4.3. 实例¶
4.3.1. 1. 数字¶
基本¶
匹配正数、负数和小数:
[-+]?\d+(?:\.\d+)?
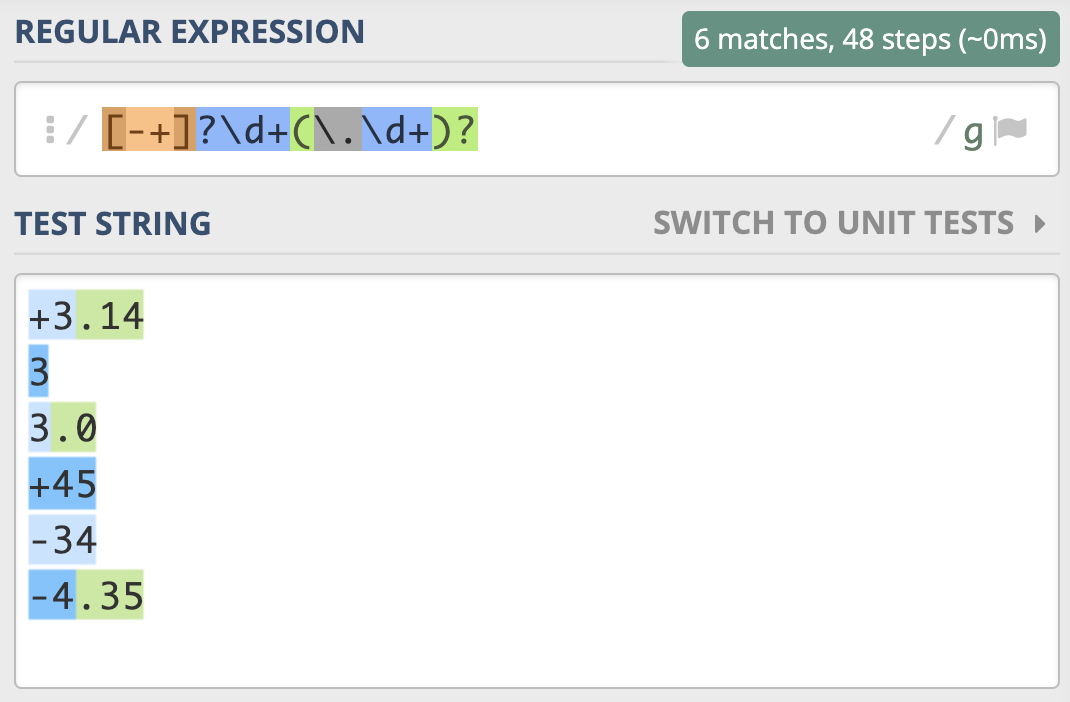
匹配正数、负数和小数的正则¶
其他:
1. 非负整数,包含 0 和 正整数
[1-9]\d*|0
2. 非正整数,包含 0 和 负整数
-[1-9]\d*|0
浮点数¶
[-+]?\d+(?:\.\d+)?
考虑可以有 .5 和 +.5 这样的写法,但一般不会有 -.5 这样的写法。负号的时候整数部分不能没有,而正数的时候,整数部分可以没有,所以正则你可以将正负两种情况拆开,使用多选结构写成:
-?\d+(?:\.\d+)?|\+?(?:\d+(?:\.\d+)?|\.\d+)
负数浮点数表示:-\d+(?:\.\d+)?
