设计备选方案¶
备注
架构师的工作并不神秘,成熟的架构师需要对已经存在的技术非常熟悉,对已经经过验证的架构模式烂熟于心,然后根据自己对业务的理解,挑选合适的架构模式进行组合,再对组合后的方案进行修改和调整。
虽然软件技术经过几十年的发展,新技术层出不穷,但是经过时间考验,已经被各种场景验证过的成熟技术其实更多。例如:
1. 高可用的主备方案、集群方案,
2. 高性能的负载均衡、多路复用,
3. 可扩展的分层、插件化等技术,
绝大部分时候我们有了明确的目标后,按图索骥就能够找到可选的解决方案。
只有当这种方式完全无法满足需求的时候,才会考虑进行方案的创新,而事实上方案的创新绝大部分情况下也都是基于已有的成熟技术:
1. NoSQL:Key-Value 的存储和数据库的索引其实是类似的,Memcache 只是把数据库的索引独立出来做成了一个缓存系统。
2. Hadoop 大文件存储方案,基础其实是集群方案 + 数据复制方案。
3. Docker 虚拟化,基础是 LXC(Linux Containers)。
4. LevelDB 的文件存储结构是 Skip List。
1. 常见的错误-设计最优秀的方案¶
根据架构设计原则中 “合适原则” 和 “简单原则 “的要求,挑选合适自己业务、团队、技术能力的方案才是好方案
2. 常见的错误-只做一个方案¶
备注
单一方案设计会出现过度辩护的情况,即架构评审时,针对方案存在的问题和疑问,架构师会竭尽全力去为自己的设计进行辩护,经验不足的设计人员可能会强词夺理。
备选方案的数量以 3 ~ 5 个为最佳:
少于 3 个方案可能是因为思维狭隘,考虑不周全;
多于 5 个则需要耗费大量的精力和时间,并且方案之间的差别可能不明显
“三方案”,又叫 “第三选择”,可以防止思维狭隘,目光短浅,思维盲区等决策陷阱
备选方案的差异要比较明显:
例如:
主备方案和集群方案差异就很明显,
或者同样是主备方案,用 ZooKeeper 做主备决策和用 Keepalived 做主备决策的差异也很明显。
但是:
都用 ZooKeeper 做主备决策,一个检测周期是 1 分钟,一个检测周期是 5 分钟,
这就不是架构上的差异,而是细节上的差异了,不适合做成两个方案。
备选方案的技术不要只局限于已经熟悉的技术:
设计架构时,架构师需要将视野放宽,考虑更多可能性。
很多架构师或者设计师积累了一些成功的经验,出于快速完成任务和降低风险的目的,
可能自觉或者不自觉地倾向于使用自己已经熟悉的技术,对于新的技术有一种不放心的感觉。
就像那句俗语说的:“如果你手里有一把锤子,所有的问题在你看来都是钉子”。
例如,架构师对 MySQL 很熟悉,因此不管什么存储都基于 MySQL 去设计方案,
系统性能不够了,首先考虑的就是 MySQL 分库分表,
而事实上也许引入一个 Memcache 缓存就能够解决问题。
3. 常见的错误:备选方案过于详细¶
备注
备选方案过于详细耗费了大量的时间和精力。将注意力集中到细节中,忽略了整体的技术设计,导致备选方案数量不够或者差异不大。
