1.1.2. Unicode¶
2020 年 3 月 10 日公布的 13.0.0,已经收录超过 14 万个字符
2020 年 3 月 10 日公布的 Unicode 标准 13.0.0 中,新增了 55 个新的 emoji 表情
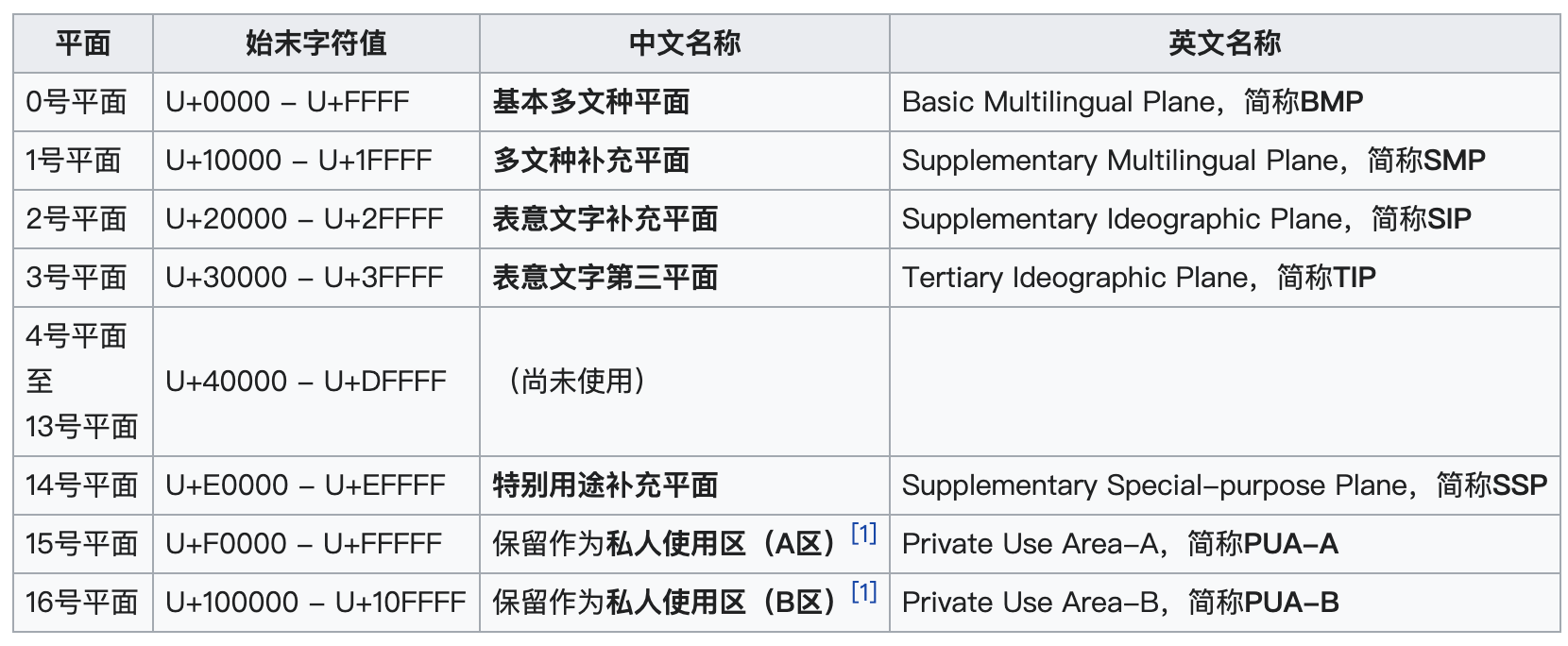
现在的 Unicode 字符分为 17 组编排,每组为一个平面(Plane),而每个平面拥有 65536(即 2 的 16 次方)个码值(Code Point)。我们用到的绝大多数字符都属于第 0 号平面,即 BMP 平面。除了 BMP 平面之外,其它的平面都被称为补充平面。¶
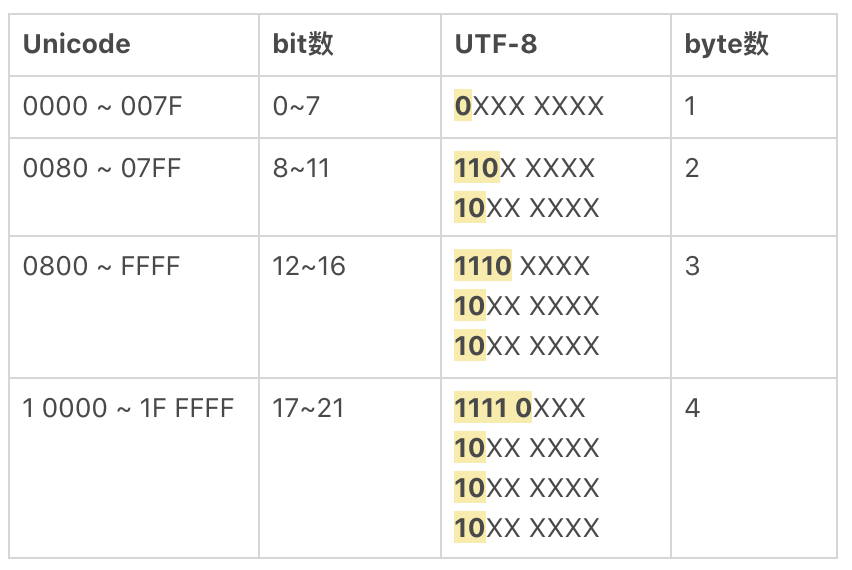
Unicode 和 UTF-8 的转换规则¶
实例¶
测试环境 macOS/Linux,Python 2.7(Python3.x默认使用unicode编码):
>>> import re
>>> re.compile(r'[时间]', re.DEBUG)
in
literal 230
literal 151
literal 182
literal 233
literal 151
literal 180
Out[3]: re.compile(r'[\xe6\x97\xb6\xe9\x97\xb4]', re.DEBUG)
>>> re.compile(ur'[时间]', re.DEBUG)
in
literal 26102
literal 38388
Out[2]: re.compile(ur'[\u65f6\u95f4]', re.DEBUG)
查看文本编码成 UTF-8 或 GBK 方式,以及编码的结果:
# UTF-8
>>> u' 极客'.encode('utf-8')
'\xe6\x9e\x81\xe5\xae\xa2' # 含有 e6
>>> u' 时间'.encode('utf-8')
'\xe6\x97\xb6\xe9\x97\xb4' # 含有 e6
# GBK
>>> u' 极客'.encode('gbk')
'\xbc\xab\xbf\xcd' # 含有 bc
>>> u' 时间'.encode('gbk')
'\xca\xb1\xbc\xe4' # 含有 bc
Python 测试的结果:
# Python 2.7
>>> import re
>>> re.findall(r'^.$', '学') # 注: 会先把'学'转化为 UTF-8(Linux)或 GBK(Windows)
[]
>>> re.findall(r'^.$', u'学') # 转为 unicode 编码
[u'\u5b66']
>>> re.findall(r'^.+$', '学') # 1. 查看默认编码
['\xe5\xad\xa6']
>>> re.findall(r'^.+$', u'学'.encode('utf-8')) # 2. 指定 utf-8编码
['\xe5\xad\xa6']
>>> re.findall(r'^.+$', u'学'.encode('gbk')) # 3. 指定 GBK 编码
['\xd1\xa7']
# Python 3.7
>>> import re
>>> re.findall(r'^.$', '学')
[' 学']
>>> re.findall(r'(?a)^.$', '学')
[' 学']
Unicode¶
Unicode 只规定了字符对应的码值,如果要进行存储或者网络传输等,这个码值得编码成字节,常见的编码方式是 UTF-8。
在内存中使用的时候可以使用 unicode,但存储到硬盘里时就得转换成字节编码形式。
Unicode字符集(简称为UCS),国际标准组织于1984年4月成立ISO/IEC JTC1/SC2/WG2工作组,针对各国文字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium,并于1991年10月与WG2达成协议,采用同一编码字集。目前Unicode是采用16位编码体系,其字符集内容与 ISO10646的BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard),目前版本V2.0于1996公布,内容包含符号6811个,汉字20902个,韩文拼音11172个,造字区6400个,保留 20249个,共计65534个。Unicode编码后的大小是一样的.例如一个英文字母 “a” 和 一个汉字 “好”,编码后都是占用的空间大小是一样的,都是两个字节!
