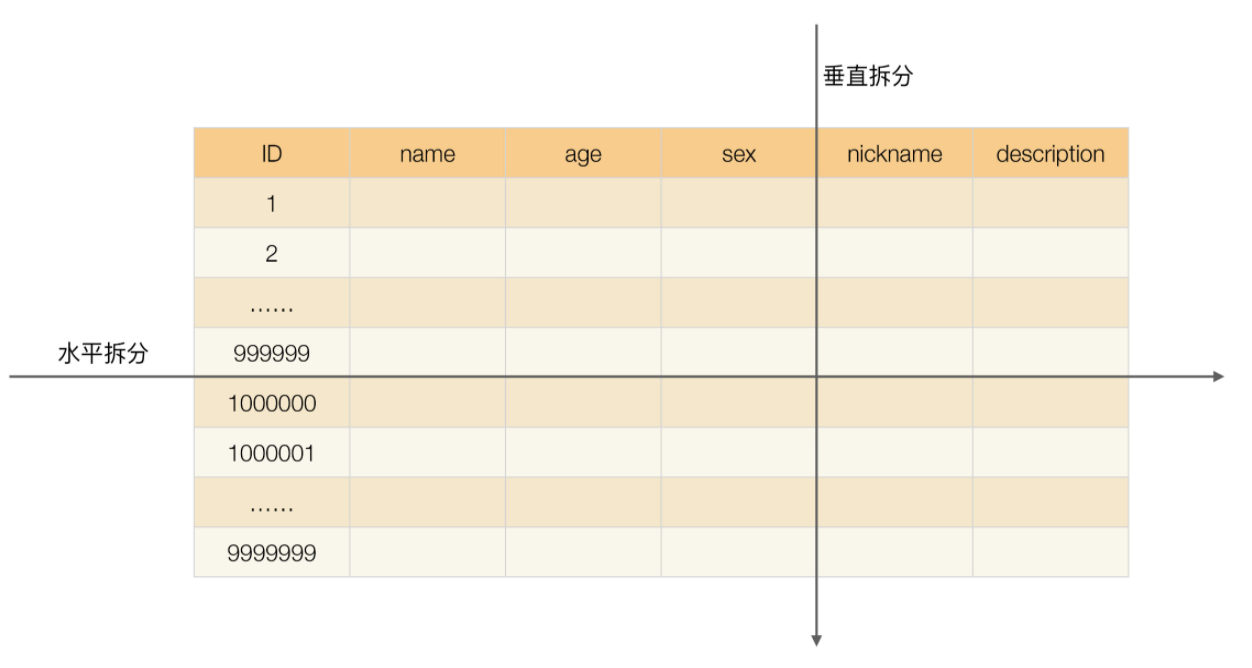
垂直切分:会把表切分为两个表,一个表包含 ID、name、age、sex 列,另外一个表包含 ID、nickname、description 列。 水平切分:一个表包含的是 ID 从 1 到 999999 的行数据,另一个表包含的是 ID 从 1000000 到 9999999 的行数据¶
1. 垂直分表¶
垂直分表引入的复杂性主要体现在表操作的数量要增加。例如:
原来只要一次查询就可以获取 name、age、sex、nickname、description
现在需要两次查询:
一次查询获取 name、age、sex
另外一次查询获取 nickname、description。
2. 水平分表¶
重要
水平分表适合表行数特别大的表
备注
单表行数超过 5000 万就要进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过 1000 万就要分表了;而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患。
水平分表相比垂直分表,会引入更多的复杂性,主要表现在下面几个方面:
1. 路由
水平分表后,某条数据具体属于哪个切分后的子表,需要增加``路由算法``进行计算,这个算法会引入一定的复杂性。
2. join 操作
水平分表后,数据分散在多个表中,如果需要与其他表进行 join 查询,
需要在业务代码或者数据库中间件中进行多次 join 查询,然后将结果合并。
3. count () 操作
水平分表后,虽然物理上数据分散到多个表中,但某些业务逻辑上还是会将这些表当作一个表来处理。
例如,获取记录总数用于分页或者展示,水平分表前用一个 count () 就能完成的操作,在分表后就没那么简单了
4. order by 操作
水平分表后,数据分散到多个子表中,排序操作无法在数据库中完成,
只能由业务代码或者数据库中间件分别查询每个子表中的数据,然后汇总进行排序。
常见的路由算法有:
1. 范围路由:
选取有序的数据列(例如,整形、时间戳等)作为路由的条件,不同分段分散到不同的数据库表中。
以最常见的用户 ID 为例,路由算法可以按照 1000000 的范围大小进行分段:
1 ~ 999999 放到数据库 1 的表中,
1000000 ~ 1999999 放到数据库 2 的表中
以此类推。
范围路由设计的复杂点主要体现在『分段大小的选取』上:
分段太小会导致切分后子表数量过多,增加维护复杂度;
分段太大可能会导致单表依然存在性能问题,
一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
范围路由的优点是:
可以随着数据的增加平滑地扩充新的表。
例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
范围路由的一个比较隐含的缺点是:
分布不均匀,假如按照 1000 万来进行分表,
有可能某个分段实际存储的数据量只有 1000 条,
而另外一个分段实际存储的数据量有 900 万条。
2. Hash 路由
选取某个列(或者某几个列组合也可以)的值进行 Hash 运算,然后根据 Hash 结果分散到不同的数据库表中。
同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,
路由算法可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,
ID 为 985 的用户放到编号为 5 的子表中,
ID 为 10086 的用户放到编号为 6 的字表中。
Hash 路由设计的复杂点主要体现在『初始表数量的选取』上,
表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
而用了 Hash 路由后,增加子表数量是非常麻烦的,所有数据都要重分布。
Hash 路由的优缺点和范围路由基本相反:
Hash 路由的优点是表分布比较均匀,
缺点是扩充新的表很麻烦,所有数据都要重分布。
3. 配置路由
配置路由就是路由表,用一张独立的表来记录路由信息。
同样以用户 ID 为例,我们新增一张 user_router 表,
这个表包含 user_id 和 table_id 两列,根据 user_id 就可以查询对应的 table_id。
配置路由的优点是:
设计简单,使用起来非常灵活,尤其是在扩充表的时候,只需要迁移指定的数据,然后修改路由表就可以了。
配置路由的缺点是:
必须多查询一次,会影响整体性能;
而且路由表本身如果太大(例如,几亿条数据),性能同样可能成为瓶颈,