评审的时候其他人会被很多细节给绕进去,评审效果很差:
例如,评审的时候针对某个定时器应该是 1 分钟还是 30 秒,争论得不可开交。
正确的做法是备选阶段关注的是技术选型,而不是技术细节:
技术选型的差异要比较明显。例如:
采用 ZooKeeper 和 Keepalived 两种不同的技术来实现主备,差异就很大;
而同样都采用 ZooKeeper:
一个方案的节点设计是 /service/node/master,
另一个方案的节点设计是 /company/service/master
这两个方案并无明显差异,无须在备选方案设计阶段作为两个不同的备选方案,
至于节点路径究竟如何设计,只要在最终的方案中挑选一个进行细化即可。
实战¶
“前浪微博” 的场景,上节我们通过 “排查法” 识别了消息队列的复杂性主要体现在:
高性能消息读取、 高可用消息写入、 高可用消息存储、 高可用消息读取、 接下来进行第 2 步,设计备选方案。
备选方案 1:采用开源的 Kafka:
Kafka 是成熟的开源消息队列方案,功能强大,性能非常高,而且已经比较成熟 kafka 号称百万级读写,性能和可用性都不是问题
备选方案 2:集群 + MySQL 存储:
高性能读取: a. 首先考虑单服务器高性能。高性能消息读取属于 “计算高可用” 的范畴 b. 由于系统设计的 QPS 是 13800: 单台服务器支撑这么高的 QPS 还是有很大风险的 因此选择采取集群方式来满足高性能消息读取, 集群的负载均衡算法采用简单的轮询 高性能写入: 采取集群的方式来满足。因为消息只要写入集群中一台服务器就算成功写入 集群的负载均衡算法也采用简单的轮询 某台服务器异常的情况下,客户端直接将消息写入下一台正常的服务器即可。 整个系统中最复杂的是 “高可用存储” 和 “高可用读取” 高可用存储: 要求已经写入的消息在单台服务器宕机的情况下不丢失; 高可用读取: 要求已经写入的消息在单台服务器宕机的情况下可以继续读取 可以: 利用 MySQL 的主备复制功能来达到 “高可用存储 “的目的, 通过服务器的主备方案来达到 “高可用读取” 的目的。
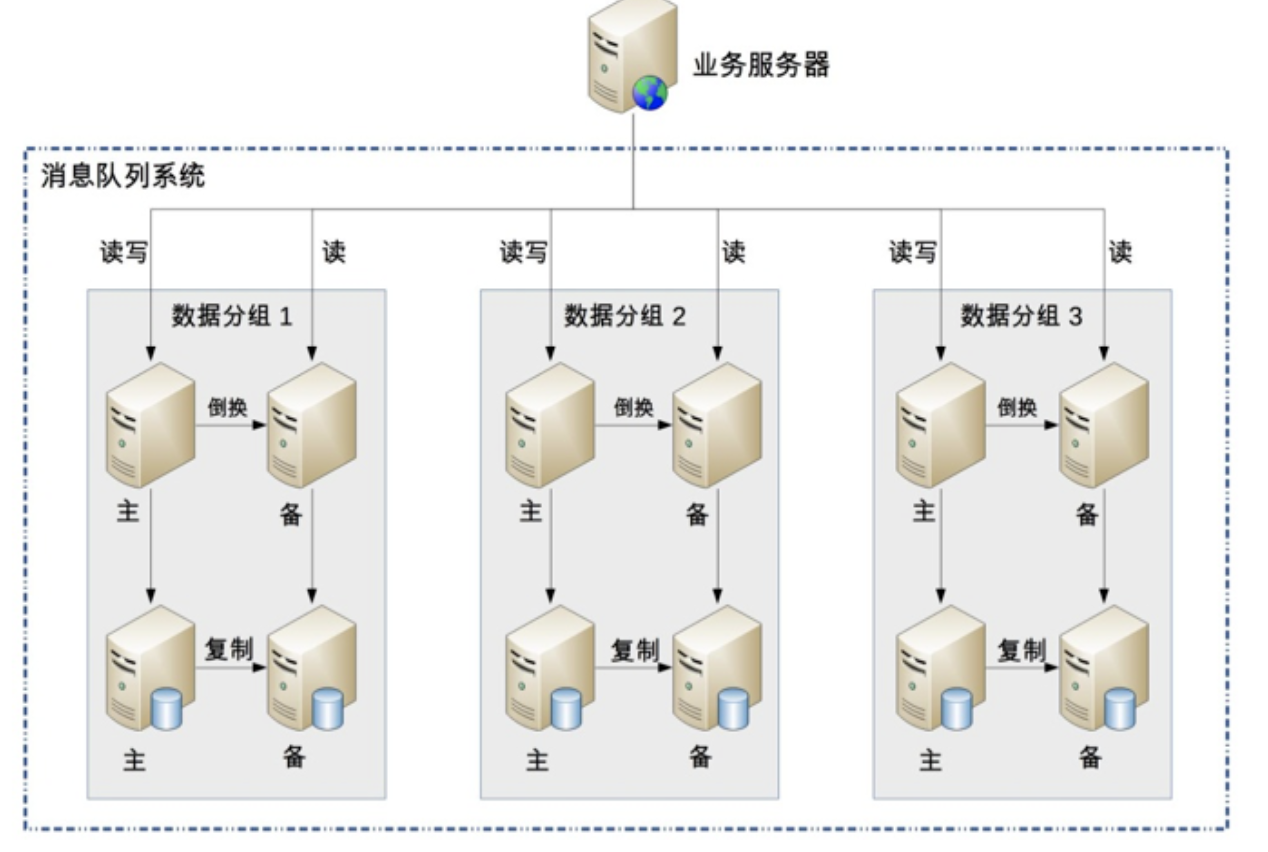
备选方案 3:集群 + 自研存储方案:
在备选方案 2 的基础上,将 MySQL 存储替换为自研实现存储方案, 因为 MySQL 的关系型数据库的特点并不是很契合消息队列的数据特点, 参考 Kafka 的做法,可以自己实现一套文件存储和复制方案
备注
架构师的技术储备越丰富、经验越多,备选方案也会更多,从而才能更好地设计备选方案。例如,开源方案选择可能就包括 Kafka、ActiveMQ、RabbitMQ;集群方案的存储既可以考虑用 MySQL,也可以考虑用 HBase,还可以考虑用 Redis 与 MySQL 结合等;自研文件系统也可以有多个,可以参考 Kafka,也可以参考 LevelDB,还可以参考 HBase 等