Unicode可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母’a’为”00 61”。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询 unicode.org,或者专门的汉字对应表。 http://www.chi2ko.com/tool/CJK.htm
Unicode的问题¶
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。
平面Panel¶
Unicode代码空间共有17个平面(Plane),平面编号从0至16,每个平面可以表示65536个码位(Code Point)。
BMP 是Unicode代码空间内最常用的平面,绝大部分字符都位于这个平面内,UTF-8 和 UTF-16 等编码方式主要是为了对 BMP 中的字符进行编码和解码。
SIP 和 TIP 中的字符较为生僻,常用的编码方式(如UTF-8和UTF-16)无法直接表示这些字符,需要使用UTF-32等编码方式才能正确表示这些字符。
Unicode 编码点分为 17 个平面(plane),每个平面包含 2^16(即 65536)个码位(code point)。17 个平面的码位都可表示为从 U+xx0000 到 U+xxFFFF,其中 xx 表示十六进制值从 0016 到 1016,共计 17 个平面。
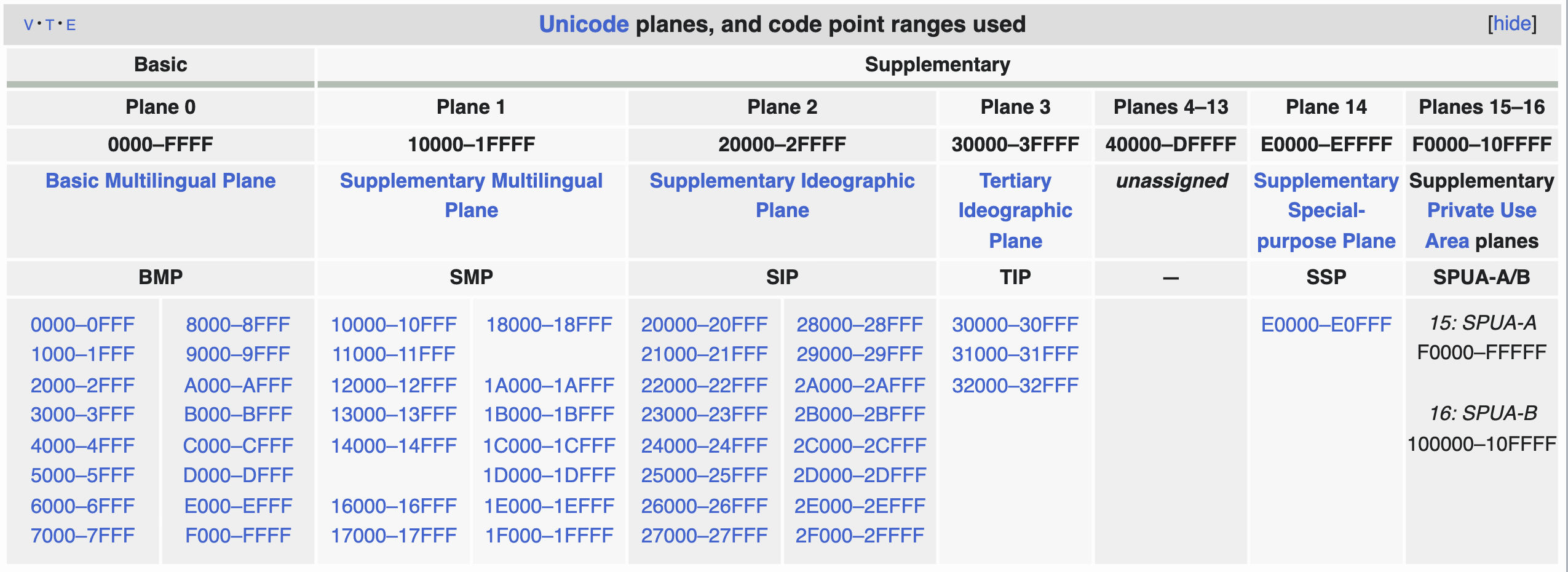
编号0: BMP¶
基本多文种平面(Basic Multilingual Plane)
包含了常用的汉字、拉丁字母、数字、标点符号以及其他一些字符。
它的代码范围是U+0000至U+FFFF,共计65536个码位。
BMP中包括了大部分基本的拉丁字母、希腊字母、西里尔字母、标点符号、数字、符号以及各种语言的基本字形。
代理区¶
还有一个被称为代理区 (Surrogate Zone) 的特殊区域:0xD800-0xDFFF (十进制 55296~57343),共 2048 个码点,这些码点被称之为代理码点,
目的是用基本平面 BMP 中的两个码点 “代理” 表示 BMP 以外的其他增补平面 SP 中的字符。
私用区¶
PUA:Private Use Area,也写作 PUZ:Private Use Zone):0xE000~0xF8FF (十进制 57344~63743),共 6400 个码点,被保留为私用,
Unicode 官方未将之分配给任何 Unicode 字符,因而可根据需要由合作者之间私下协商将其分配给私有字符 (类似于 Glyphicons、FontAwesome、fontello 这样的私有图标字体字符,其码点就是使用的私用区中的码点)。
备注
Unicode 标准到目前为止实际上共定义了三个私用区:一个为如上所述的第 0 平面 (即 BMP) 中的 U+E000~U+F8FF,另外两个几乎包含了整个第 15 平面和第 16 平面,分别为 U+F0000~U+FFFFD 和 U+100000~U+10FFFD。私用区相当于可以由 Unicode 官方之外的个人和机构自由定义字符的特殊区域,因此私用区中的同一个码点,可被分配给不同的字符,具体是哪个字符取决于字体文件,从而不同的用户由于安装了不同的字体文件,有可能所看到的字符也不同。
