重要参数说明¶
innodb_flush_log_at_trx_commit(待测试)¶
# 全局动态参数,其取值范围为0,1,2,缺省值为1
# 默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘
# 设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新
# 设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统 挂了时才可能丢数据
link: http://dev.mysql.com/doc/refman/5.5/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
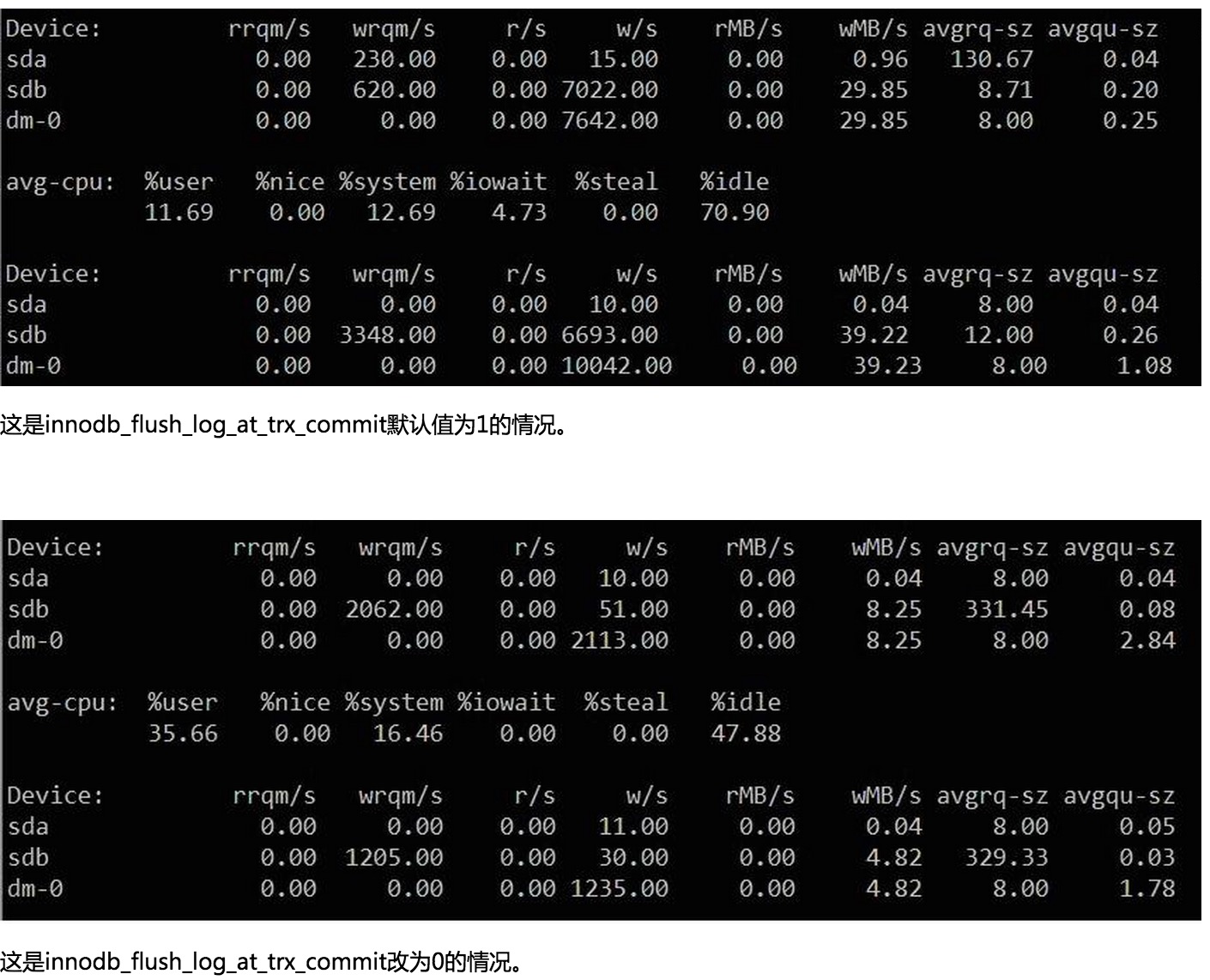
innodb_flush_log_at_trx_commit,IO负载马上下降,调整innodb_flush_log_at_trx_commit对于大量写事务的情况磁盘IO会有很明显的改善,但也有丢数据的风险,慎用
max_binlog_cache_size¶
binlog 能够使用的最大cache 内存大小
当我们执行多语句事务的时候 所有session的使用的内存超过max_binlog_cache_size的值时
就会报错:“Multi-statement transaction required more than 'max_binlog_cache_size' bytes ofstorage”
设置太大的话,会比较消耗内存资源;
设置太小又会使用到临时文件即disk
innodb_log_file_size¶
redo日志被用于确保写操作快速而可靠并且在崩溃时恢复
一方面你想让它更大来提高性能,另一方面你想让它更小来使得崩溃后更快恢复
一开始就把innodb_log_file_size设置成512M(这样有1GB的redo日志)会使你有充裕的写操作空间
如果你知道你的应用程序需要频繁的写入数据并且你使用的时MySQL 5.6,你可以一开始就把它这是成4G
innodb_buffer_pool_size¶
# You can set .._buffer_pool_size up to 50 - 80 %
# of RAM but beware of setting memory usage too high
这是你安装完InnoDB后第一个应该设置的选项
缓冲池是数据和索引缓存的地方:这个值越大越好,这能保证你在大多数的读取操作时使用的是内存而不是硬盘
典型的值是5-6GB(8GB内存),20-25GB(32GB内存),100-120GB(128GB内存)
thread_cache_size¶
连接线程缓存:
连接线程是 MySQL 为了提高创建连接线程的效率,将部分空闲的连接线程保持在一个缓存区以备新进连接请求的时候使用,这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。当我们通过 thread_cache_size 设置了连接线程缓存池可以缓存的连接线程的大小之后,可以通过(Connections – Threads_created) / Connections * 100% 计算出连接线程缓存的命中率。注意,这里设置的是可以缓存的连接线程的数目,而不是内存空间的大小
query_cache_size¶
查询缓存:
最佳选项是将其从一开始就停用,设置query_cache_size = 0(现在MySQL 5.6的默认值)
并利用其他方法加速查询:优化索引、增加拷贝分散负载或者启用额外的缓存(比如memcache或redis)
A value of 0 or OFF prevents caching or retrieval of cached results.
