9.1. 常用¶
9.1.1. 各向量DB对比¶
托管方式:
self-hosted/on-premise
redis,pgvector,milvus
managed/cloud-native
zilliz,pinecone
embeded+cloud-native
chroma,lanceDB
self-hosted+cloud-native
vald,drant,weaviate,vspa,elasticsearch

编程语言的选择¶
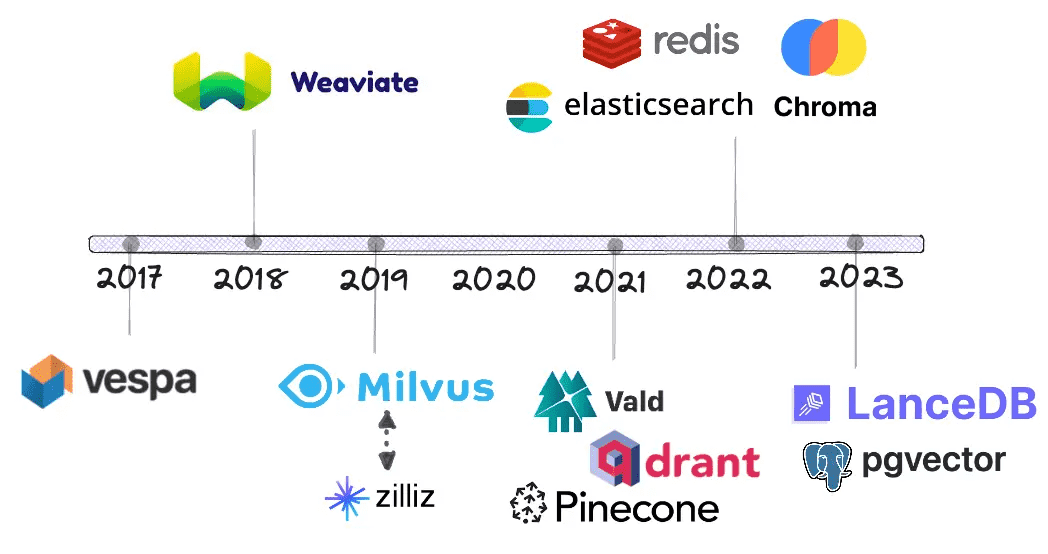
时间线¶
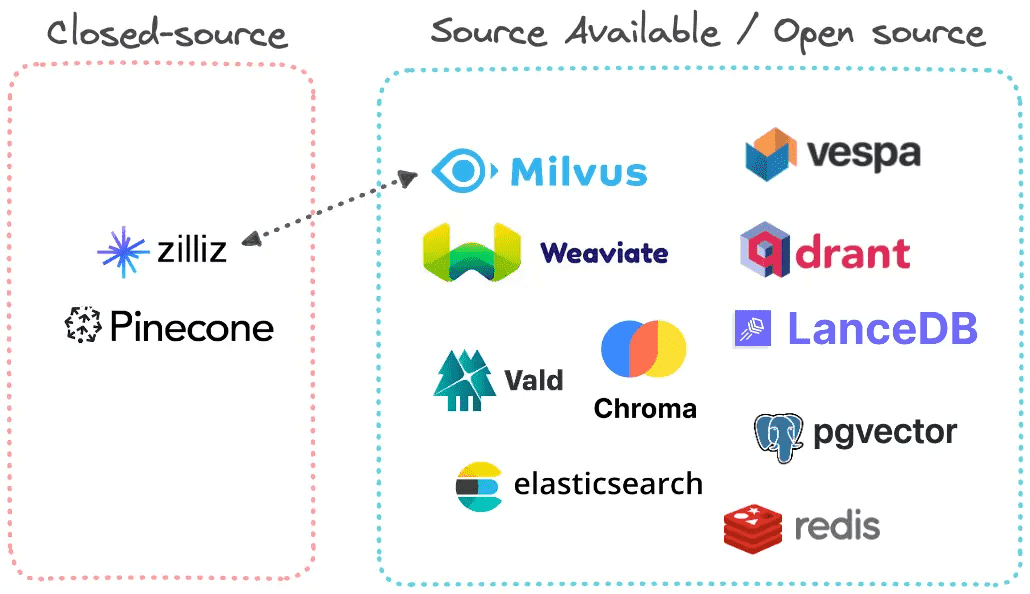
开/闭源¶
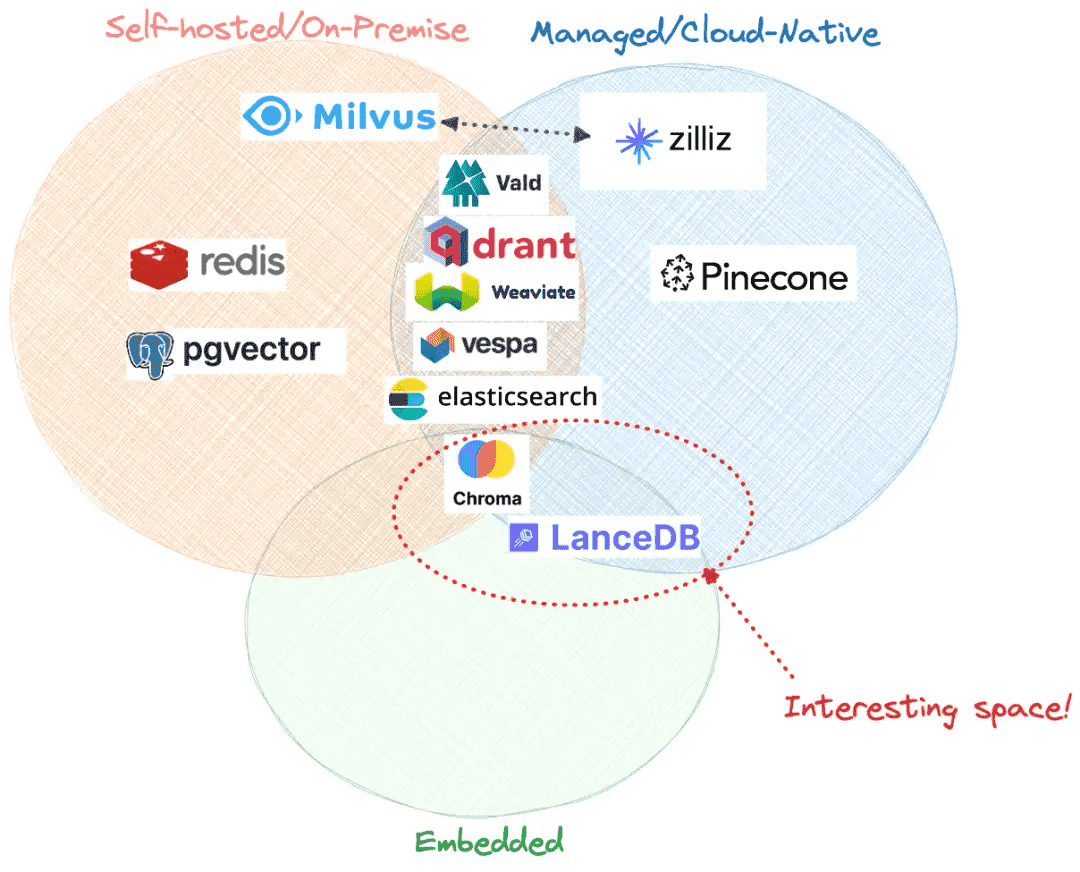
托管方法¶
9.1.2. 索引方法¶
13 种高维向量检索算法全解析: https://zhuanlan.zhihu.com/p/415320221
算法:
Flat
Tree-based:KD-Tree, Trinary Projection Trees, Annoy
IVF-based:IVF,IVMF
Hashing-based:LSH,Spherical Hashing,Spectral Hashing
Graph-based:NSW,NSG,HNSW,DiskANN
HNSW
分层的可导航小世界(Hierarchical Navigable Small World,HNSW)是一种基于图的数据结构,它将节点划分成不同层级,贪婪地遍历来自上层的元素,直到达到局部最小值,然后切换到下一层,以上一层中的局部最小值作为新元素重新开始遍历,直到遍历完最低一层。它的基本思想是:跳表+NSW
跳表
NSW
核心思想:可导航小世界(Navigable Small World,NSW)将候选集合 构建成可导航小世界图,利用基于贪婪搜索的kNN算法从图中查找与查询点距离最近的k个顶点。
