文件存储机制¶
概述¶
说明:
1. log.segment.bytes默认指定为1G时,超过1G会生成新的segment
2. log.roll.hours默认指定为168(7天), 所以5月30号前的数据都删除了
实例:
$ cd /<kafka-log-data>/topic-0
$ ls
-rw-r--r-- 1 root root 1.8M May 30 05:45 00000000000685179673.index
-rw-r--r-- 1 root root 1.0G May 30 05:45 00000000000685179673.log
-rw-r--r-- 1 root root 0 May 30 05:45 00000000000685179673.timeindex
-rw-r--r-- 1 root root 1.8M May 31 08:06 00000000000686566062.index
-rw-r--r-- 1 root root 1.0G May 31 08:06 00000000000686566062.log
-rw-r--r-- 1 root root 0 May 31 08:06 00000000000686566062.timeindex
... // 下面还没到1G继续增加中
-rw-r--r-- 1 root root 10M Jun 5 14:06 00000000000693444817.index
-rw-r--r-- 1 root root 955M Jun 5 14:07 00000000000693444817.log
-rw-r--r-- 1 root root 10M Jun 4 13:34 00000000000693444817.timeindex
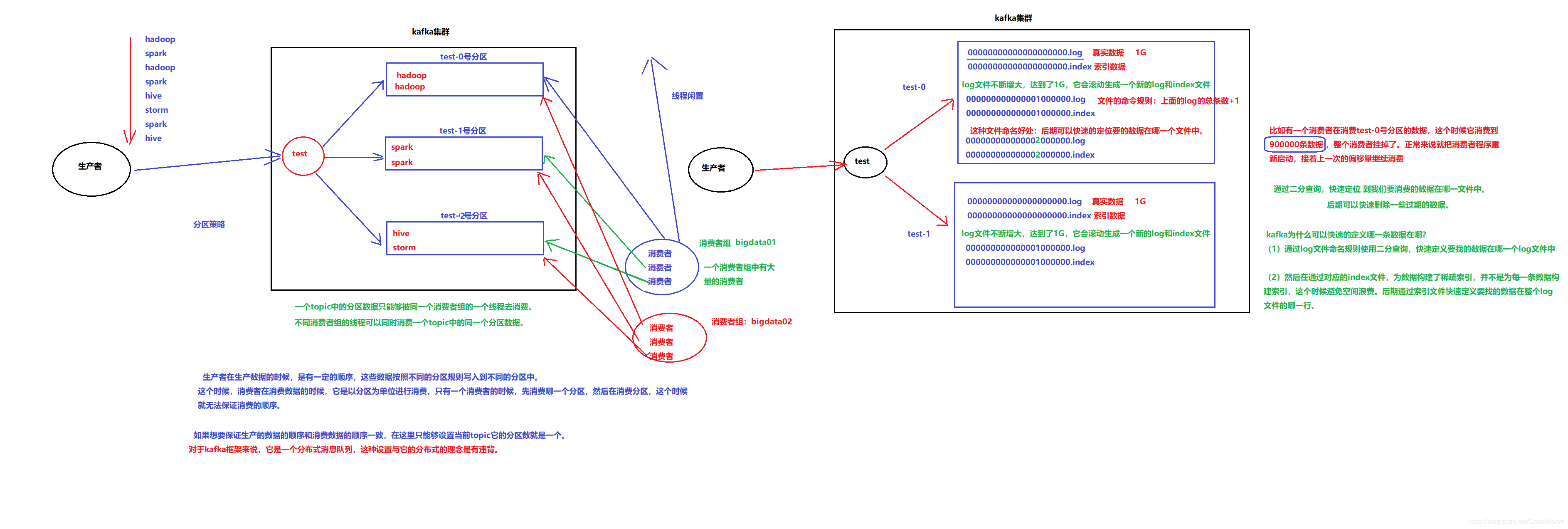
Segment文件¶
Segment file是什么(log和index文件 Segment默认大小1个G):
生产者生产的消息按照一定的分组策略被发送到broker中partition中的时候,这些消息如果在内存中放不下了,就会放在文件中。
partition在磁盘上就是一个目录,该目录名是topic的名称加上一个序号
在这个partition目录下,有两类文件,一类是以log为后缀的文件,一类是以index为后缀的文件
每一个log文件和一个index文件相对应,这一对文件就是一个segment file,也就是一个段。
其中的log文件就是数据文件,里面存放的就是消息,而index文件是索引文件,索引文件记录了元数据信息。
Segment文件特点:
segment文件命名的规则:partition全局的第一个segment从0(20个0)开始
后续的每一个segment文件名是上一个segment文件中最后一条消息的offset值。
那么这样命令有什么好处呢?:
假如我们有一个消费者已经消费到了368776(offset值为368776),那么现在我们要继续消费的话,怎么做呢?
看下图,分2个步骤
第1步是从所有文件log文件的的文件名中找到对应的log文件,第368776条数据位于上图中的“00000000000000368769.log”这个文件中
第2步是到index文件中去找第368776条数据所在的位置。
索引文件(index文件)中存储着大量的元数据,而数据文件(log文件)中存储这大量的消息。
索引文件(index文件)中的元数据指向对应的数据文件(log文件)中消息的物理偏移地址。
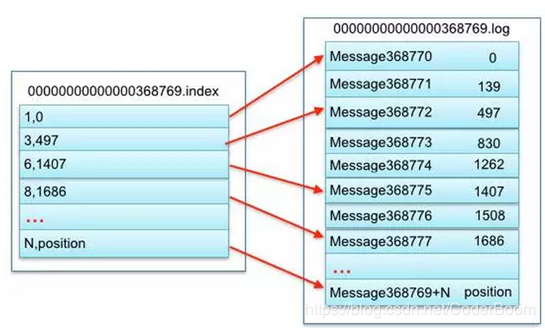
上图的左半部分是索引文件,里面存储的是一对一对的key-value:
其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”
分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引
这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中
但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了
其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息)
其中497表示该消息的物理偏移地址(位置)为497