如果我们再次将路由表分库分表,则又面临一个死循环式的路由算法选择问题。
因为路由表的访问量非常大,每次数据操作都要访问路由表,必须缓存,最好缓存到内存
但建议把数据库的热点表一样会放在内存中,访问很快,因此不是很有必要引入 mc 或者 redis 来提升性能
常见的处理方式有下面两种:
1. count () 相加:
具体做法是在业务代码或者数据库中间件中对每个表进行 count () 操作,然后将结果相加。
这种方式实现简单,缺点就是性能比较低。
例如,水平分表后切分为 20 张表,则要进行 20 次 count (*) 操作,如果串行的话,可能需要几秒钟才能得到结果。
2. 记录数表:
具体做法是新建一张表,假如表名为 “记录数表”,
包含 table_name、row_count 两个字段,
每次插入或者删除子表数据成功后,都更新 “记录数表”。
实现方法¶
备注
和数据库读写分离类似,分库分表具体的实现方式也是 “程序代码封装” 和 “中间件封装”,但实现会更复杂。
读写分离实现时只要识别 SQL 操作是读操作还是写操作,通过简单的判断 SELECT、UPDATE、INSERT、DELETE 几个关键字就可以做到,而分库分表的实现除了要判断操作类型外,还要判断 SQL 中具体需要操作的表、操作函数(例如 count 函数)、order by、group by 操作等,然后再根据不同的操作进行不同的处理。例如 order by 操作,需要先从多个库查询到各个库的数据,然后再重新 order by 才能得到最终的结果。
思考¶
如果使用 hash 进行分表的话,为什么大多方案推荐用 2 的 n 次方作为表的总数,除了收缩容易还有什么好处吗:
这个是 hash 函数实现的一个技巧,当计算 hash 值的时候,普通做法是取余操作,
例如 h% len,但如果 len 是 2 的 N 次方,通过位操作性能更高,计算方式为 h & (len-1)
针对 mysql,发现如果字段有 blob 的字段,select 不写这个字段,和写这个字段,效率差异很大啊,这个是什么原因:
blob 的字段是和行数据分开存储的,而且磁盘上并不是连续的,因此 select blob 字段会让磁盘进入随机 IO 模式
当线上已经进行了分库分表的系统,需要进一步水平扩容时,有什么好的设计方案:
没有太好的方案,要么一开始的分表方案就是按照 id 范围来设计的,要么就需要数据迁移
以电商平台交易系统为例,订单数据量非常大的时候也可以考虑水平分库分表:
针对消费者端订单表按用户 ID 哈希规则分表,这样所有对用户订单的查询条件全都带上用户 ID,达到了数据分片的效果。
但这时商家端需要对订单做管理,可以将订单数据做同步到另一个数据源,
表结构一致只是按照商家 ID 进行哈希规则分表,所有商家端查询走此数据源,条件全部带上商家 ID,也可以做到数据分片的效果。
接下来问题又来了,系统还有一个平台的视角,这时貌似不好沿着这个思路继续了,恳请老师提点提点。
『淘宝的单元化改造』就面临你说的问题,最后他们选择了买家纬度拆分,卖家纬度不拆分
最近看到这样一个思路,用雪花算法生成一个 ID:
创建商家 ID 的时候,生成类似这样的 ID (时间戳 + 公共码 + 机器码 + 计数码) , 然后用户下订单时,肯定能以取到商品信息中的商家 ID, 也生成类似的订单 ID,(时间戳 + 机器码 + 计数码 + 公共码) ,
然后订单按照 公共码 去 hash 分表,这样处理后,当你用商家 ID 查询时,
直接截取出商家 ID 的公共码做 hash,那么所有这个商家 的订单,就可以路由到相应的分库或分表中了
冗余两份数据,做三维度拆分 买家维度,卖家维度 订单 id 纬度或者时间维度。
分表以后的的 count order by 等一些页面查询的东西 我觉得可以走 ES,这些东西不需要实时性,
加表操作和加库操作最好在业务低峰期做,我们都是这样的
你认为什么时候引入分库分表是合适的:
单表数据量超过千万后优化 SQL 语句和代码逻辑不能提高性能后就要引入分表,
单库中表中数据太多达到磁盘 I/O 瓶颈时引入分库
单机分表比较难提升性能
关系型数据库存储是行存储,内存中是分页读写,
单表太大的时候,如果缓存放不下,需要频繁的内存和磁盘换页操作,导致性能急剧下降。
推荐看《MySQL 技术内幕:InnoDB 存储引擎》
如果想快速熟悉,查找一下 mysql 的 innodb buffer pool 相关知识和配置。
对于 count 的情况通常是有各种 where 条件的,计数作用不大,这种有什么更好的方案吗:
定期更新,但要牺牲用户体验
备注
架构师的前景: 对于业务架构来说,简单来说就是 “云”+“人工智能”