近似Delonay图:向图中逐个插入点,对于每个新插入点,使用近似kNN搜索(approximate kNN search)算法从图中找到与其最近f个点集合,该集合中所有点与插入点连接。通过上述方式构建的是近似Delonay图,与标准Delonay图相比,随着越来越多的点被插入到图中,初期构建的短距离边会慢慢变成长距离边,形成可导航的小世界,从而在查找时减少跳数加快查找速度。
德劳内(Delaunay)三角剖分算法,这个算法可以达成如下要求:1,图中每个点都有“友点”。2,相近的点都互为“友点”。3,图中所有连接(线段)的数量最少。Delaunay图有个缺点,它没有高速公路机制,也就是说所有的图节点都只会跟自己相近的点建立连接,如果需要抵达一个距离较远的点,则时间复杂度较高。而不管是构建图索引的时候,还是在线检索的时候,都需要进行临近搜索,直接采用Delaunay图就会导致离线索引构建以及在线serving的时间复杂度不理想。
SW:在网络中,任选两个节点,连通这两个节点的最少边数,定义为这两个节点的路径长度,网络中所有节点对的路径长度的平均值,定义为网络的特征路径长度,小世界网络的定义即特征路径长度与节点数的对数呈正相关。
Vamana(DiskANN)
量化:
PQ(Product Quantization)
PQ 将特征空间分解为多个低维子空间的笛卡尔乘积,然后单独地对每一个子空间进行量化
SQ(Scalar Quantization)
SQ是将每一个维度量化成指定位数的一个数
检索:
向量检索: 基于faiss, milvus,weaviate,chroma等向量数据库
关键字检索:基于文本检索引擎ElasticSearch,OpenSearch和BM25算法
图数据库检索:ne4j,nebula等图数据库
关系数据库检索:pgsql,oracle等关系数据库
搜索引擎:bing, duckduckgo, metaphor
9.1.3. 其他¶
Annoy: Annoy 是一个小巧而快速的库,专门用于近似最近邻搜索。虽然它不是一个数据库,但你可以将其用于构建自定义向量索引。