评估&选择备选方案¶
如何挑选出最终的方案也是一个很大的挑战,主要原因有:
1. 每个方案都是可行的
如果方案不可行就根本不应该作为备选方案。
2. 没有哪个方案是完美的。
例如,A 方案有性能的缺点,B 方案有成本的缺点,C 方案有新技术不成熟的风险。
3. 评价标准主观性比较强
比如设计师说 A 方案比 B 方案复杂,但另一个设计师可能会认为差不多,因为比较难将 “复杂” 一词进行量化
因此,方案评审的时候我们经常会遇到几个设计师针对某个方案或者某个技术点争论得面红耳赤。
几种指导思想:
1. 最简派
设计师挑选一个看起来最简单的方案。
例如:
我们要做全文搜索功能,方案 1 基于 MySQL,方案 2 基于 Elasticsearch。
MySQL 的查询功能比较简单,
而 Elasticsearch 的倒排索引设计要复杂得多,写入数据到 Elasticsearch
要设计 Elasticsearch 的索引,
要设计 Elasticsearch 的分布式……
全套下来复杂度很高,所以干脆就挑选 MySQL 来做吧。
2. 最牛派
最牛派的做法和最简派正好相反,设计师会倾向于挑选技术上看起来最牛的方案。
例如,性能最高的、可用性最好的、功能最强大的,或者淘宝用的、微信开源的、Google 出品的等。
我们以缓存方案中的 Memcache 和 Redis 为例:
假如我们要挑选一个搭配 MySQL 使用的缓存,
Memcache 是纯内存缓存,支持基于一致性 hash 的集群;
而 Redis 同时支持持久化、支持数据字典、支持主备、支持集群,
看起来比 Memcache 好很多啊,所以就选 Redis 好了。
3. 最熟派
设计师基于自己的过往经验,挑选自己最熟悉的方案。
我以编程语言为例,假如设计师曾经是一个 C++ 经验丰富的开发人员,现在要设计一个运维管理系统,
由于对 Python 或者 Ruby on Rails 不熟悉,因此继续选择 C++ 来做运维管理系统。
4. 领导派
领导派就更加聪明了,列出备选方案,设计师自己拿捏不定,然后就让领导来定夺,
反正最后方案选的对那是领导厉害,方案选的不对怎么办?那也是领导 “背锅”。
备注
这些不同的做法本身并不存在绝对的正确或者绝对的错误,关键是不同的场景应该采取不同的方式。
360 度环评¶
备注
列出我们需要关注的质量属性点,然后分别从这些质量属性的维度去评估每个方案,再综合挑选适合当时情况的最优方案。
常见的方案质量属性点有:
性能、
可用性、
硬件成本、
项目投入、
复杂度、
安全性、
可扩展性等
备注