正数浮点数表示:\+?(?:\d+(?:\.\d+)?|\.\d+)
十六进制数¶
[0-9A-Fa-f]+
4.3.2. 常见码¶
手机号码¶
如果只限制前 2 位:
1[3-9]\d{9}
限制到前三位:
1(?:3\d|4[5-9]|5[0-35-9]|6[2567]|7[0-8]|8\d|9[1389])\d{8}
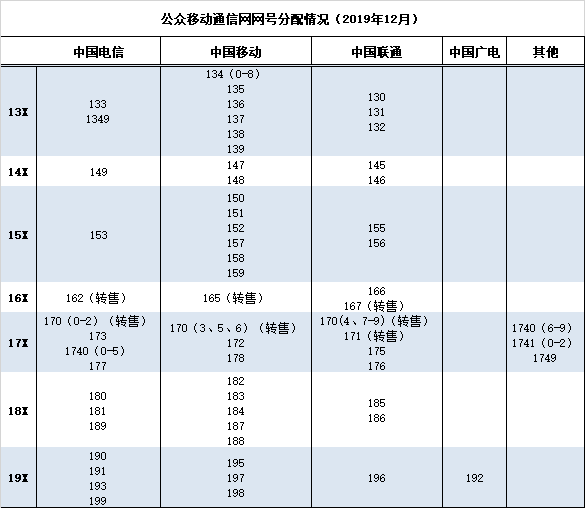
截止 2019 年 12 月,我国公众移动通信网网号分配情况¶
身份证号码¶
规则:
1. 分两代的,第一代是 15 位,第二代是 18 位
2. 如果是 18 位,最后一位可以是 X(或 x),两代开头都不能是 0
[1-9]\d{14}(\d\d[0-9Xx])?
邮政编码¶
1. 简单版:
\d{6}
2. 添加断言版
(?<!\d)\d{6}(?!\d)
腾讯 QQ 号码¶
规则:
1. 不能以 0 开头
2. 最长的有 10 位,最短的从 10000(5 位)开始
[1-9][0-9]{4,9}
日期和时间¶
日期:
简单版:
\d {4}-\d {2}-\d {2}
正常版:
\d{4}-(?:1[0-2]|0?[1-9])-(?:[12]\d|3[01]|0?[1-9])
时间:
(?:2[0-3]|1\d|0?\d):(?:[1-5]\d|0?\d)
邮箱¶
规则:
格式: 用户名 @主机名
用户名部分通常可以有英文字母,数字,下划线,点等组成,但其中点不能在开头,也不能重复出现
参见: RFC5322
根据 RFC5322 没有办法写出一个完美的正则
正则简体的版本:
[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+
4.3.3. IP¶
IPv4 地址¶
非正则版:
使用点号切割,验证一下是不是四个部分,每个部分是不是在 0-255 之间
比使用正则来校验要简单很多,而且不容易出错
简单版:
\d{1,3}(\.\d{1,3}){3}
针对一到三位数分别考虑:
一位数时可以表示成 0{0,2}\d
两位数时可以表示成 0?[1-9]\d
三位数时可以表示成 1\d\d|2[0-4]\d|25[0-5]
多选分支结构整合1-3位数:
0{0,2}\d|0?[1-9]\d|1\d\d|2[0-4]\d|25[0-5]
不补0版:
\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5]
如果IPv4 表示成 X.X.X.X
上面只是表示的 X
整合4个 X:
(?:\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:\.(?:\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])){3}
问题点: 最后一位因「匹配多分支选择结构的时候,优先匹配最左边的」而导致
如: 192.168.1.12 只会匹配到 192.168.1.1
把3位的放前面:
(?:\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(?:\.(?:2[0-4]\d|25[0-5]|[1-9]\d|1\d\d|\d)){3}
其他可选实例参考:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
((25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)
IPv6¶
前导匹配正则表达式:
[0-9A-Fa-f]{4}(?:\:(?:[0-9A-Fa-f]{4})){7}
省略前导 0 正则表达式:
(?:0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})(?:\:(?:0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})){7}
中文字符¶
1. 中文属于多字节 Unicode 字符,可以通过 Unicode 属性
缺点: 有一些语言是不支持这种属性
2. 码值的范围
码值的范围方式:
Python,Java,JavaScript:
格式: [\u4E00-\u9FFF]
示例:
# 测试环境,Python3
>>> import re
>>> reg = re.compile(r'[\u4E00-\u9FFF]')
>>> reg.findall("和伟忠一起学正则 regex")
[' 和', ' 伟', ' 忠', ' 一', ' 起', ' 学', ' 正', ' 则']