使用聚合¶
● MongoDB 聚合框架(Aggregation Framework)是一个计算框架,它可以:
• 作用在一个或几个集合上;
• 对集合中的数据进行的一系列运算;
• 将这些数据转化为期望的形式;
● 从效果而言,聚合框架相当于 SQL 查询中的:
• GROUP BY
• LEFT OUTER JOIN
• AS等
聚合运算的基本格式:
pipeline = [$stage1, $stage2, ...$stageN];
db.<COLLECTION>.aggregate(
pipeline, { options }
);
管道(Pipeline)和步骤(Stage)¶
整个聚合运算过程称为管道(Pipeline),它是由多个步骤(Stage)组成的,每个管道:
• 接受一系列文档(原始数据);
• 每个步骤对这些文档进行一系列运算;
• 结果文档输出给下一个步骤

常见步骤(Stage):
步骤 作用 SQL等价运算符
=== === ===
$match 过滤 WHERE
$project 投影 AS
$sort 排序 ORDER BY
$group 分组 GROUP BY
$skip/$limit 结果限制 SKIP/LIMIT
$lookup 左外连接 LEFT OUTER JOIN
$unwind 展开数组 N/A
$graphLookup 图搜索 N/A
$facet/$bucket 分面搜索 N/A

常见步骤中的运算符¶
示例¶
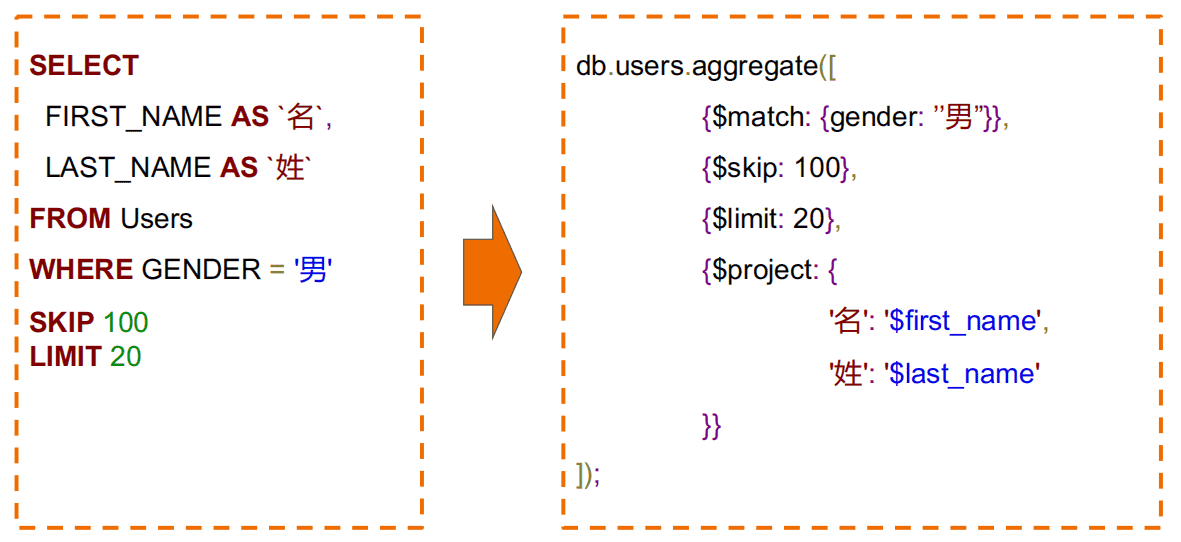
$project(投影)示例¶
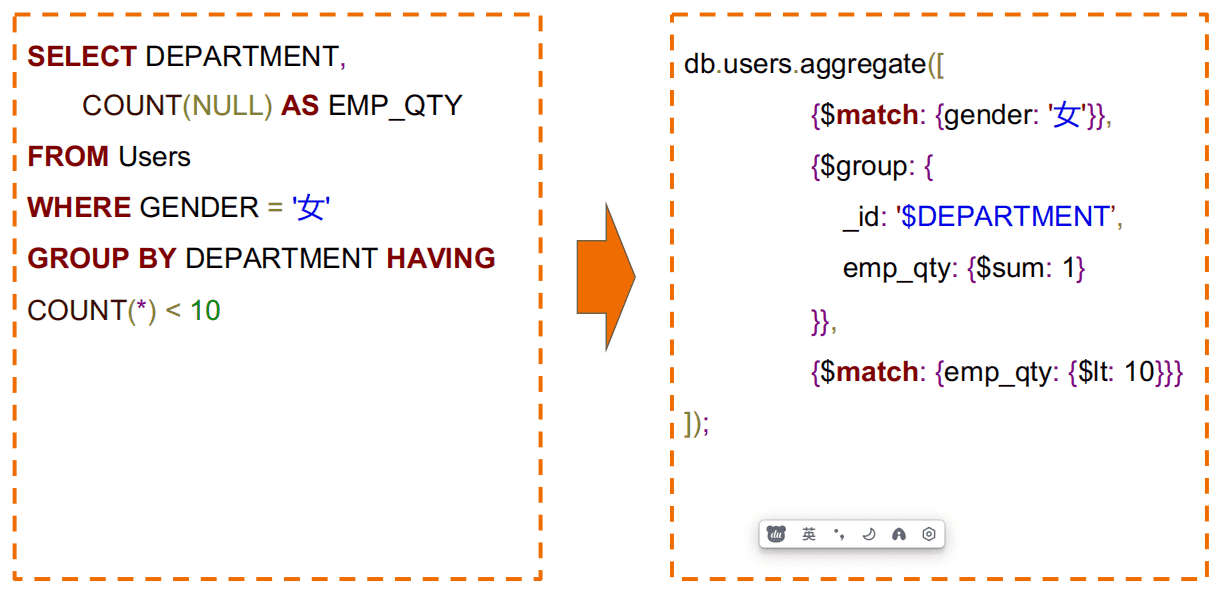
$match(过滤)示例¶

