读写分离¶
备注
读写分离的基本原理是将数据库读写操作分散到不同的节点上
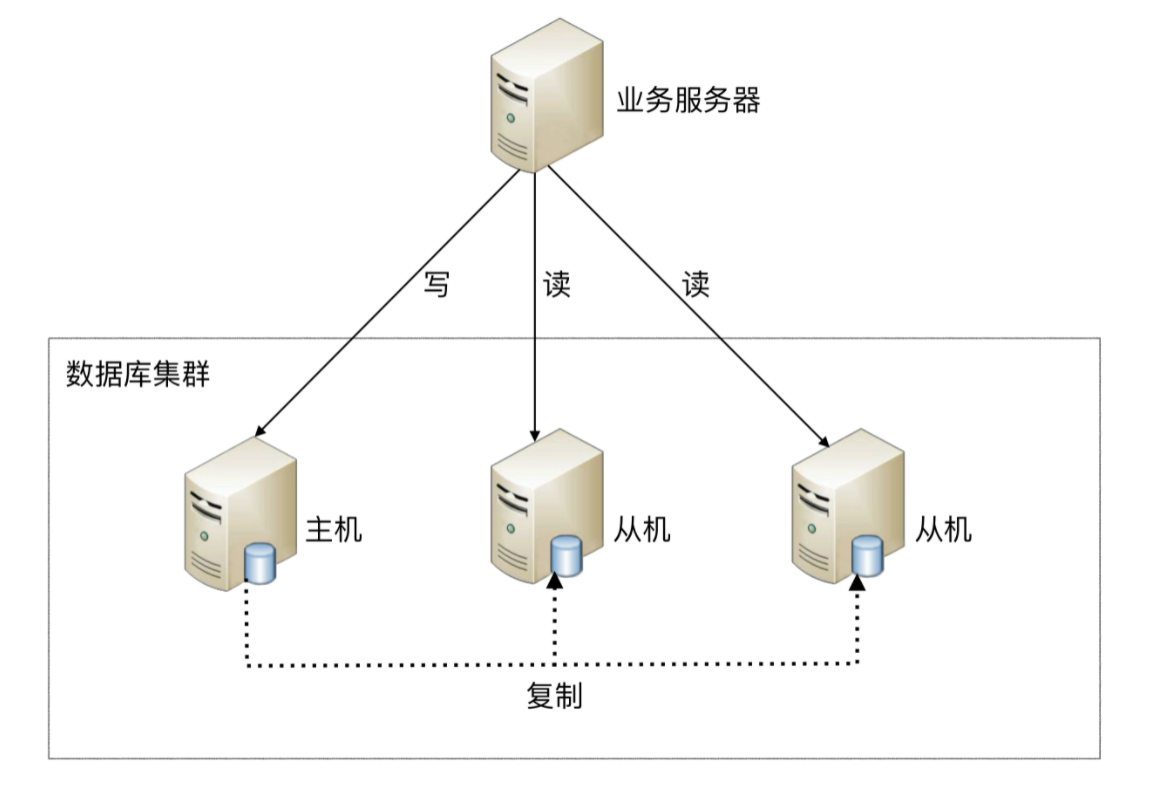
读写分离的基本实现是:
数据库服务器搭建主从集群,一主一从、一主多从都可以
数据库主机负责读写操作,从机只负责读操作
数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据
业务服务器将写操作发给数据库主机,将读操作发给数据库从机
备注
“从机” 是需要提供读数据的功能的;而 “备机” 一般被认为仅仅提供备份功能,不提供访问功能。
重要
读写分离的实现逻辑并不复杂,但有两个细节点将引入设计复杂度:主从复制延迟和分配机制。
复制延迟¶
解决主从复制延迟有几种常见的方法:
1. 写操作后的读操作指定发给数据库主服务器
这种方式和业务强绑定,对业务的侵入和影响较大
如果哪个新来的程序员不知道这样写代码,就会导致一个 bug
2. 读从机失败后再读一次主机
这就是通常所说的 “二次读取”
二次读取和业务无绑定,只需要对底层数据库访问的 API 进行封装即可,实现代价较小
不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。
例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。
3. 关键业务读写操作全部指向主机,非关键业务采用读写分离
对于一个用户管理系统来说,注册 + 登录的业务读写操作全部访问主机
用户的介绍、爱好、等级等业务,可以采用读写分离
因为即使用户改了自己的自我介绍,在查询时却看到了自我介绍还是旧的,业务影响与不能登录相比就小很多,还可以忍受。
分配机制¶
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式:程序代码封装和中间件封装。
程序代码封装¶
程序代码封装 指在代码中抽象一数据访问层(所以有的文章也称这种方式为“中间层封装”),实现读写操作分离和数据库服务器连接的管理。
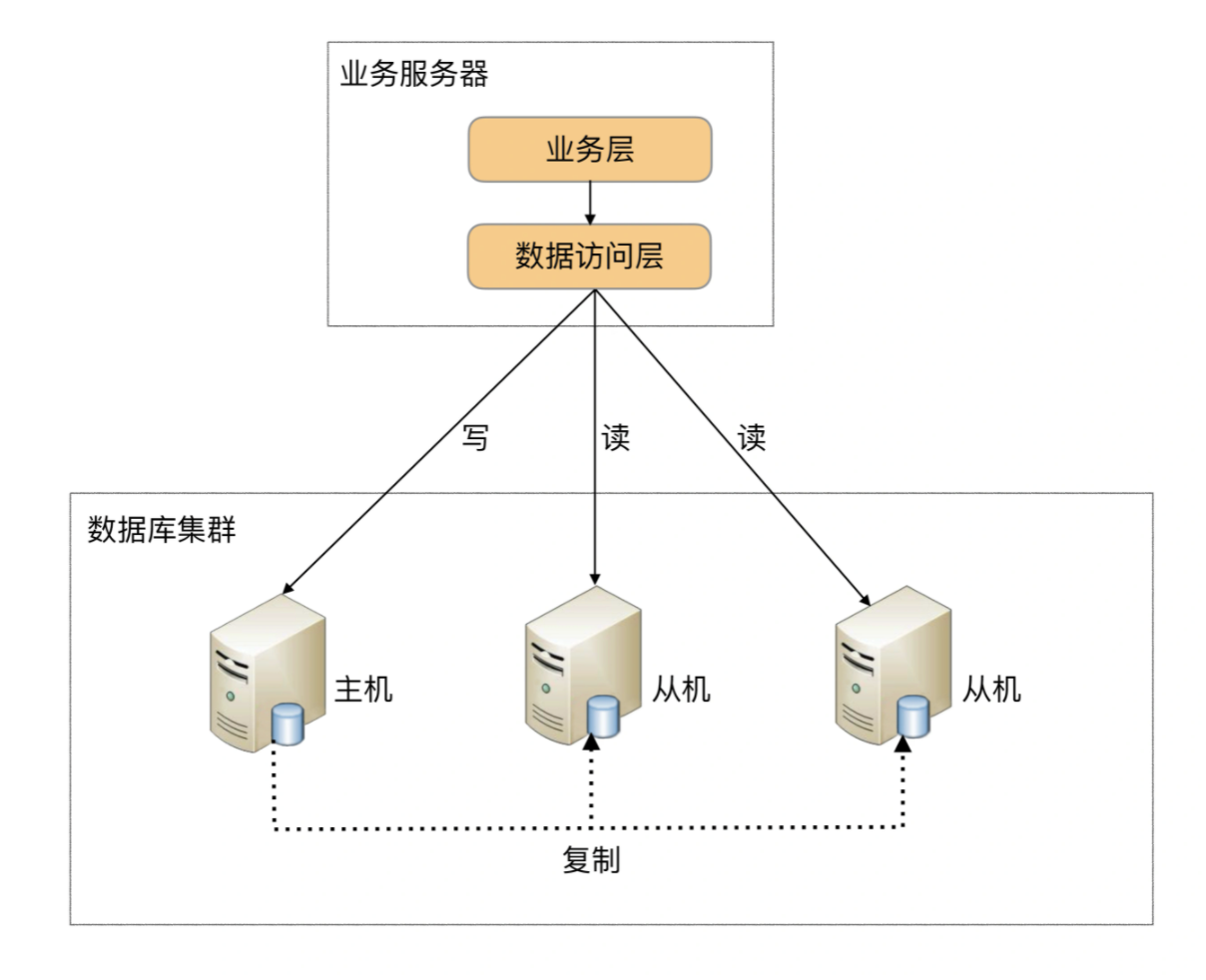
程序代码封装的方式具备几个特点:
1. 实现简单,而且可以根据业务做较多定制化的功能
2. 每个编程语言都需要自己实现一次,无法通用,如果一个业务包含多个编程语言写的多个子系统,则重复开发的工作量比较大
3. 故障情况下,如果主从发生切换,则可能需要所有系统都修改配置并重启。
中间件封装¶
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离。对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。
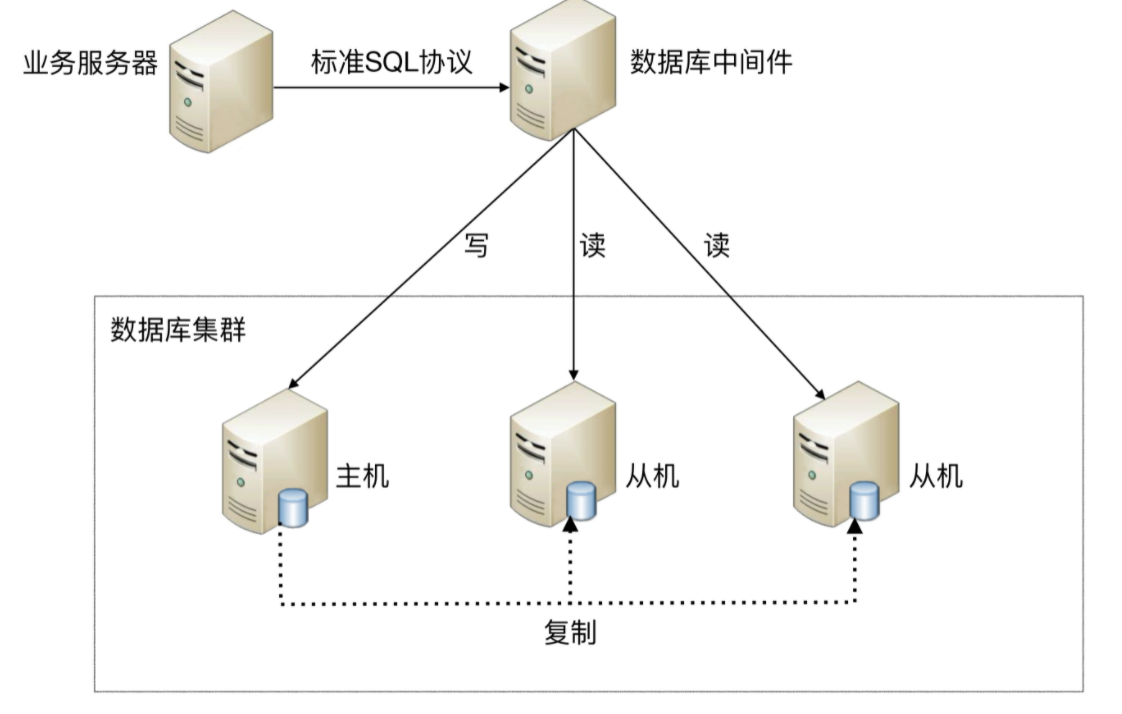
数据库中间件的方式具备的特点是:
1. 能够支持多种编程语言,因为数据库中间件对业务服务器提供的是标准 SQL 接口。
2. 数据库中间件要支持完整的 SQL 语法和数据库服务器的协议(例如,MySQL 客户端和服务器的连接协议)
实现比较复杂,细节特别多,很容易出现 bug,需要较长的时间才能稳定。
3. 数据库中间件自己不执行真正的读写操作,但所有的数据库操作请求都要经过中间件,中间件的性能要求也很高。
数据库主从切换对业务服务器无感知,数据库中间件可以探测数据库服务器的主从状态。
例如,向某个测试表写入一条数据,成功的就是主机,失败的就是从机。
开源数据库中间件:
1. MySQL Proxy
MySQL官方推出,但一直没有正式 GA
2. MySQL Router