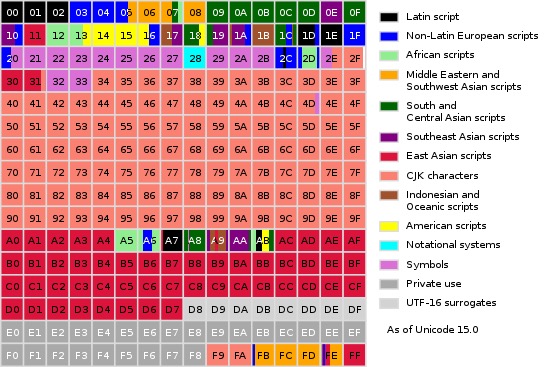
A map of the Basic Multilingual Plane. Each numbered box represents 256 code points.¶
编号1: SMP¶
补充字符平面(Supplementary Multilingual Plane)
代码范围是U+10000至U+1FFFF,共计65536个码位。
它包括了许多历史文化遗产、人类学、地图学、数学和音乐符号等,也包括了一些较新的Unicode字符集,如Emoji表情符号、部分较少使用的中日韩字符等。
编号2: SIP¶
补充字符平面(Supplementary Ideographic Plane)
代码范围是U+20000至U+2FFFF,共计65536个码位。
它主要包括了大量的CJK(中文、日文、韩文)以及中文古代汉字、古文献中的生僻汉字、藏文、满文、太阳帆船文字等各种字符。
平面3包含了现代中文、日文、韩文中的大部分汉字,以及一些不常用或生僻的汉字,例如《康熙字典》中的汉字都被包含在这个平面中。
编号3: TIP¶
辅助平面(Supplementary Multilingual Plane,SMP)
包含了一些辅助性质的字符,例如数学符号、音乐符号、表情符号等。其中,较为著名的是Emoji表情符号,这些符号在移动设备和社交媒体应用程序中非常流行。
历史¶
国际标准化组织(ISO),他们于 1984 年创建 ISO/IEC JTC1/SC2/WG2 工作组,试图制定一份 “通用字符集”(Universal Character Set,简称 UCS),并最终制定了 ISO 10646 标准。
统一码联盟,他们由 Xerox、Apple 等软件制造商于 1988 年组成,并且开发了 Unicode 标准(The Unicode Standard,这个前缀 Uni 很牛逼哦 —Unique, Universal, and Uniform)。
1991 年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从 Unicode 2.0 开始,Unicode 采用了与 ISO 10646-1 相同的字库和字码;ISO 也承诺,ISO 10646 将不会替超出 U+10FFFF 的 UCS-4 编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。不过由于 Unicode 这一名字比较好记,因而它使用更为广泛。
UTF-32 与 UCS-4¶
在 Unicode 与 ISO 10646 合并之前,ISO 10646 标准为 “通用字符集”(UCS)定义了一种 31 位的编码形式(即 UCS-4),其编码固定占用 4 个字节,编码空间为 0x00000000~0x7FFFFFFF(可以编码 20 多亿个字符)。
UCS-4 有 20 多亿个编码空间,但实际使用范围并不超过 0x10FFFF,并且为了兼容 Unicode 标准,ISO 也承诺将不会为超出 0x10FFFF 的 UCS-4 编码赋值。由此 UTF-32 编码被提出来了,它的编码值与 UCS-4 相同,只不过其编码空间被限定在了 0~0x10FFFF 之间。因此也可以说:UTF-32 是 UCS-4 的一个子集。
UTF-16 与 UCS-2¶
除了 UCS-4,ISO 10646 标准为 “通用字符集”(UCS)定义了一种 16 位的编码形式(即 UCS-2),其编码固定占用 2 个字节,它包含 65536 个编码空间(可以为全世界最常用的 63K 字符编码,为了兼容 Unicode,0xD800-0xDFFF 之间的码位未使用)。例:“汉” 的 UCS-2 编码为 6C49。
但俩个字节并不足以正真地 “一统江湖”(a fixed-width 2-byte encoding could not encode enough characters to be truly universal),于是 UTF-16 诞生了,与 UCS-2 一样,它使用两个字节为全世界最常用的 63K 字符编码,不同的是,它使用 4 个字节对不常用的字符进行编码。UTF-16 属于变长编码。
Unicode 编码点分为 17 个平面(plane),每个平面包含 216(即 65536)个码位(code point),而第一个平面称为 “基本多语言平面”(Basic Multilingual Plane,简称 BMP),其余平面称为 “辅助平面”(Supplementary Planes)。
其中 “基本多语言平面”(0~0xFFFF)中 0xD800~0xDFFF 之间的码位作为保留,未使用。UCS-2 只能编码 “基本多语言平面” 中的字符,此时 UTF-16 与 UCS-2 的编码一样(都直接使用 Unicode 的码位作为编码值),例:“汉” 在 Unicode 中的码位为 6C49,而在 UTF-16 编码也为 6C49。另外,UTF-16 还可以利用保留下来的 0xD800-0xDFFF 区段的码位来对 “辅助平面” 的字符的码位进行编码,因此 UTF-16 可以为 Unicode 中所有的字符编码。
UTF-16 中如何对 “辅助平面” 进行编码¶
Unicode 的码位区间为 0~0x10FFFF,除 “基本多语言平面” 外,还剩 0xFFFFF 个码位(并且其值都大于或等于 0x10000)。对于 “辅助平面” 内的字符来说,如果用它们在 Unicode 中码位值减去 0x10000,则可以得到一个 0~0xFFFFF 的区间(该区间中的任意值都可以用一个 20-bits 的数字表示)。该数字的前 10 位 (bits) 加上 0xD800,就得到 UTF-16 四字节编码中的前两个字节;该数字的后 10 位 (bits) 加上 0xDC00,就得到 UTF-16 四字节编码中的后两个字节。例如:
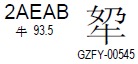
上面这个汉字的 Unicode 码位值为 2AEAB,减去 0x10000 得到 1AEAB(二进制值为 0001 1010 1110 1010 1011),前 10 位加上 D800 得到 D86B,后 10 位加上 DC00 得到 DEAB。于是该字的 UTF-16 编码值为 D86BDEAB(该值为大端表示,小端为 6BD8ABDE)。¶