在评估这些质量属性时,需要遵循架构设计原则 1 “合适原则” 和原则 2 “简单原则”,避免贪大求全,基本上某个质量属性能够满足一定时期内业务发展就可以了。考虑「业务发展」问题的时候,需要遵循架构设计原则 3 “演化原则”,避免过度设计、一步到位的想法。
备注
360 度环评表也只能帮助我们分析各个备选方案,还是没有告诉我们具体选哪个方案,原因就在于没有哪个方案是完美的,极少出现某个方案在所有对比维度上都是最优的。
引入开源方案工作量小,但是可运维性和可扩展性差;
自研工作量大,但是可运维和可维护性好;
使用 C 语言开发性能高,但是目前团队 C 语言技术积累少;
使用 Java 技术积累多,但是性能没有 C 语言开发高,成本会高一些
重要
正确的做法是按优先级选择,即架构师综合当前的业务发展情况、团队人员规模和技能、业务发展预测等因素,将质量属性按照优先级排序,首先挑选满足第一优先级的,如果方案都满足,那就再看第二优先级…… 以此类推。
实战¶
备选方案评审会议,参加的人有研发、测试、运维、还有几个核心业务的主管。(注:这个模拟的场景是在 2013 年)
备选方案 1:采用开源 Kafka 方案:
业务主管倾向于采用 Kafka 方案,因为 Kafka 已经比较成熟,各个业务团队或多或少都了解过 Kafka。 中间件团队部分研发人员也支持使用 Kafka,因为使用 Kafka 能节省大量的开发投入; 但部分人员认为 Kafka 可能并不适合我们的业务场景,因为: Kafka 的设计目的是为了支撑大容量的日志消息传输,而我们的消息队列是为了业务数据的可靠传输。 运维代表提出了强烈的反对意见: 首先,Kafka 是 Scala 语言编写的,运维团队没有维护 Scala 语言开发的系统的经验,出问题后很难快速处理; 其次,目前运维团队已经有一套成熟的运维体系,包括部署、监控、应急等,使用 Kafka 无法融入这套体系,需要单独投入运维人力。 测试代表也倾向于引入 Kafka,因为 Kafka 比较成熟,无须太多测试投入。备选方案 2:集群 + MySQL 存储:
中间件团队的研发人员认为这个方案比较简单, 但部分研发人员对于这个方案的性能持怀疑态度,毕竟使用 MySQL 来存储消息数据,性能肯定不如使用文件系统; 并且有的研发人员担心做这样的方案是否会影响中间件团队的技术声誉,毕竟用 MySQL 来做消息队列,看起来比较 “土”、比较另类。 运维代表赞同这个方案,因为这个方案可以融入到现有的运维体系中, 而且使用 MySQL 存储数据,可靠性有保证,运维团队也有丰富的 MySQL 运维经验; 但运维团队认为这个方案的成本比较高,一个数据分组就需要 4 台机器(2 台服务器 + 2 台数据库)。 测试代表认为这个方案测试人力投入较大,包括功能测试、性能测试、可靠性测试等都需要大量地投入人力。 业务主管对这个方案既不肯定也不否定,因为反正都不是业务团队来投入人力来开发, 系统维护也是中间件团队负责,对业务团队来说,只要保证消息队列系统稳定和可靠即可。备选方案 3:集群 + 自研存储系统:
中间件团队部分研发人员认为这是一个很好的方案,既能够展现中间件团队的技术实力,性能上相比 MySQL 也要高; 但另外的研发人员认为这个方案复杂度太高,按照目前的团队人力和技术实力,要做到稳定可靠的存储系统,需要耗时较长的迭代, 这个过程中消息队列系统可能因为存储出现严重问题,例如文件损坏导致丢失大量数据。 运维代表不太赞成这个方案,因为运维之前遇到过几次类似的存储系统故障导致数据丢失的问题,损失惨重。 例如,MongoDB 丢数据、Tokyo Tyrant 丢数据无法恢复等。 运维团队并不相信目前的中间件团队的技术实力足以支撑自己研发一个存储系统(这让中间件团队的人员感觉有点不爽)。 测试代表赞同运维代表的意见,并且自研存储系统的测试难度也很高,投入也很大。 业务主管对自研存储系统也持保留意见,因为从历史经验来看,新系统上线肯定有 bug, 而存储系统出 bug 是最严重的,一旦出 bug 导致大量消息丢失,对系统的影响会严重。
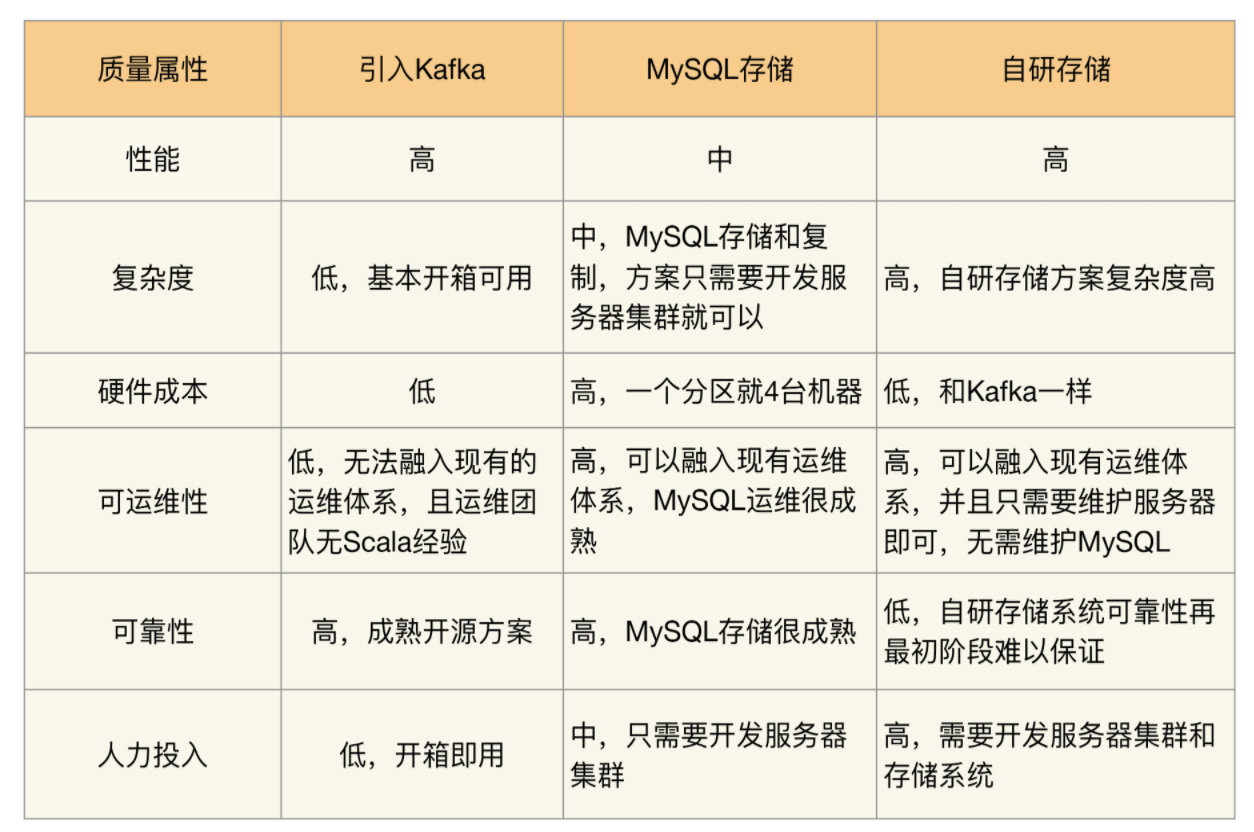
3 个方案的 360 度环评表¶
架构师经过思考后,给出了最终选择备选方案 2,原因有:
排除备选方案 1 的主要原因是可运维性,因为再成熟的系统,上线后都可能出问题,
如果出问题无法快速解决,则无法满足业务的需求;
并且 Kafka 的主要设计目标是高性能日志传输,而我们的消息队列设计的主要目标是业务消息的可靠传输。
排除备选方案 3 的主要原因是复杂度,
目前团队技术实力和人员规模(总共 6 人,还有其他中间件系统需要开发和维护)
无法支撑自研存储系统(参考架构设计原则 2:简单原则)。
备选方案 2 的优点就是复杂度不高,也可以很好地融入现有运维体系,可靠性也有保障。
针对备选方案 2 的缺点,架构师解释是:
备选方案 2 的第一个缺点是性能,
业务目前需要的性能并不是非常高,方案 2 能够满足,即使后面性能需求增加,
方案 2 的数据分组方案也能够平行扩展进行支撑(参考架构设计原则 3:演化原则)。
备选方案 2 的第二个缺点是成本,
一个分组就需要 4 台机器,支撑目前的业务需求可能需要 12 台服务器,
但实际上备机(包括服务器和数据库)主要用作备份,可以和其他系统并行部署在同一台机器上。
备选方案 2 的第三个缺点是技术上看起来并不很优越,
但我们的设计目的不是为了证明自己(参考架构设计原则 1:合适原则),而是更快更好地满足业务需求。