A value of 1 or ON enables caching except of those statements that begin with SELECT SQL_NO_CACHE.
A value of 2 or DEMAND causes caching of only those statements that begin with SELECT SQL_CACHE.
工作原理:
一个SELECT查询在DB中工作后,DB会把该语句缓存下来,当同样的一个SQL再次来到DB里调用时,DB在该表没发生变化的情况下把结果从缓存中返回给Client
这里有一个关建点,就是DB在利用Query_cache工作时,要求该语句涉及的表在这段时间内没有发生变更。那如果该表在发生变更时,Query_cache里的数据又怎么处理呢?首先要把Query_cache和该表相关的语句全部置为失效,然后在写入更新。那么如果Query_cache非常大,该表的查询结构又比较多,查询语句失效也慢,一个更新或是Insert就会很慢,这样看到的就是Update或是Insert怎么这么慢了
所以在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。而且在高并发,写入量大的系统,建系把该功能禁掉
innodb_flush_log_trx_commit¶
InnoDB 日志缓冲区(InnoDB Log Buffer):
这是 InnoDB 存储引擎的事务日志所使用的缓冲区。类似于 Binlog Buffer,InnoDB 在写事务日志的时候,为了提高性能,也是先将信息写入 Innofb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。可以通过 innodb_log_buffer_size 参数设置其可以使用的最大内存空间
注:innodb_flush_log_trx_commit 参数对 InnoDB Log 的写入性能有非常关键的影响。该参数可以设置为0,1,2,解释如下
0:log buffer中的数据将以每秒一次的频率写入到log file中,且同时会进行文件系统到磁盘的同步操作,但是每个事务的commit并不会触发任何log buffer 到log file的刷新或者文件系统到磁盘的刷新操作;
1:在每次事务提交的时候将log buffer 中的数据都会写入到log file,同时也会触发文件系统到磁盘的同步;
2:事务提交会触发log buffer 到log file的刷新,但并不会触发磁盘文件系统到磁盘的同步。此外,每秒会有一次文件系统到磁盘同步操作
innodb_force_recovery¶
1(SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
2(SRV_FORCE_NO_BACKGROUND):阻止主线程的运行,如主线程需要执行full purge操作,会导致crash。
3(SRV_FORCE_NO_TRX_UNDO):不执行事务回滚操作。
4(SRV_FORCE_NO_IBUF_MERGE):不执行插入缓冲的合并操作。
5(SRV_FORCE_NO_UNDO_LOG_SCAN):不查看重做日志,InnoDB存储引擎会将未提交的事务视为已提交。
6(SRV_FORCE_NO_LOG_REDO):不执行前滚的操作。
说明:
1 (SRV_FORCE_IGNORE_CORRUPT)
Lets the server run even if it detects a corrupt page. Tries to make SELECT * FROM tbl_name jump over corrupt index records and pages, which helps in dumping tables.
2 (SRV_FORCE_NO_BACKGROUND)
Prevents the master thread and any purge threads from running. If a crash would occur during the purge operation, this recovery value prevents it.
3 (SRV_FORCE_NO_TRX_UNDO)
Does not run transaction rollbacks after crash recovery.
4 (SRV_FORCE_NO_IBUF_MERGE)
Prevents insert buffer merge operations. If they would cause a crash, does not do them. Does not calculate table statistics. This value can permanently corrupt data files. After using this value, be prepared to drop and recreate all secondary indexes.
5 (SRV_FORCE_NO_UNDO_LOG_SCAN)
Does not look at undo logs when starting the database: InnoDB treats even incomplete transactions as committed. This value can permanently corrupt data files.
6 (SRV_FORCE_NO_LOG_REDO)
Does not do the redo log roll-forward in connection with recovery. This value can permanently corrupt data files. Leaves database pages in an obsolete state, which in turn may introduce more corruption into B-trees and other database structures.
innodb_file_per_table¶
innodb独立表空间:
如果由“共享表空间”转化而来,需要做如下操作
方法1:
1. 备份全部数据库,执行命令::
mysqldump -q -uusername -pyourpassword --add-drop-table -all-databases > /all.sq
2. 修改my.ini文件,增加下面配置::
innodb_file_per_table = 1
3. 暂停数据库
4. 删除原来的ibdata1文件及日志文件ib_logfile*,删除data目录下的应用数据库文件夹(mysql文件夹不要删)
5. 启动数据库
6. 还原数据库::
mysql -uusername -pyourpassword < /all.sql
方法2:
修改配置文件my.cnf中的参数innodb_file_per_table参数为1
重启服务后将需要修改的所有innodb表都执行一遍:
alter table table_name engine=innodb;
注:方式修改后,原来库中的表中的数据会继续存放于ibdata1中,新建的表才会使用独立表空间