$unwind(展开数组)示例¶
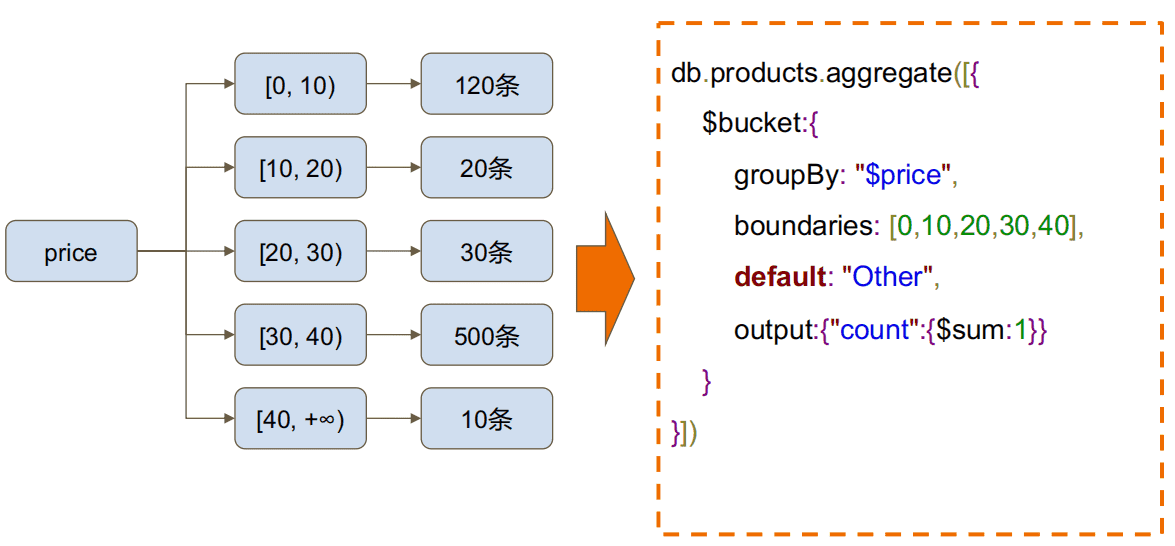
$bucket(分面搜索)示例¶
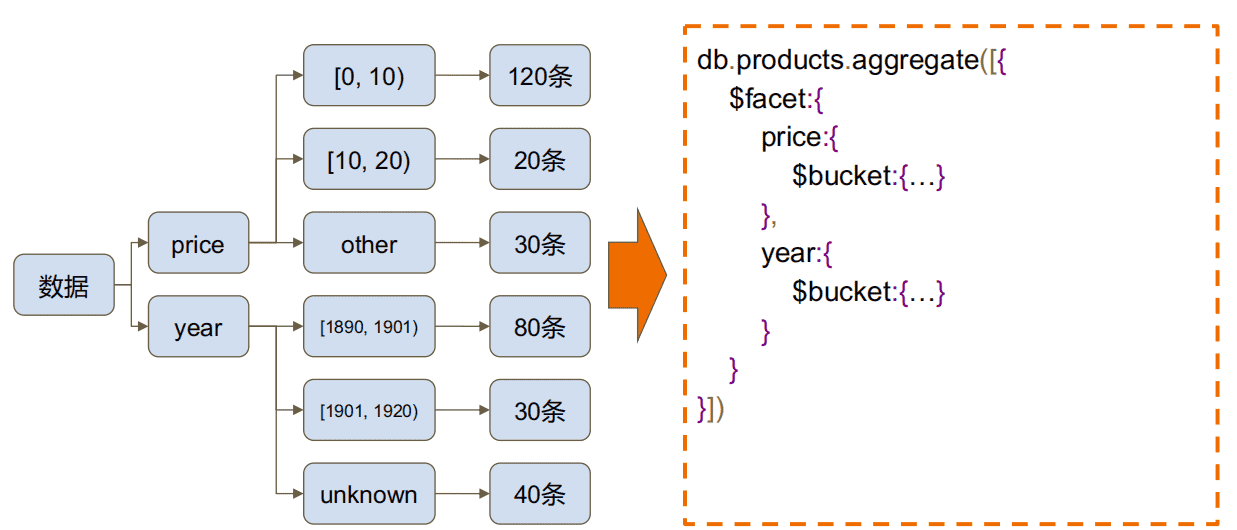
$facet(分面搜索)示例¶
实例¶
统计笔画数为 10 的字有多少个:
db.getCollection("word").aggregate([{
$match: {
strokes: 10
}
}, {
$group: {
_id: 1,
count: {
$sum: 1
}
}
}])
一个集合:
{
from: "user_1",
to: "user_2",
text: "毕竟西湖六月中",
time: ISODate("2018-10-01T00:02:12.000")
}
{
from: "user_2",
to: "user_1",
text: "风光不与四时同",
time: ISODate("2018-10-01T10:12:33.000")
}
{
from: "user_2",
to: "user_3",
text: "车遥遥,马憧憧,君游东山东复东",
time: ISODate("2018-10-01T19:44:21.000")
}
备注
在使用聚合时,每个管道默认允许占用的内存不超过 100M,否则会抛出错误。
指定使用磁盘来缓存结果:
// 这只是一个容错的方案,并非一个好的方案
db.collection.aggregate(pipelines, { allowDiskUse: true })
两个用户之间最近一个月的聊天时间分布情况:
早上 5 点 30 分到晚上 7 点为白天,其余时间为夜晚
按照这两个区间分别统计白天和夜晚的聊天数
db.getCollection("chat").aggregate([{
// 第一个管道匹配出最近一个月两个人的所有聊天记录,可以覆盖索引
$match: {
from: {
$in: ["user_1", "user_2"]
},
to: {
$in: ["user_1", "user_2"]
},
time: {
$gte: ISODate("2018-10-01T00:00:00.000")
}
}
}, {
$project: {
date: {
// 将 time 字段转换为类似于 2018-10-01 的形式
$dateToString: {
format: "%Y-%m-%d", date: "$time"
}
},
hourAndMinute: {
// 提取时间的时分两个值,转换为类似于 14:20 的形式
$dateToString: {
format: "%H:%M", date: "$time"
}
}
}
}, {
$group: {
_id: "$date",
daytime: {
$sum: {
$cond: {
if: {
$and: [{
$gte: ["$hourAndMinute", "05:30"]
}, {
$lte: ["$hourAndMinute", "19:00"]
}]
}, then: 1, else: 0
}
}
},
night: {
$sum: {
$cond: {
if: {
$and: [{
$gte: ["$hourAndMinute", "05:30"]
}, {
$lte: ["$hourAndMinute", "19:00"]
}]
}, then: 0, else: 1
}
}
}
}
}])