MySQL 官方推荐
主要功能有读写分离、故障自动切换、负载均衡、连接池
3. Atlas(奇虎360)
基于 MySQL Proxy 实现
4. MyCaT
5. shardingsphere
备注
Atlas 是一个位于应用程序与 MySQL 之间中间件。在后端 DB 看来,Atlas 相当于连接它的客户端,在前端应用看来,Atlas 相当于一个 DB。Atlas 作为服务端与应用程序通信,它实现了 MySQL 的客户端和服务端协议,同时作为客户端与 MySQL 通信。它对应用程序屏蔽了 DB 的细节,同时为了降低 MySQL 负担,它还维护了连接池。详情参见 这儿
思考¶
数据库读写分离一般应用于什么场景?能支撑多大的业务规模:
读写分离适用单机并发无法支撑并且读的请求更多的情形。
在单机数据库情况下,表上加索引一般对查询有优化作用却影响写入速度
读写分离后可以单独对读库进行优化,写库上减少索引,对读写的能力都有提升,且读的提升更多一些。
不适用的情况:
1. 如果并发写入特别高,单机写入无法支撑,就不适合这种模式
2. 通过缓存技术或者程序优化能够满足要求
查询的条件太多,很动态,类似于京东筛选物品,多品类,多维度筛选,这种情况如何设计缓存:
按照 2-8 原则,选出占访问量 80% 的前 20% 的请求条件缓存,
因为大部分人的查询不会每次都非常多条件,以手机为例,查询苹果加华为的可能占很大一部分
备注
交易型业务缓存应用不多,缓存一般总在查询类业务上。一般的优化顺序是: SQL 优化 —— 缓存 —— 读写分离 —— 分库分表。读写分离一般的设计方式是:默认读走从库,写走主库,特殊情况才由程序员制定,可以代码指定,可以配置指定,这样就不会出现大量 sql 都走主库。
重要
我们要求线上 delete 每次不能超过 1000 条,超过就定时循环操作