基本概念¶
InfluxDB 数据模型¶
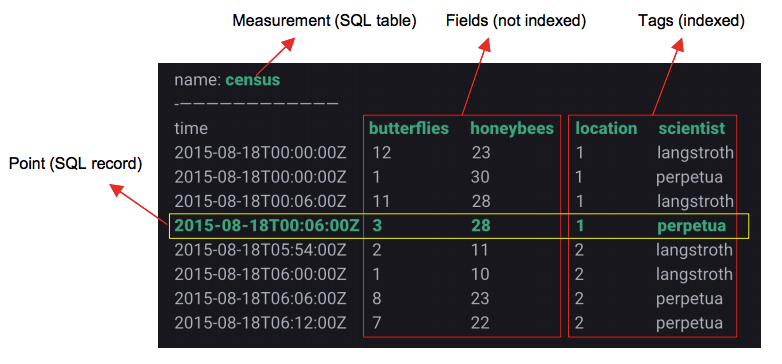
measurement:
tag,field和time列的容器
在概念上类似于传统DB的table(表格)
一个measurement可以有不同的保留策略(retention policies)
从原理上讲更像SQL中表的概念。这和其他很多时序数据库有些不同,其他时序数据库中Measurement可能与Metric等同
field(数值列):
TSDB For InfluxDB®中不能没有field。
注意:field是没有索引的
tag(维度列):
tag不是必须要有的字段
tag是被索引的,这意味着以tag作为过滤条件的查询会更快
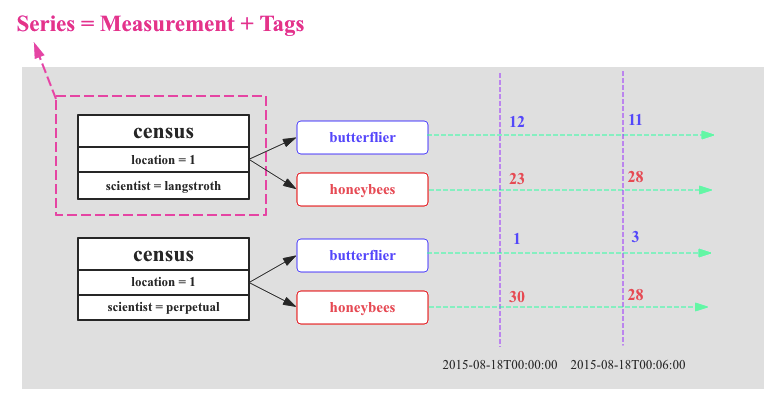
Series(时间线)¶
Series是InfluxDB中最重要的概念:
时序数据的时间线就是:
一个数据源采集的一个指标随着时间的流逝而源源不断地吐出数据
这样形成的一条数据线称之为时间线
下图中有两个数据源,每个数据源会采集两种指标:
butterflier和honeybees
InfluxDB中使用Series表示数据源,
Series由Measurement和Tags组合而成,
Tags组合用来唯一标识Measurement
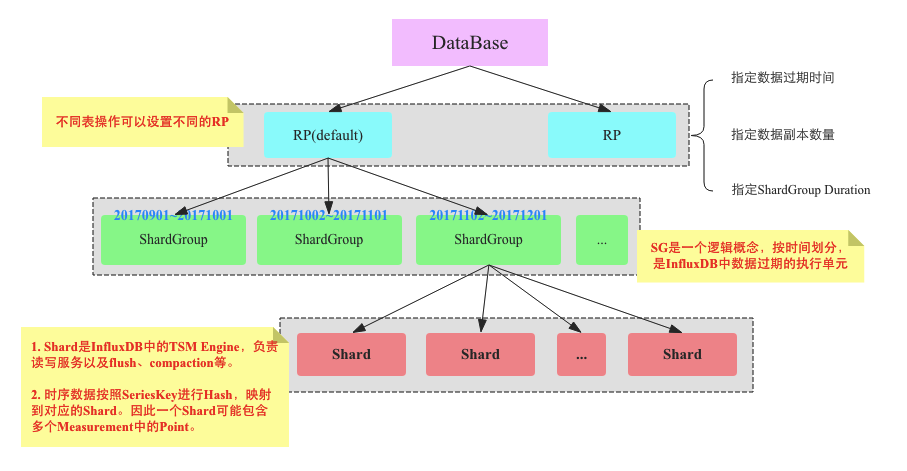
retention policy(保留策略,简称RP)¶
一个保留策略描述了:
1.InfluxDB保存数据的时间(DURATION)
2.以及存储在集群中数据的副本数量(REPLICATION)
3.指定ShardGroup Duration
注:复本系数(replication factors)不适用于单节点实例。
autogen:无限的存储时间并且复制系数设为1
RP创建语句如下:
CREATE RETENTION POLICY <retention_policy_name> ON <database_name>
DURATION <duration> REPLICATION <n> [SHARD DURATION <duration> ] [DEFAULT]
实例:
CREATE RETENTION POLICY "one_day_only" ON "water_database"
DURATION 1d REPLICATION 1 SHARD DURATION 1h DEFAULT
InfluxDB中Retention Policy有这么几个性质和用法:
1. RP是数据库级别而不是表级别的属性。这和很多数据库都不同。
2. 每个数据库可以有多个数据保留策略,但只能有一个默认策略。
3. 不同表可以根据保留策略规划在写入数据的时候指定RP进行写入
写入时指定rp进行写入:
% 如果没有指定任何RP,则使用默认的RP
curl -X POST 'http://localhost:8086/write?db=mydb&rp=six_month_rollup'
--data-binary 'disk,host=server01 value=442221834240i 1435362189575692182'
其他¶
timestamp:
默认使用服务器的本地时间戳
时间戳是UNIX时间戳,单位:纳秒
最小的有效时间戳是-9223372036854775806或1677-09-21T00:12:43.145224194Z
最大的有效时间戳是9223372036854775806或2262-04-11T23:47:16.854775806Z
continuous query(连续查询,简称CQ):
一个InfluxQL查询,在数据库中自动地、周期性地运行
连续查询要求在SELECT子句中有一个函数(function),并且必须包含一个GROUP BY time()子句
point(数据点):
由序列(series)中包含的field组成。每个数据点由它的序列和时间戳(timestamp)唯一标识
您不能在同一序列存储多个有相同时间戳的数据点
schema(模式):
@todo
颗粒度:
字母 意思
===== =======
u或µ 微秒
ms 毫秒
s 秒
m 分钟
h 小时
d 天
w 星期
InfluxDB 系统架构: