4.1. 正则基本功能¶
备注
插入符号 ^ 和美元符号 $ 在正则表达式中具有特殊的意义,它们被称为 “锚点”。【另外】^,中文尚无通用名称,可以是插入符号、插入符、脱字符号、脱字符等;英文称为 Caret (英语发音:/ˈkærət/),是个倒 V 形的字素
4.1.1. 元字符(Metacharacter)¶
定义:
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件。
正则就是由一系列的元字符组成的
如:
\d 和 {11}
1. 特殊字符¶
常用特殊字符:
. 除换行外的任意字符(在英文环境下)
\d 数字 [0-9]
\D 非数字 [^0-9]
\s 空白字符[ \t\r\n\f]
\S 非空白字符[^ \t\r\n\f]
\w 单词字符[A-Za-z0-9_]
\W 非单词字符[^A-Za-z0-9_]
https://stackoverflow.com/a/11874614/2714931
\W would match any non-word character
and so its easy to try to use it to match word boundaries.
The problem is that it will not match the start or end of a line.
\d 对于Unicode(str类型)模式:匹配任何一个数字,包括[0-9]和其他数字字符
如果开启了re.ASCII,只匹配 [0-9]
\D与\d相反,如果开启了re.ASCII,只匹配 [^0-9]
\s 对于Unicode(str类型)模式:匹配Unicode中的空白字符(包括[\t\n\v\f\r]以及其他空白字符)
如果开启了re.ASCII标志,就只匹配[\t\n\f\v\r]
\S与\s相反,如果开启了re.ASCII标志,就只匹配[^\t\n\f\v\r]
\w于Unicode(str类型)模式:匹配任何Unicode的单词字符,基本上所以语言的字符都可以匹配,包括数字和下划线
如果开启了re.ASCII,只匹配[0-9a-zA-Z_]
\W与\w相反,如果开启了re.ASCII,只匹配[^0-9a-zA-Z_]
其他特殊字符:
\A匹配输入字符串的开始位置
\Z匹配输入字符串的结束位置
\u,\U只有在Unicode模式下才被识别
解释:
1. d 是 digit 数字
2. w 是 word 单词
3. s 是 space 空白
2. 空白符¶
\r 回车符
\n 换行符
\f 换页符
\t 制表符
\v 垂直制表符
3. 量词¶
1. 星号(*)代表出现 0 到多次
2. 加号(+)代表 1 到多次
3. 问号(?)代表 0 到 1 次
4. {m,n} 代表 m 到 n 次
5. {m} 代表 m 次
6. {m, } 代表最小 m 次
4. 范围¶
1. |: 或
如:
ab|bc 代表 ab 或 bc
2. [...]多选一
代表中括号内的任一元素
3. [a-z]代表a-z之间任一元素
4. [^...] 取反
4.1.2. 量词的贪婪, 非贪婪与独占模式¶
贪婪匹配(Greedy):
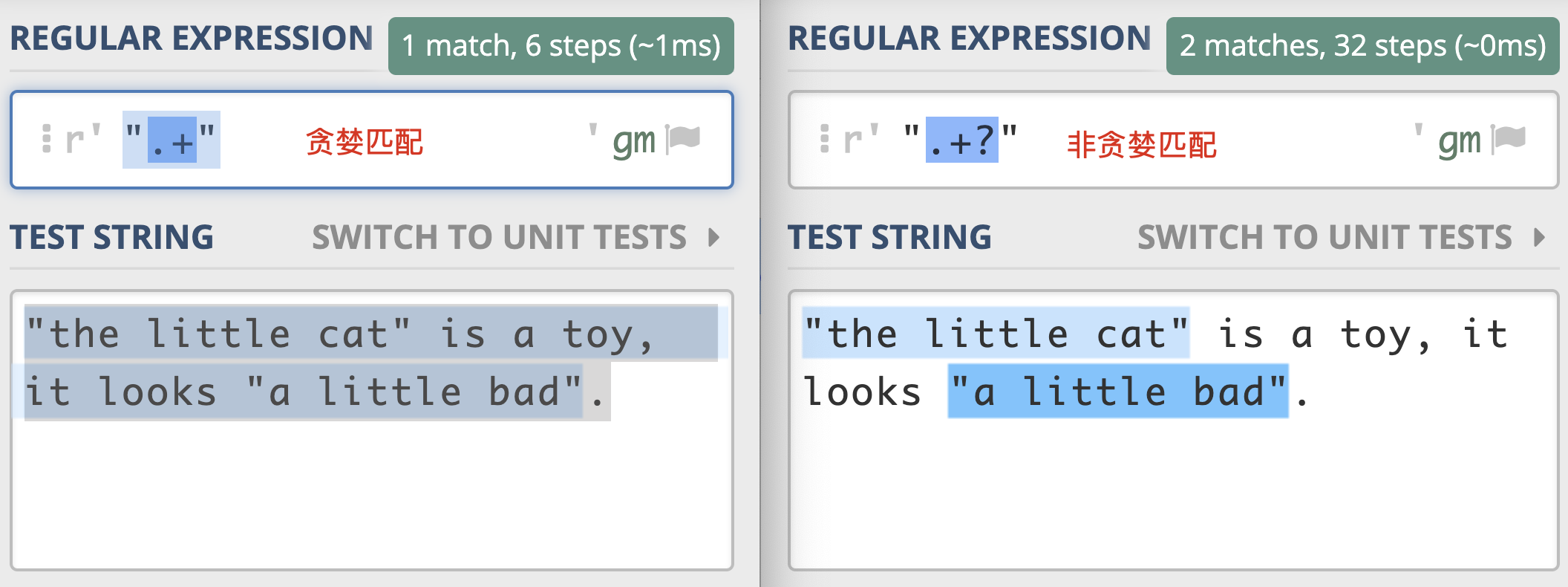
在正则中,表示次数的量词默认是贪婪的 贪婪模式的特点就是尽可能进行最大长度匹配。 如: a* a+非贪婪匹配(Lazy):
如何将贪婪模式变成非贪婪模式: 可以在量词后面加上英文的问号 (?),正则就变成了 a*? 非贪婪模式会尽可能短地去匹配
独占模式(Possessive):
类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好 如: regex = "xy{1,3}+yz" text = "xyyz" 使用「独占模式」就会匹配失败
警告
Python 和 Go 的标准库目前都不支持独占模式,会报错
示例:
>>> import re
>>> re.findall(r'a*', 'aaabb') # 贪婪模式
['aaa', '', '', '']
>>> re.findall(r'a*?', 'aaabb') # 非贪婪模式
['', 'a', '', 'a', '', 'a', '', '', '']
示例2:
>>> import regex
>>> regex.findall(r'xy{1,3}z', 'xyyz') # 贪婪模式
['xyyz']
>>> regex.findall(r'xy{1,3}+z', 'xyyz') # 独占模式
['xyyz']
>>> regex.findall(r'xy{1,2}+yz', 'xyyz') # 独占模式
[]
4.1.3. 分组&引用¶
分组与编号¶
备注
第几个括号就是第几个分组。只需要数左括号(开括号)是第几个,就可以确定是第几个子组

命名分组¶
备注
由于编号得数在第几个位置,后续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化,因此一些编程语言提供了命名分组(named grouping),这样和数字相比更容易辨识,不容易出错。命名分组的格式为 (?P < 分组名> 正则)。
示例:
^profile/(?P<username>\w+)/$
重要
命名分组并不是所有语言都支持的,在使用时,你需要查阅所用语言正则说明文档
分组引用¶
分组引用在查找中使用¶
分组引用在替换中使用¶
示例:
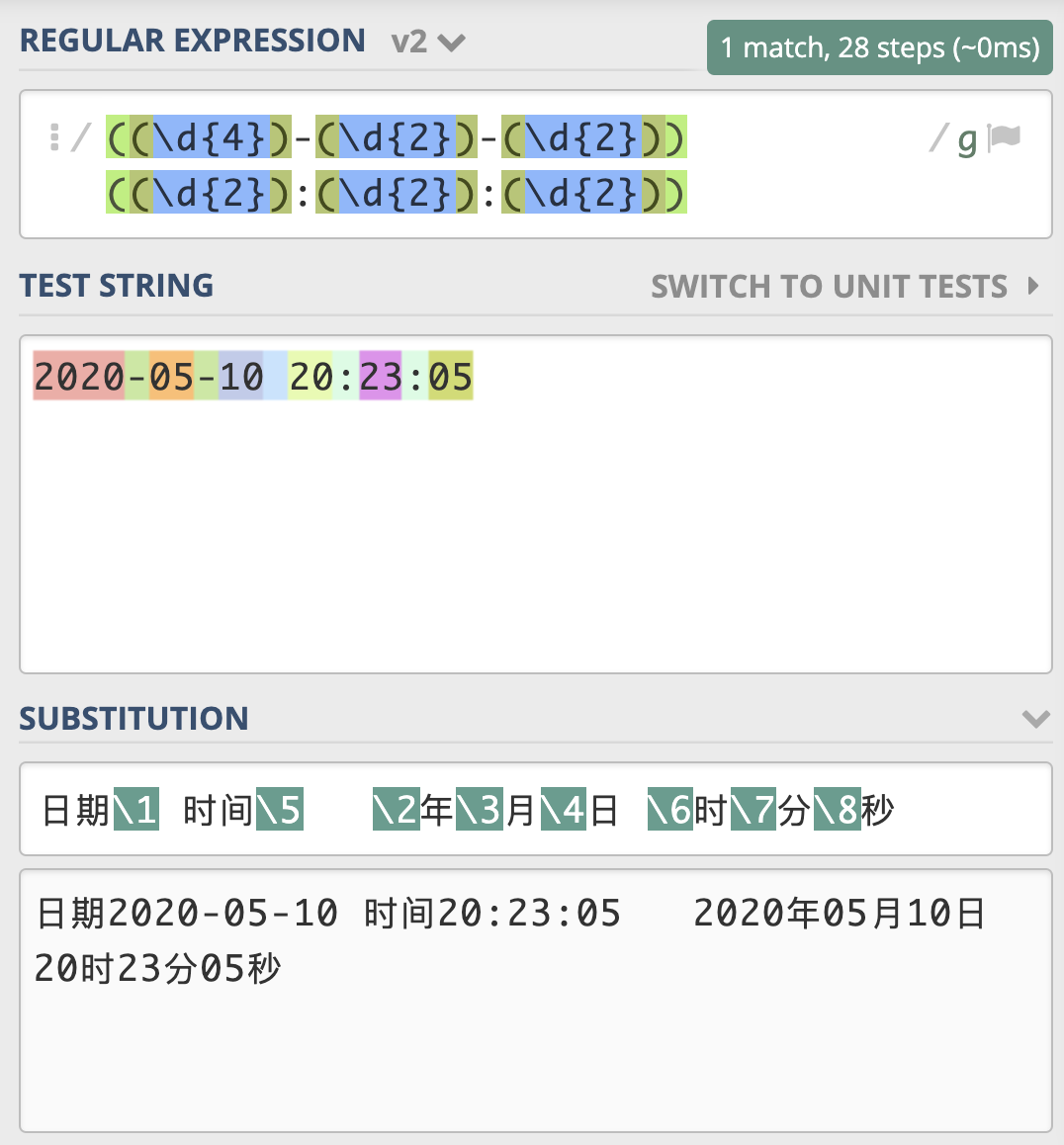
>>> import re
>>> test_str = "2020-05-10 20:23:05"
>>> regex = r"((\d{4})-(\d{2})-(\d{2})) ((\d{2}):(\d{2}):(\d{2}))"
>>> subst = r"日期 \1 时间 \5 \2 年 \3 月 \4 日 \6 时 \7 分 \8 秒"
>>> re.sub(regex, subst, test_str)
' 日期 2020-05-10 时间 20:23:05 2020 年 05 月 10 日 20 时 23 分 05 秒'
实例说明:
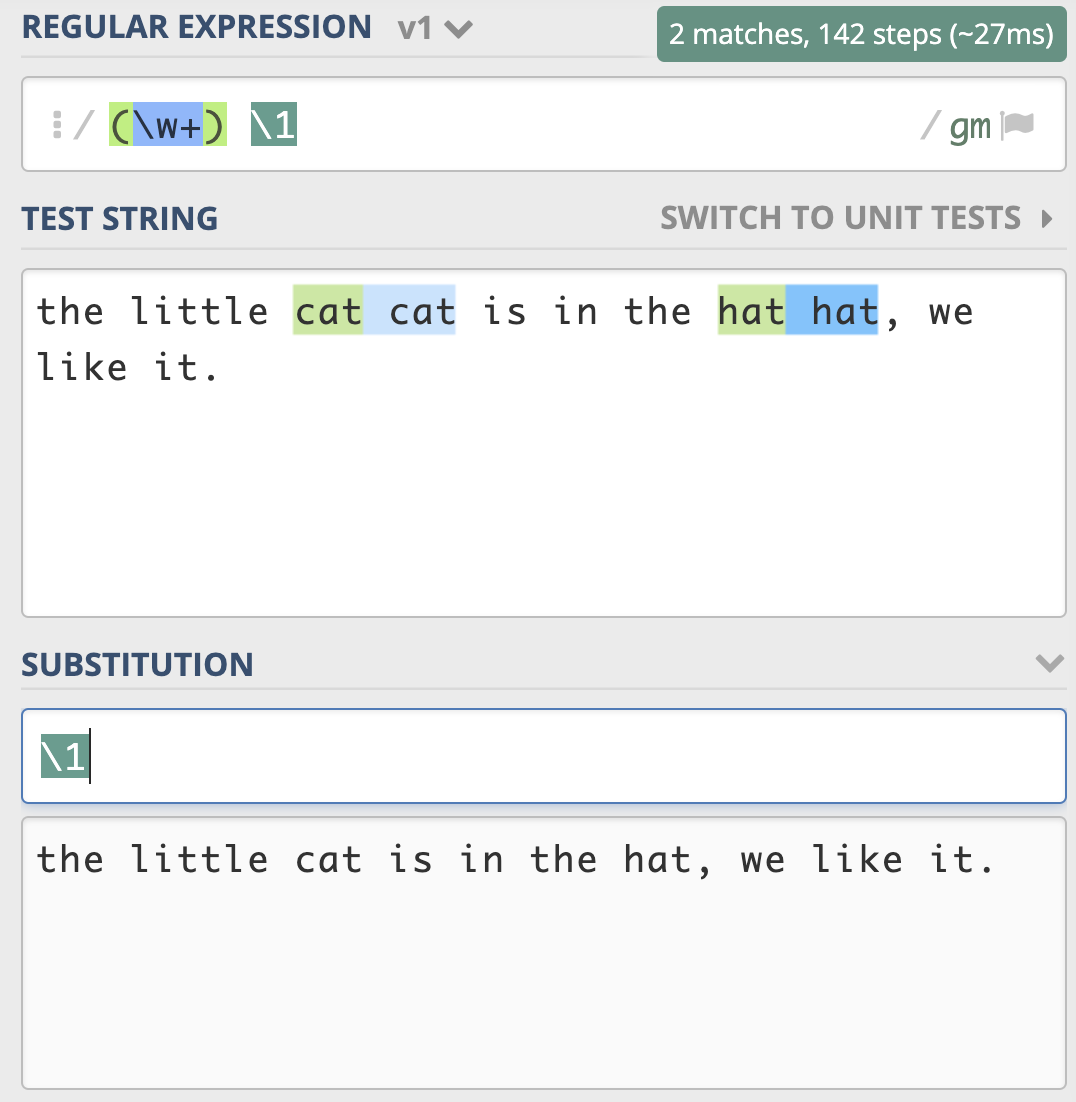
一篇英文文章,里面有一些单词连续出现了多次,我们认为连续出现多次的单词应该是一次
比如:
the little cat cat is in the hat hat hat, we like it.
其中 cat 和 hat 连接出现多次,要求处理后结果是
the little cat is in the hat, we like it.
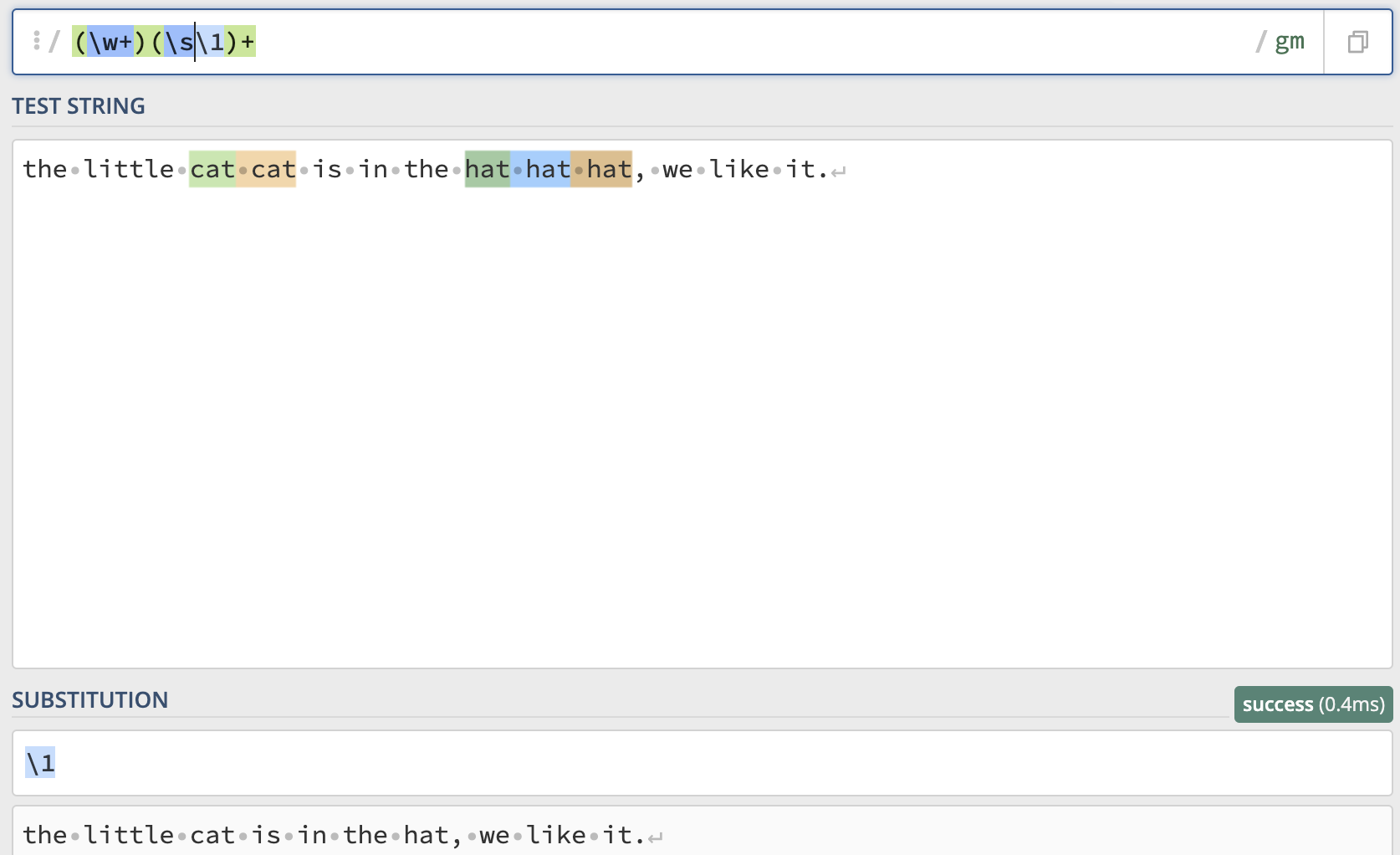
上面实例使用正则 (\w+)(\s\1)+¶
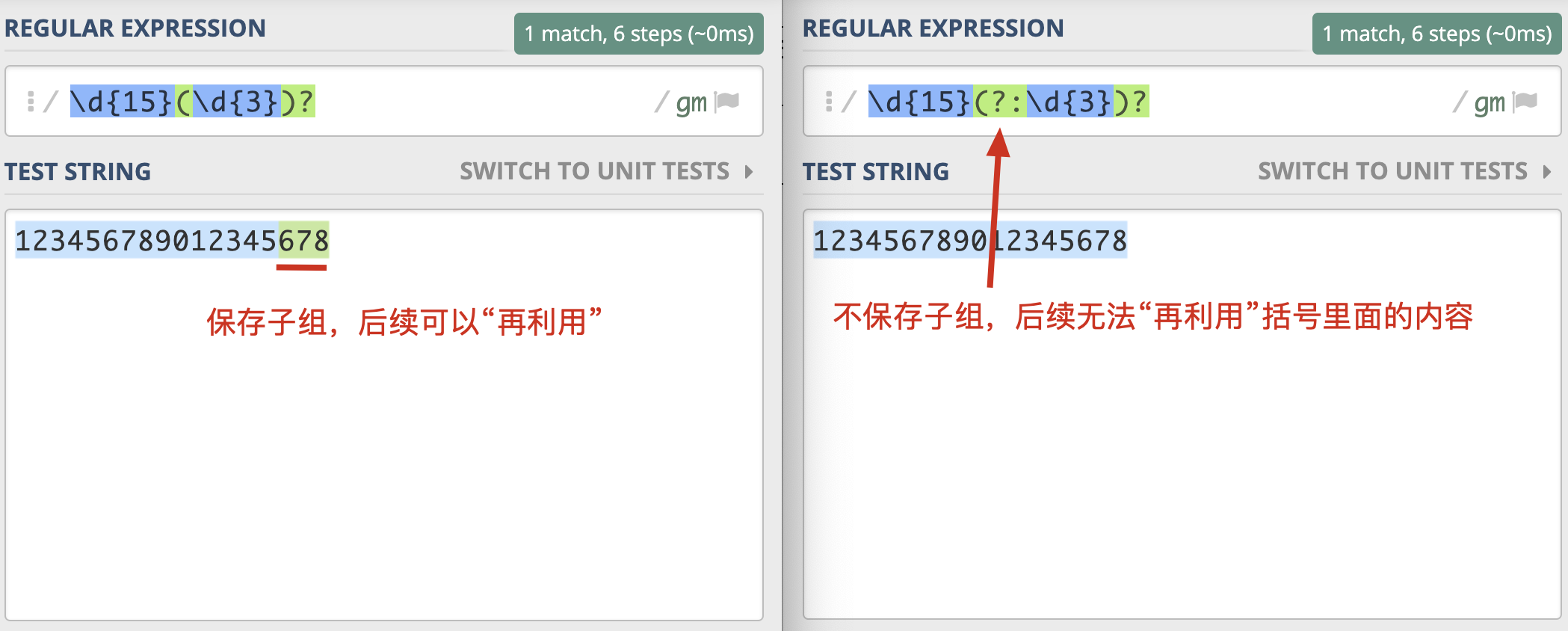
不保存子组¶
备注
如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,所以不保存子组可以提高正则的性能。

4.1.4. 匹配模式(Match Mode)¶
1. 不区分大小写模式(Case-Insensitive)¶
模式修饰符:
格式: (?模式标识)
如:
(?i)cat # 不区分大小写的 cat
要点:
1. 不区分大小写模式的指定方式,使用模式修饰符 (?i)
2. 修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则
3. 使用编程语言时可以使用预定义好的常量来指定匹配模式
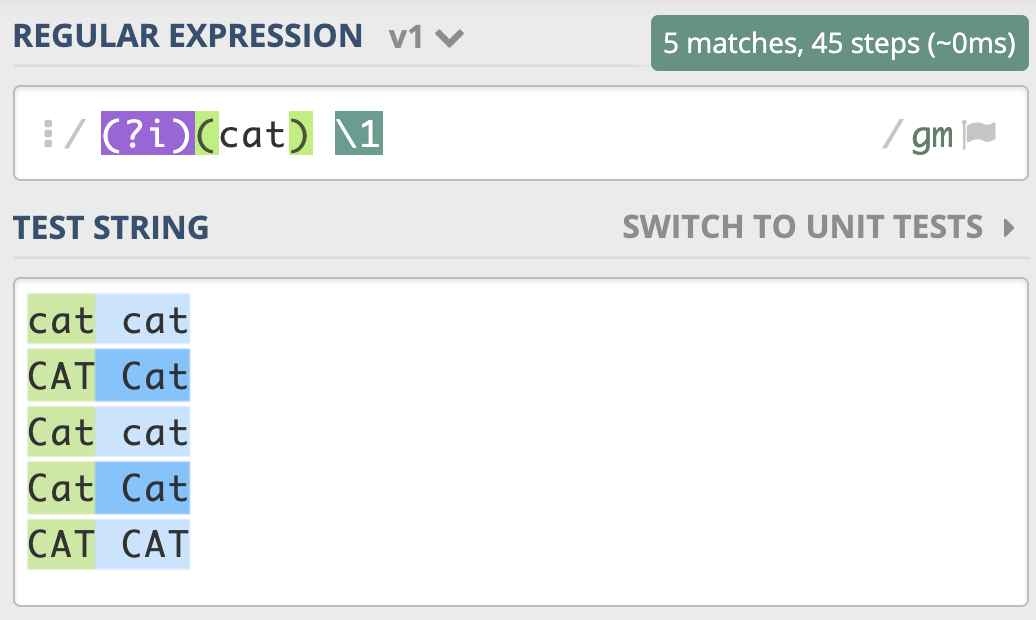
尝试匹配两个连续出现的 cat,即便是第一个 cat 和第二个 cat 大小写不一致,也可以匹配上。¶
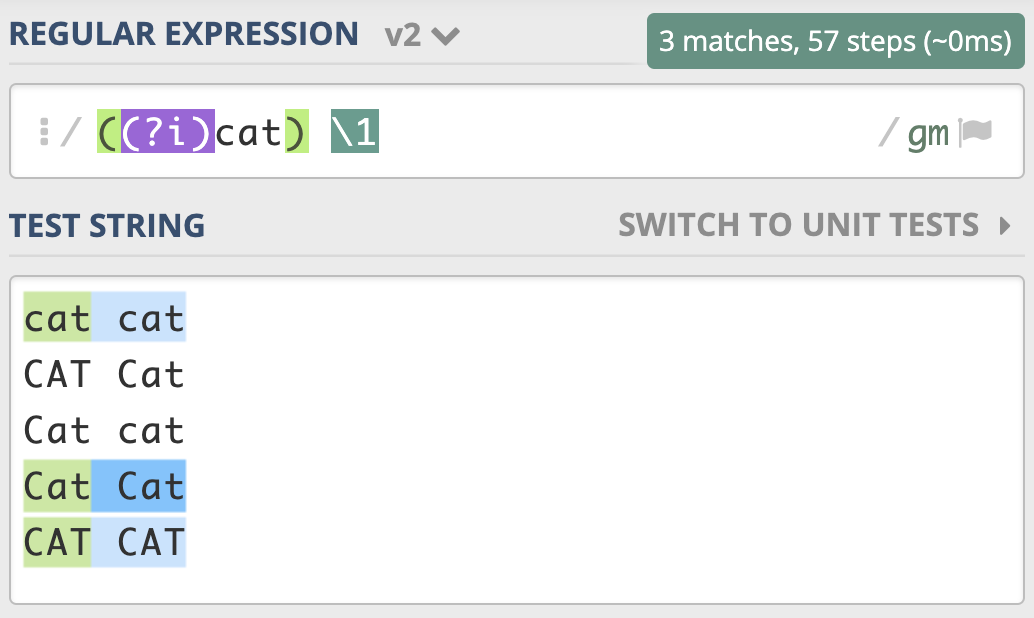
想要前面匹配上的结果,和第二次重复时的大小写一致,只需要用括号把修饰符和正则 cat 部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容。¶
2. 点号通配模式(Dot All)¶
模式修饰符:
格式: (?s)
如:
(?s).+
备注
有很多地方把它称作 单行匹配模式 ,但这么说容易造成误解,毕竟它与多行匹配模式没有联系。在单行匹配模式下,.可以匹配换行。
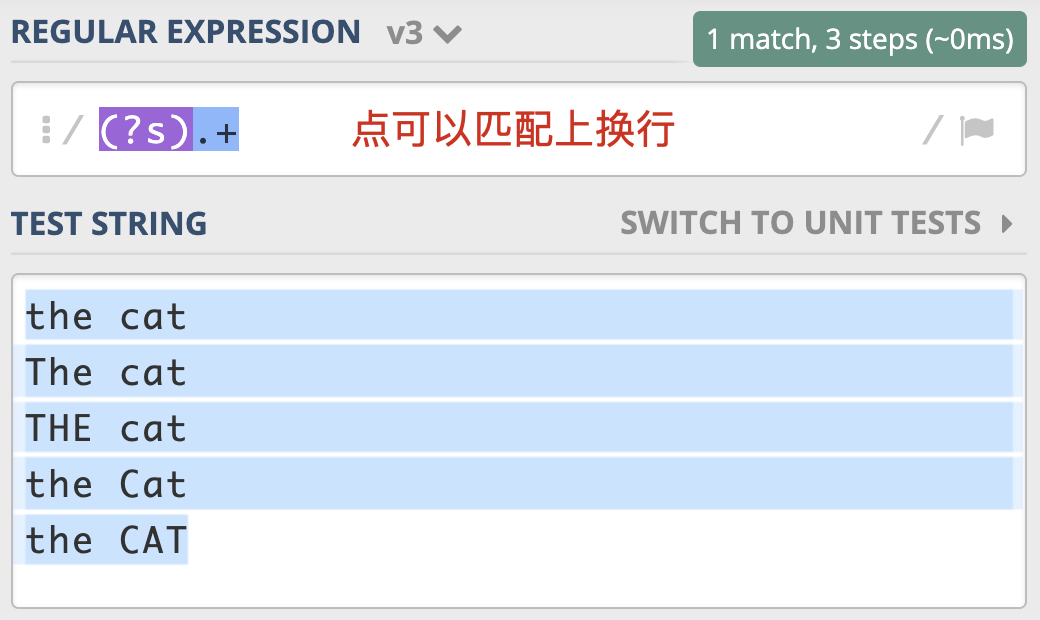
一个点号通配模式的例子¶
警告
JavaScript 不支持此模式,那么我们就可以使用前面说的 [sS] 等方式替代。在 Ruby 中则是用 Multiline,来表示点号通配模式(单行匹配模式)
3. 多行匹配模式(Multiline)¶
模式修饰符:
格式: (?m)
如:
(?m)^the|cat$
^ 匹配整个字符串的开头
$ 匹配整个字符串的结尾
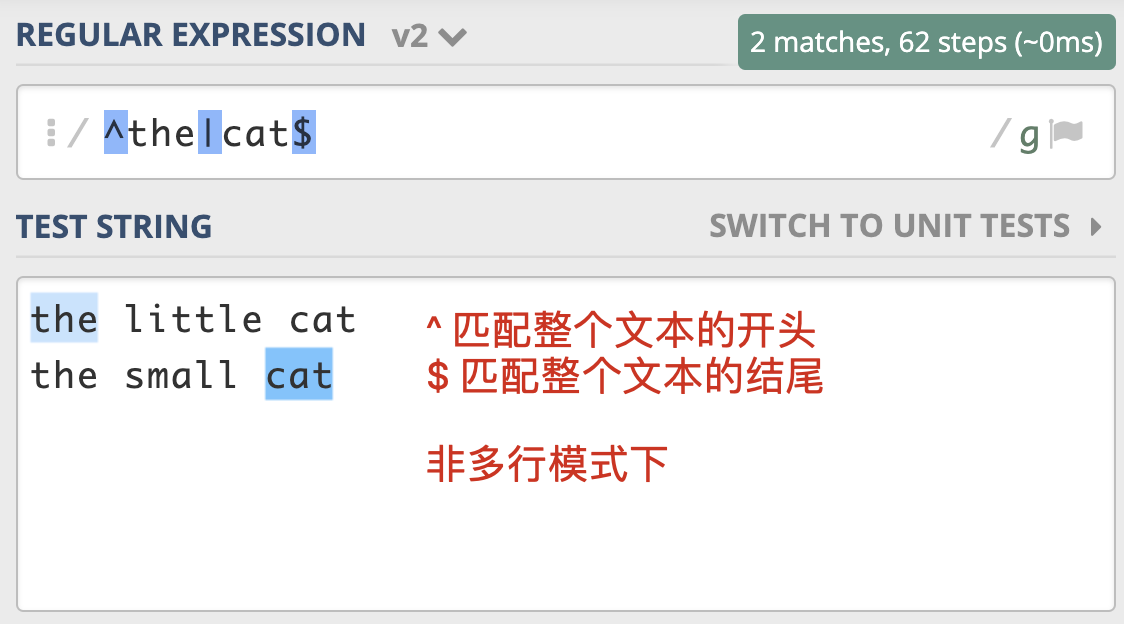
非多行模式¶
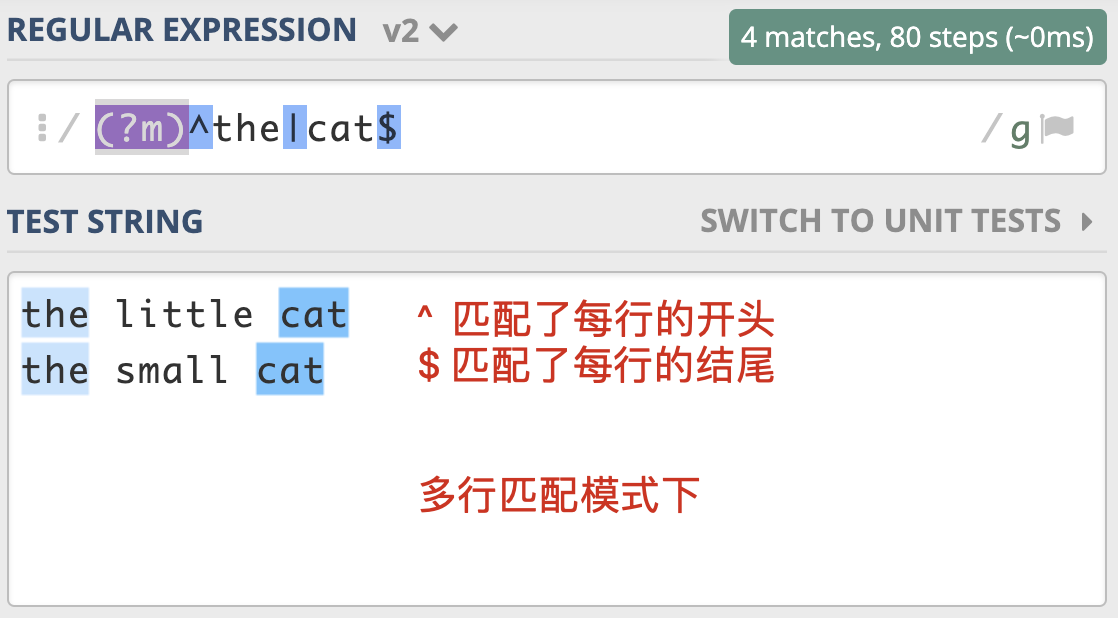
多行模式¶
4. 注释模式(Comment)¶
模式修饰符:
格式: (?#comment)
如:
(\w+)(?#word) \1(?#word repeat again)
5. x 模式¶
x 模式也可以起到注释的作用:
import re
regex = r'''(?mx) # 使用多行模式和 x 模式
^ # 开头
(\d {4}) # 年
(\d {2}) # 月
$ # 结尾
'''
re.findall(regex, '202006\n202007')
# 输出结果 [('2020', '06'), ('2020', '07')]
备注
在 x 模式下,所有的换行和空格都会被忽略。为了换行和空格的正确使用,我们可以通过把空格放入字符组中,或将空格转义来解决换行和空格的忽略问题。
6. 其他¶
a匹配模式 Python3专用格式: (?a) 说明: 指的是 ASCII 模式,可以让 \w 等只匹配 ASCII 例: >>> re.findall(r'(?a)^.$', '学') ['学']:匹配模式:格式: (?:<xxxxx>) 说明: 不创建后向引用的group 即: 不保存子组
4.1.5. 断言(Assertion)¶
备注
【定义】在有些情况下,我们对要匹配的文本的位置也有一定的要求。为了解决这个问题,正则中提供了一些结构,只用于匹配位置,而不是文本内容本身,这种结构就是断言。
断言有三种:
1. 单词边界
2. 行的开始或结束
3. 环视
1. 单词边界(Word Boundary)¶
\b匹配一个单词边界,单词定义为Unidcode的字母数字或下划线字符
\B匹配非单词边界,跟\b相反
准确匹配单词:
使用 \b\w+\b
准确匹配单词tom:
使用 \btom\b
2. 行的开始或结束¶
日志起始行判断:
判断条件: 以时间开头
那些不是以时间开头的可能就是打印的堆栈信息
输入数据校验:
re.search('^\d{6}$', "123456") # 用户录入的 6 位数字必须是行的开头或结尾
3. 环视(Look Around)/零宽断言¶
备注
环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则,有些地方也称环视为零宽断言。
环视的4种结构:
(?<=Y): 肯定逆序(postive-lookbehind)
(?<!Y): 否定逆序(negative-lookbehind)
(?=Y): 肯定顺序(postive-lookahead)
(?!Y): 否定顺序(negative-lookahead)
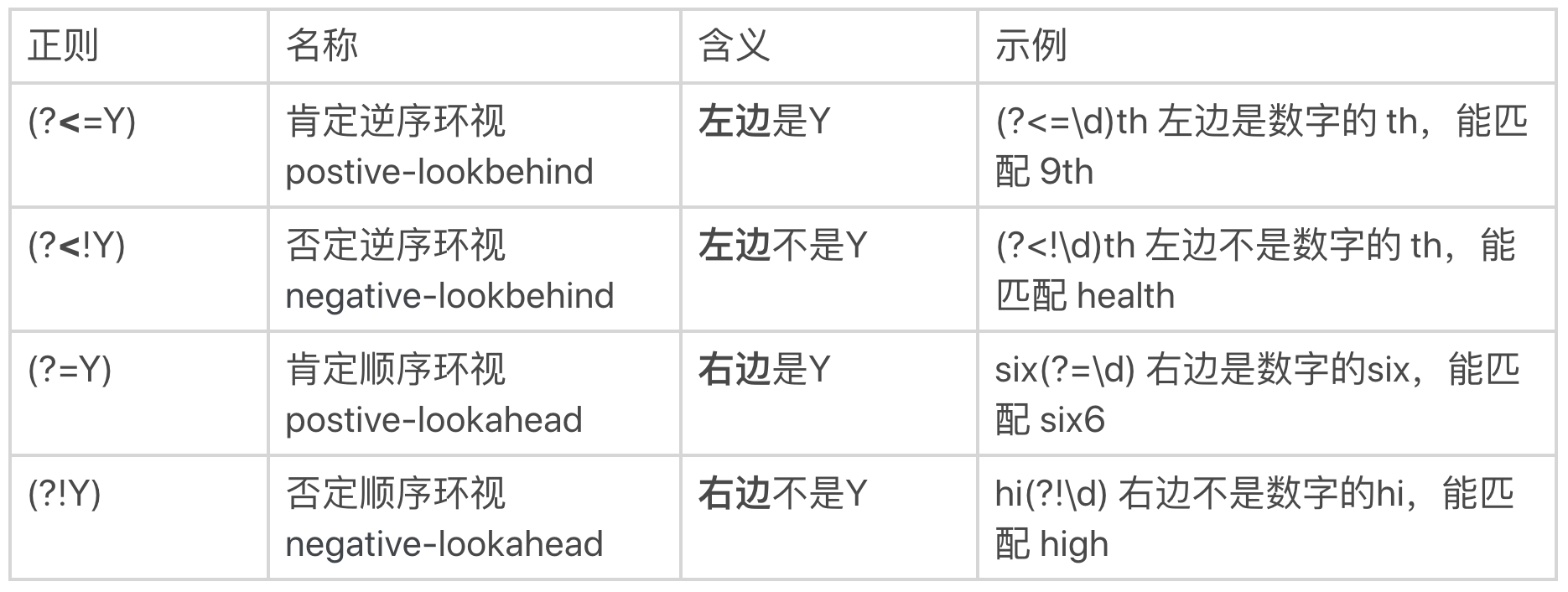
左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。¶
重要
环视中虽然也有括号,但不会保存成子组。保存成子组的一般是匹配到的文本内容,后续用于替换等操作,而环视是表示对文本左右环境的要求,即环视只匹配位置,不匹配文本内容。
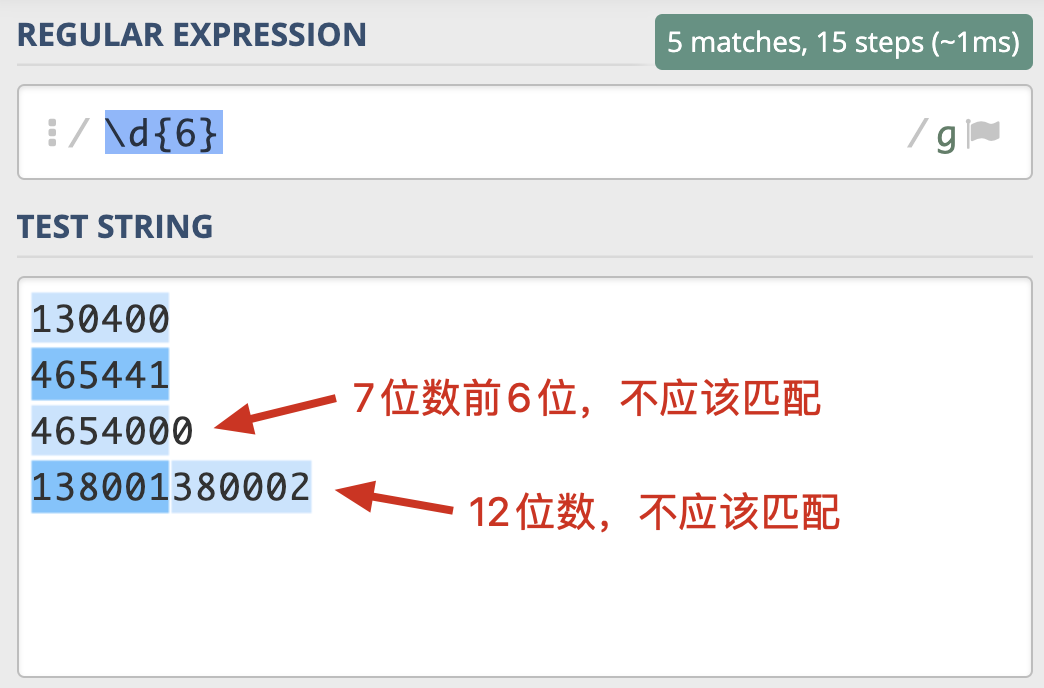
验证是否有且只有 6 位数字。¶
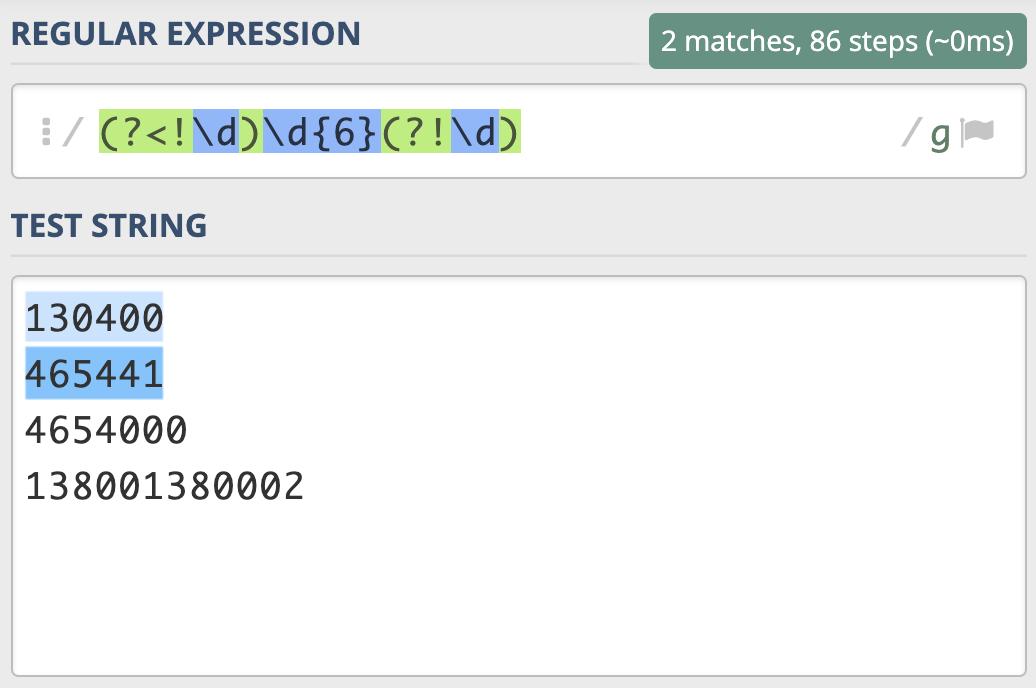
左边不是数字,右边也不是数字的 6 位数的正则。即 (?<!\d)\d{6}(?!\d)¶
零宽断言¶
元字符 “^” 和 “$” 匹配的只是位置,顺序环视 “(?=[a-z])” 只进行匹配,并不占有字符,也不将匹配的内容保存到最终的匹配结果,所以都是零宽度的。
备注
A,Z,b,^,$都是零宽断言
4.1.6. 转义Escape¶
转义字符: Escape Character
转义序列通常有两种功能:
1. 编码无法用字母表直接表示的特殊数据
2. 用于表示无法直接键盘录入的字符(如回车符)
字符串转义和正则转义¶
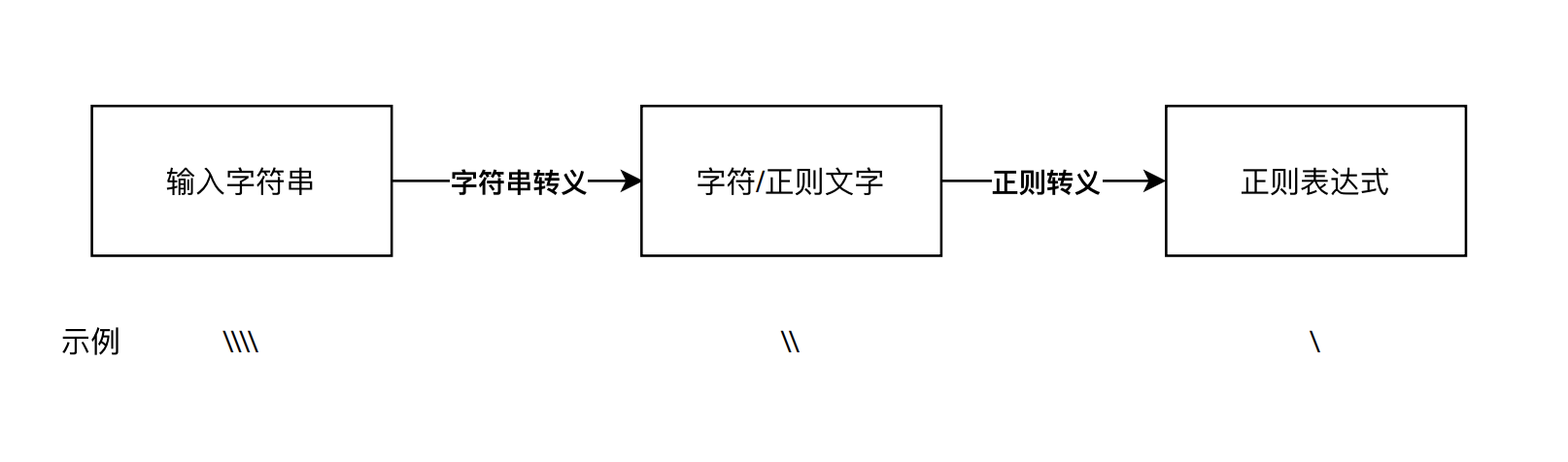
我们输入的字符串,四个反斜杠 \\\\ ,经过第一步字符串转义,它代表的含义是两个反斜杠 \\ ;这两个反斜杠再经过第二步正则转义,它就可以代表单个反斜杠 \ 了。¶
>>> re.findall('\\\\', 'a*b+c?\\d123d\\')
['\\', '\\']
=>
>>> re.findall(r'\\', 'a*b+c?\\d123d\\')
['\\', '\\']
元字符的转义¶
>>> re.findall('\+', '+')
['+']
括号的转义¶
方括号 [] 和 花括号 {} 只需转义开括号,但圆括号 () 两个都要转义:
>>> re.findall('\(\)$$
- ]{}’, ‘()[]{}’)
[‘()[]{}’]
方括号和花括号都转义也可以:
>>> re.findall('\(\)\[
- $${}’, ‘()[]{}’)
[‘()[]{}’]
备注
在正则中,圆括号通常用于分组,或者将某个部分看成一个整体,如果只转义开括号或闭括号,正则会认为少了另外一半,所以会报错。
转义函数¶
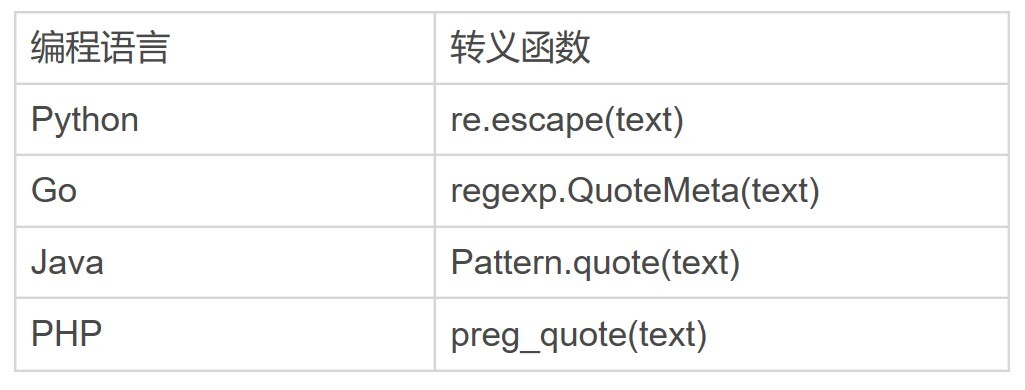
编程语言对应的转义函数¶
Python 实例:
>>> re.escape('\d') # 反斜杠和字母d转义
'\\\\d'
>>> re.findall(re.escape('\d'), '\d')
['\\d']
>>> re.escape('[+]') # 中括号和加号
'\$$
\+$$’
>>> re.findall(re.escape('[+]'), '[+]')
['[+]']
字符组中的转义¶
备注
书写正则的时候,在字符组中,如果有过多的转义会导致代码可读性差。在字符组里只有三种情况需要转义
脱字符在中括号中,且在第一个位置需要转义:
>>> re.findall(r'[^ab]', '^ab') # 转义前代表"非" ['^'] >>> re.findall(r'[\^ab]', '^ab') # 转义后代表普通字符 ['^', 'a', 'b']
中划线在中括号中,且不在首尾位置:
>>> re.findall(r'[a-c]', 'abc-') # 中划线在中间,代表"范围" ['a', 'b', 'c'] >>> re.findall(r'[a\-c]', 'abc-') # 中划线在中间,转义后的 ['a', 'c', '-'] >>> re.findall(r'[-ac]', 'abc-') # 在开头,不需要转义 ['a', 'c', '-'] >>> re.findall(r'[ac-]', 'abc-') # 在结尾,不需要转义 ['a', 'c', '-']
右括号在中括号中,且不在首位:
>>> re.findall(r'[]ab]', ']ab') # 右括号不转义,在首位 [']', 'a', 'b'] >>> re.findall(r'[a]b]', ']ab') # 右括号不转义,不在首位 [] # 匹配不上,因为含义是 a后面跟上b] >>> re.findall(r'[a\]b]', ']ab') # 转义后代表普通字符 [']', 'a', 'b']
除上面三种必须转义的情况,其它情况不转义也能正常工作:
>>> re.findall(r'[.*+?()]', '[.*+?()]') # 单个长度的元字符
['.', '*', '+', '?', '(', ')']
>>> re.findall(r'[\d]', 'd12\\') # \w,\d等在中括号中还是元字符的功能
['1', '2'] # 匹配上了数字,而不是反斜杠\和字母d
实例:
>>> re.findall('\n', '\\n\n\\')
['\n'] # 找到了换行符
>>> re.findall('\\n', '\\n\n\\')
['\n'] # 找到了换行符
>>> re.findall('\\\n', '\\n\n\\')
['\n'] # 找到了换行符
>>> re.findall('\\\\n', '\\n\n\\')
['\\n'] # 找到了反斜杠和字母n
``'\\n\n\\'`` 共包含四个字符:
第一个字符是 \,第二个是字母n,第三个是换行符,第四个是 \
说明:
Actually regex string specified by string literal is processed by two compilers:
1. programming language compiler
2. regexp compiler
Original Compiled Regex compiled
"\n" NL NL
"\\n" '\'+'n' NL
"\\\n" '\'+NL NL
"\\\\n" '\'+'\'+'n' '\'+'n'
from: https://stackoverflow.com/questions/6967204/how-is-n-and-n-interpreted-by-the-expanded-regular-expression/59192811#59192811
关键: 包含“字符串转义”和“正则转义”两个步骤
4.1.7. 常见的流派及其特性¶
正则表达式主要有两大流派(Flavor):
1. POSIX 流派
2. PCRE 流派
1. POSIX 流派¶
POSIX 规范定义了正则表达式的两种标准:
1. BRE 标准(Basic Regular Expression 基本正则表达式)
如:
vi/vim
grep、sed使用 -B 选项(默认选项)
2. ERE 标准(Extended Regular Expression 扩展正则表达式)
如:
egrep、awk
grep、sed使用 -E 选项
实例:
使用 POSIX ERE 标准
$ grep -E '[[:digit:]]+' access.log
使用 PCRE 标准
$ grep -P '\d+' access.log
POSIX 字符组:
[:alnum:] 0-9 A-Z a-z 同w
[:alpha:] A-Z a-z
[:blank:] 空格和tab
[:cntrl:] 代表控制按键,入CR LF tab del等
[:digit:] 0-9
[:graph:] 空格和tab之外
[:lower:] a-z
[:upper:] A-Z
[:space:] 任何会产生空白的字符 空格 tab CR
重要的记住[:alnum:] [:alpha:] [:upper:] [:lower:] [:digit:]即可
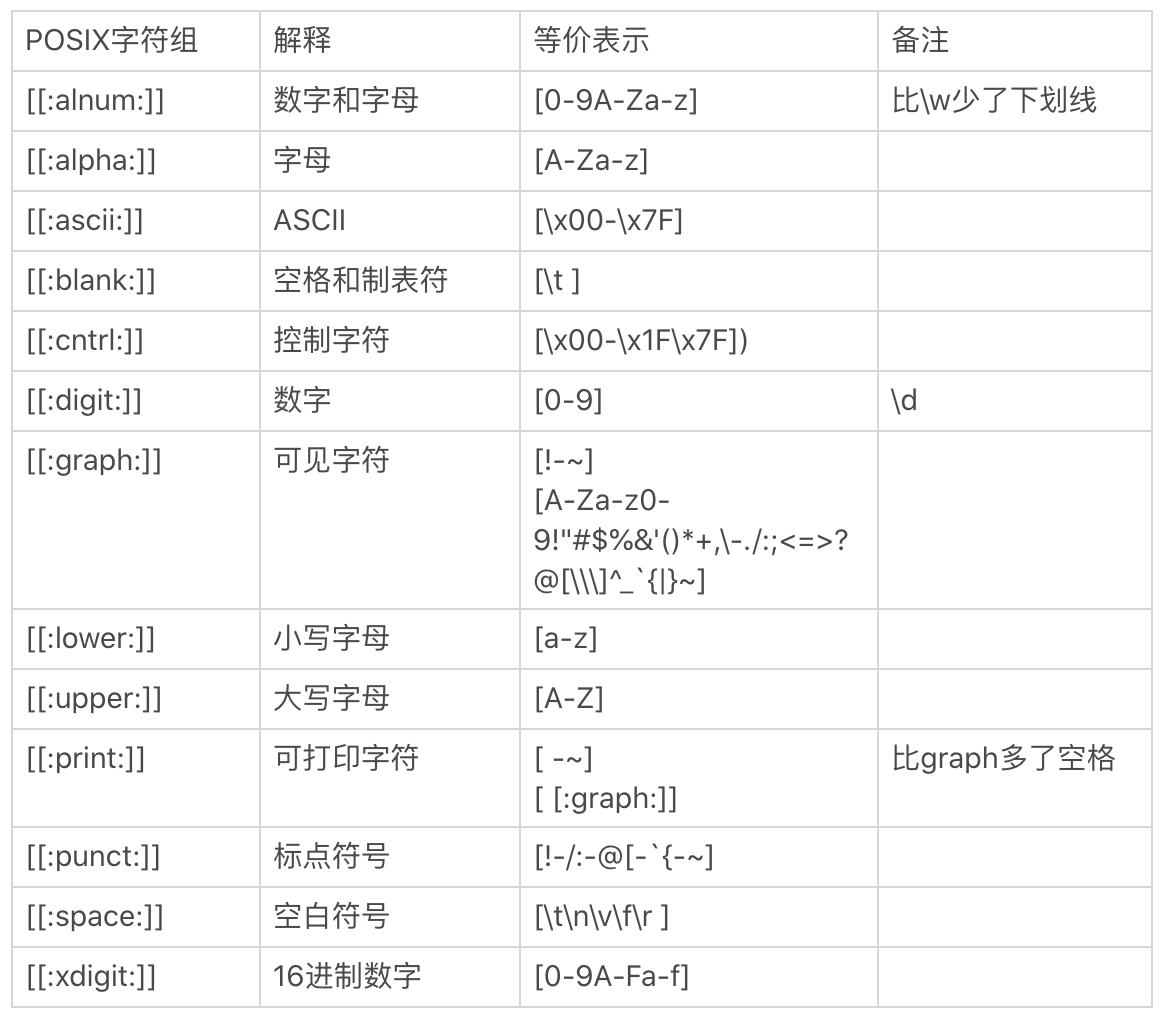
POSIX 字符组: 与 PCRE 流派使用的区别¶
2. PCRE 流派¶
备注
目前大部分常用编程语言都是源于 PCRE 标准,这个流派显著特征是有 \d、\w、\s 这类字符组简记方式。
虽然 PCRE 流派是与 Perl 正则表达式相兼容的流派,但这种兼容在各种语言和工具中还存在程度上的差别,这包括了直接兼容与间接兼容两种情况:
1. 直接兼容
PCRE 流派中与 Perl 正则表达式直接兼容的语言或工具。
比如 Perl、PHP preg、PCRE 库等,一般称之为 Perl 系。
2. 间接兼容
比如:
Java 系(包括 Java、Groovy、Scala 等)
Python 系(包括 Python2 和 Python3)
JavaScript 系(包括原生 JavaScript 和扩展库 XRegExp)
.Net 系(包括 C#、VB.Net 等)
备注
【兼容问题】即便是直接兼容,也并非完全兼容,还是存在部分不兼容的情况,原因也很简单,Perl 语言中的正则表达式在不断改进和升级之中,其他语言和工具不可能完全做到实时跟进与更新。
区别¶
备注
【区别1】 早期 BRE 与 ERE 标准的区别主要在于,BRE 标准不支持量词问号和加号,也不支持多选分支结构管道符。BRE 标准在使用花括号,圆括号时要转义才能表示特殊含义。
现在 GNU 在实现 POSIX 标准时,做了一定的扩展,主要有以下三点扩展:
1. GNU BRE 支持了 +、?,但转义了才表示特殊含义,即需要用 \+、\? 表示
2. GNU BRE 支持管道符多选分支结构,同样需要转义,即用 \| 表示
3. GNU ERE 也支持使用反引用,和 BRE 一样,使用 \1、\2…\9 表示
备注
【区别2】 现在 GNU BRE 和 GNU ERE 它们的功能特性并没有太大区别,区别是在于部分语法层面上,主要是一些字符要不要转义。
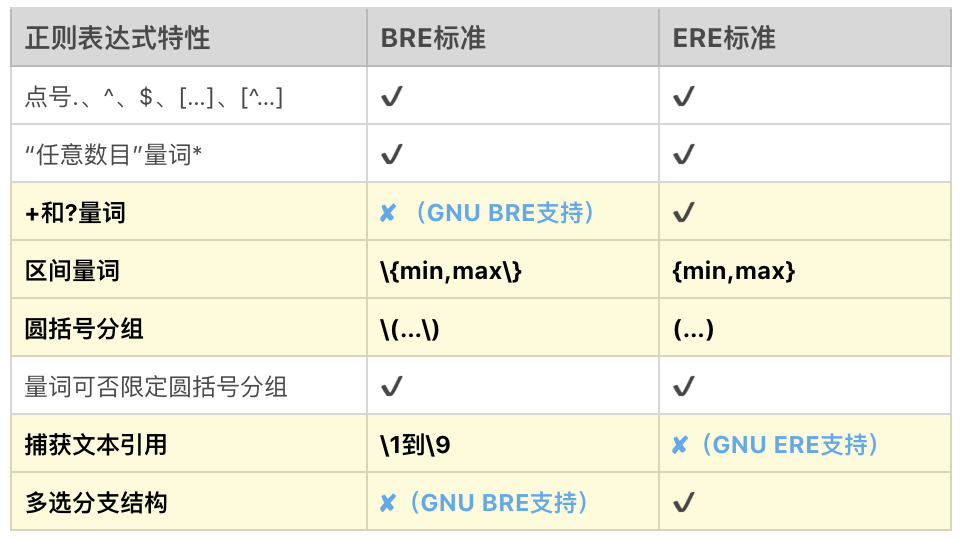
BRE 标准和 ERE 标准的详细区别: 浅黄色背景是 BRE 和 ERE 不同的地方,三处天蓝色字体是 GNU 扩展。¶
备注
【区别3】ERE 和 PCRE 主要区别在于字符组,PCRE 功能更丰富些,比如支持了 环视。
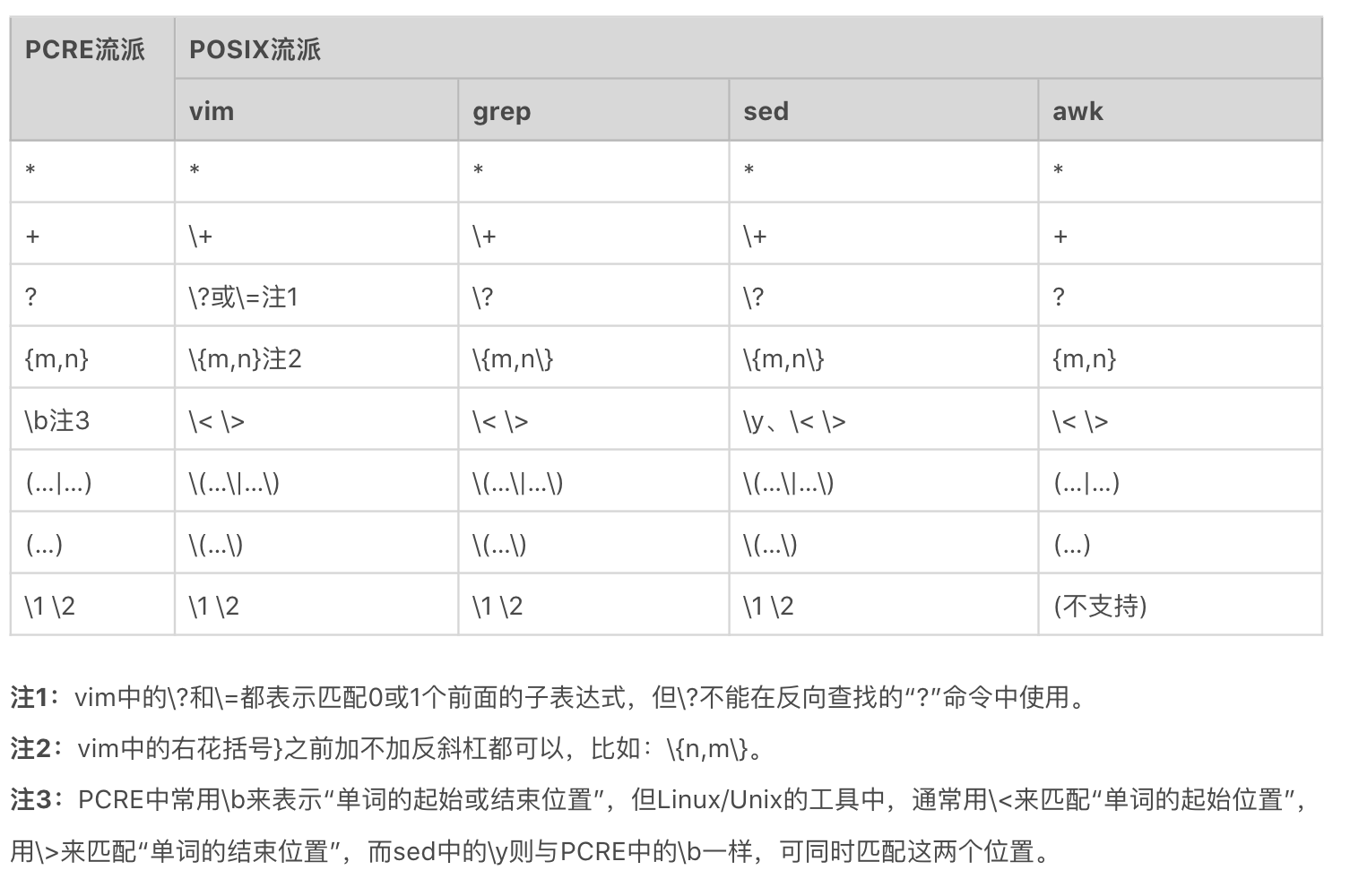
UNIX/LINUX 系统里 PCRE 流派与 POSIX 流派的对比¶
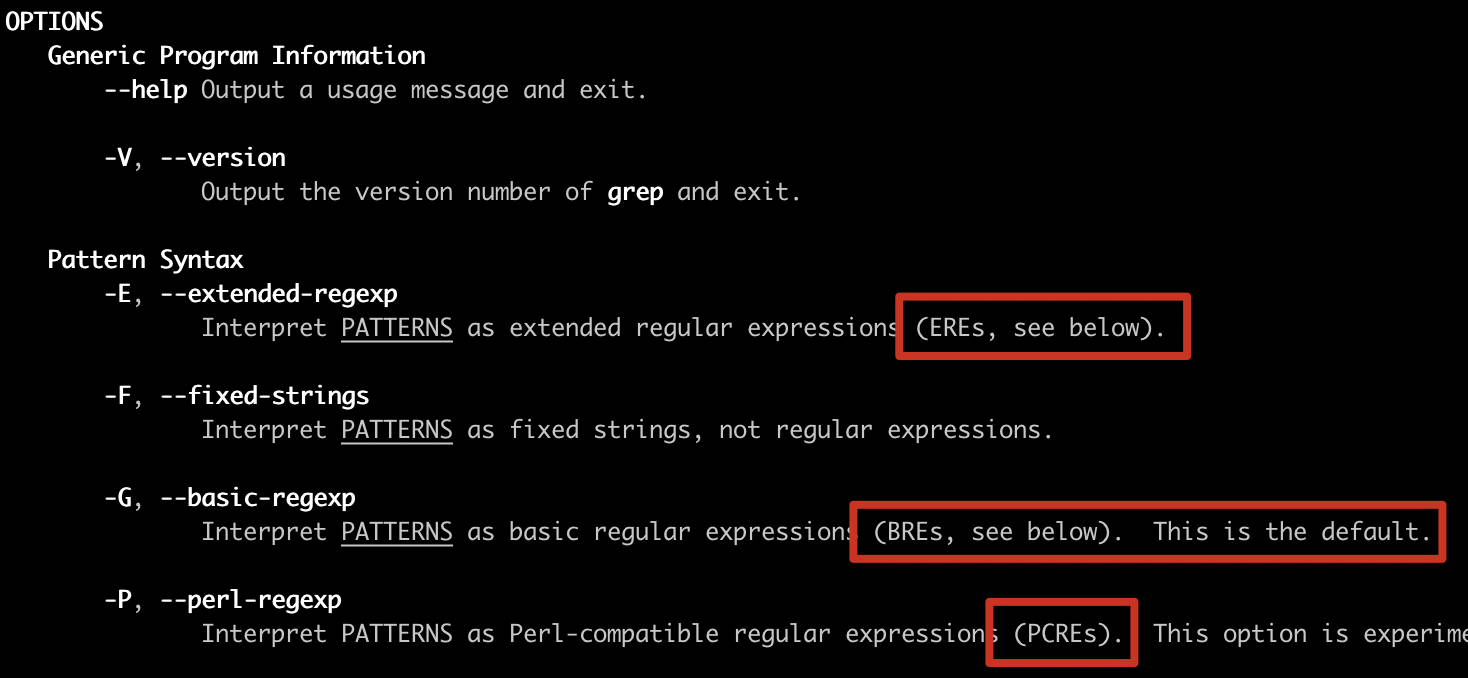
-G 是指定使用 BRE 标准(默认),-E 是 ERE 标准,-P 是 PCRE 标准¶
[实例]使用不同的标准(即 BRE、ERE、PCRE ),来查找含有 ftp、http 或 https 的行:
内容:
https://time.geekbang.org
ftp://ftp.ncbi.nlm.nih.gov
www.baidu.com
www.ncbi.nlm.nih.gov
命令:
## BRE
$ grep '$f\|ht$tps\?.*' a.txt
## ERE
$ grep -E '(f|ht)tps?.*' a.txt
## PCRE
$ grep -P '(f|ht)tps?.*' a.txt
参考¶
详细的 Regex cheatsheet: https://remram44.github.io/regex-cheatsheet/regex.html
GNU sed 不支持 PCRE,没有 - P 选项,可以考虑使用 perl 命令代替: https://askubuntu.com/questions/1050693/sed-with-pcre-like-grep-p
4.1.8. Unicode¶
参见 Unicode 编码
Unicode 属性¶
正则中常用的三种 Unicode 字符集:
1. 按功能划分的 Unicode Categories(有的也叫 Unicode Property),比如标点符号,数字符号
2. 按连续区间划分的 Unicode Blocks,比如只是中日韩字符
3. 按书写系统划分的 Unicode Scripts,比如汉语中文字符

正则中常用的三种 Unicode 字符集¶
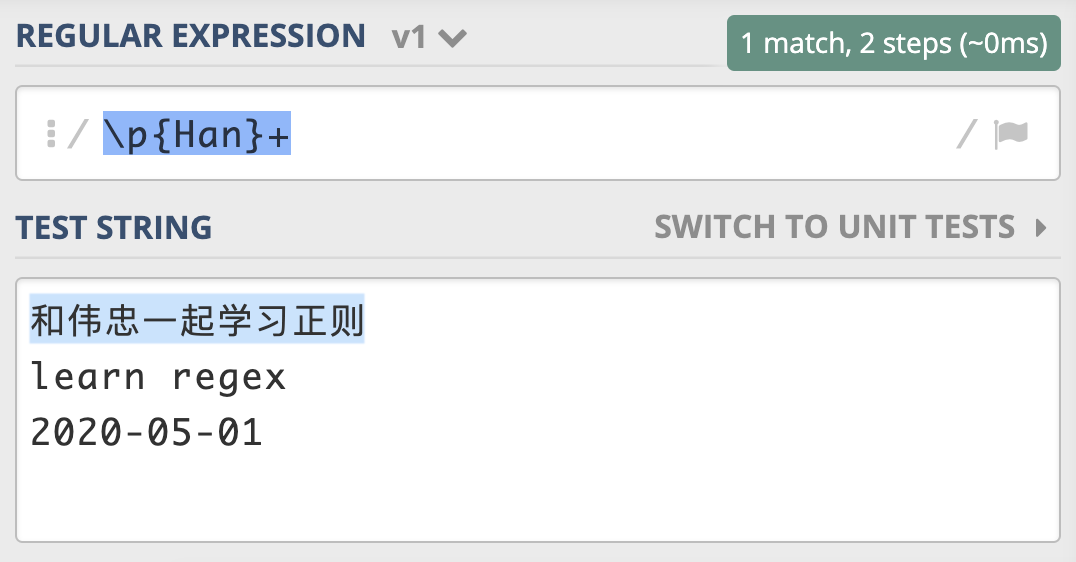
在正则中,这三种属性在正则中的表示方式都是 p {属性}。比如,我们可以使用 Unicode Script 来实现查找连续出现的中文。其中,Unicode Blocks 在不同的语言中记法有差异,比如 Java 需要加上 In 前缀,类似于 p {InBopomofo} 表示注音字符。¶
参考:
* Unicode Property
* Unicode Block
* Unicode Script
表情符号¶
表情符号有如下特点:
1. 许多表情不在 BMP 内,码值超过了 FFFF
使用 UTF-8 编码时:
普通的 ASCII 是 1 个字节
中文是 3 个字节
有一些表情需要 4 个字节来编码
2. 这些表情分散在 BMP 和各个补充平面中
要想用一个正则来表示所有的表情符号非常麻烦,即便使用编程语言处理也同样很麻烦
3. 一些表情现在支持使用颜色修饰(Fitzpatrick modifiers),可以在 5 种色调之间进行选择
这样一个表情其实就是 8 个字节了
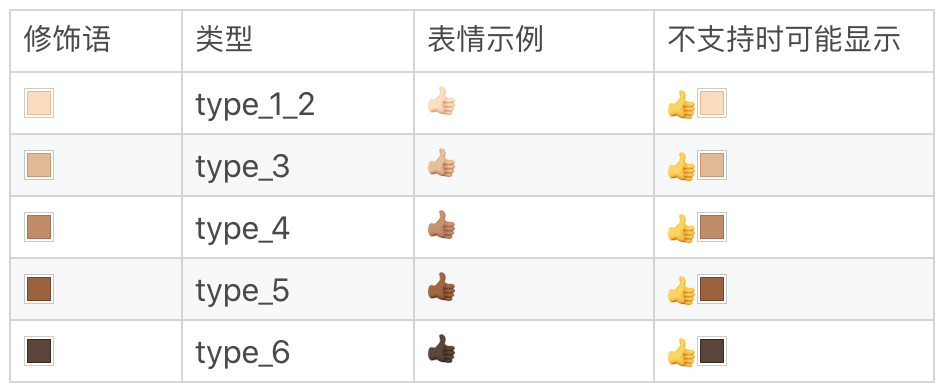
关于表情颜色修饰的 5 种色调¶
在 ipython3 上测试表情颜色修饰的 emoji
➜ ipython3
In [1]: '✅'.encode('utf8')
Out[1]: b'\xe2\x9c\x85'
In [2]: '☑️'.encode('utf8')
Out[2]: b'\xe2\x98\x91\xef\xb8\x8f'
In [4]: '👍︎️'.encode('utf8')
Out[4]: b'\xf0\x9f\x91\x8d\xef\xb8\x8e\xef\xb8\x8f'
In [13]: '👍🏻︎️'.encode('utf8') # 注: 这儿不支持这个颜色的修饰
Out[13]: b'\xf0\x9f\x91\x8d\xf0\x9f\x8f\xbb\xef\xb8\x8e\xef\xb8\x8f'
警告
而在处理表情时,由于表情比较复杂,我不建议使用正则来处理,更建议使用专用的表情库来处理。
4.1.9. 匹配原理以及优化原则¶
有穷自动机的具体实现称为正则引擎,包括:
1. DFA
2. 传统的 NFA
3. POSIX NFA
4.1.10. NFA 工作机制¶
NFA 引擎的工作方式是:
先看正则,再看文本,而且以正则为主导
示例演示1¶
示例:
字符串:we study on jikeshijian app
正则:jike (zhushou|shijian|shixi)
正则中的第一个字符是 j,NFA 引擎在字符串中查找 j,接着匹配其后是否为 i ,如果是 i 则继续,这样一直找到 jike:
regex: jike(zhushou|shijian|shixi) ^ text: we study on jikeshijian app ^
再根据正则看文本后面是不是 z,发现不是,此时 zhushou 分支淘汰:
regex: jike(zhushou|shijian|shixi) ^ 淘汰此分支 (zhushou) text: we study on jikeshijian app ^
看其它的分支,看文本部分是不是 s,直到 shijian 整个匹配上:
说明: shijian 在匹配过程中如果不失败,就不会看后面的 shixi 分支。 当匹配上了 shijian 后,整个文本匹配完毕,也不会再看 shixi 分支
示例演示2¶
示例-文本改一下,把 jikeshijian 变成 jikeshixi:
字符串:we study on jikeshixi app
正则:jike (zhushou|shijian|shixi)
正则 shijian 的 j 匹配不上时 shixi 的 x,会接着使用正则 shixi 来进行匹配,重新从 s 开始(NFA 引擎会记住这里):
第二个分支匹配失败 regex: jike(zhushou|shijian|shixi) ^ 淘汰此分支 (正则 j 匹配不上文本 x) text: we study on jikeshixi app ^ 再次尝试第三个分支 regex: jike(zhushou|shijian|shixi) ^ text: we study on jikeshixi app ^
总结¶
备注
NFA 是以正则为主导,反复测试字符串,这样字符串中同一部分,有可能被反复测试很多次。
4.1.11. DFA 工作机制¶
NFA 引擎的工作方式是:
先看文本,再看正则表达式,是以文本为主导的
示例演示¶
从 we 中的 w 开始依次查找 j,定位到 j ,这个字符后面是 i。所以我们接着看正则部分是否有 i ,如果正则后面是个 i ,那就以同样的方式,匹配到后面的 ke:
text: we study on jikeshijian app ^ regex: jike(zhushou|shijian|shixi) ^
文本 e 后面是字符 s ,DFA 接着看正则表达式部分,此时 zhushou 分支被淘汰,开头是 s 的分支 shijian 和 shixi 符合要求:
text: we study on jikeshijian app ^ regex: jike(zhushou|shijian|shixi) ^ ^ ^ 淘汰 符合 符合
依次检查字符串,检测到 shijian 中的 j 时,只有 shijian 分支符合,淘汰 shixi,接着看分别文本后面的 ian,和正则比较,匹配成功:
text: we study on jikeshijian app ^ regex: jike(zhushou|shijian|shixi) ^ ^ 符合 淘汰
总结¶
备注
DFA 和 NFA 两种引擎的工作方式完全不同。NFA 是以表达式为主导的,先看正则表达式,再看文本。而 DFA 则是以文本为主导,先看文本,再看正则表达式。
备注
一般来说,DFA 引擎会更快一些,因为整个匹配过程中,字符串只看一遍,不会发生回溯,相同的字符不会被测试两次。也就是说 DFA 引擎执行的时间一般是线性的。DFA 引擎可以确保匹配到可能的最长字符串。但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,它也不支持捕获子组。
备注
NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。因此,在最坏情况下,它的执行速度可能非常慢。
4.1.12. POSIX NFA工作机制¶
POSIX NFA 与 传统 NFA 区别:
传统的 NFA 引擎 “急于” 报告匹配结果,找到第一个匹配上的就返回了,
所以可能会导致还有更长的匹配未被发现
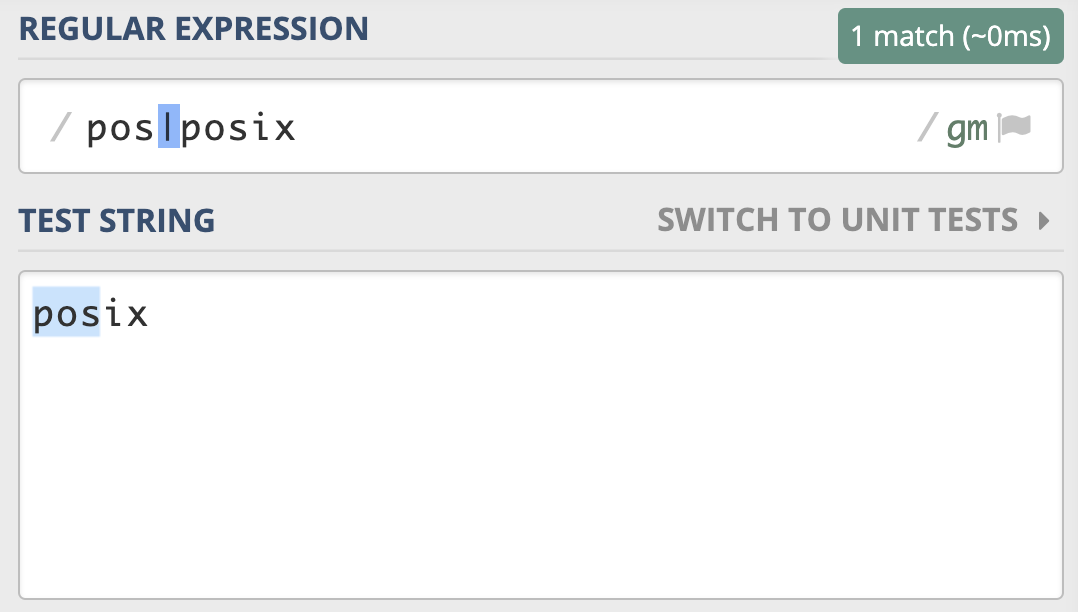
使用正则 pos|posix 在文本 posix 中进行匹配,传统的 NFA 从文本中找到的是 pos,而不是 posix,而 POSIX NFA 找到的是 posix。¶
备注
POSIX NFA 的应用很少,主要是 Unix/Linux 中的某些工具。POSIX NFA 引擎与传统的 NFA 引擎类似,但不同之处在于,POSIX NFA 在找到可能的最长匹配之前会继续回溯,也就是说它会尽可能找最长的,如果分支一样长,以最左边的为准(“The Longest-Leftmost”)。因此,POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
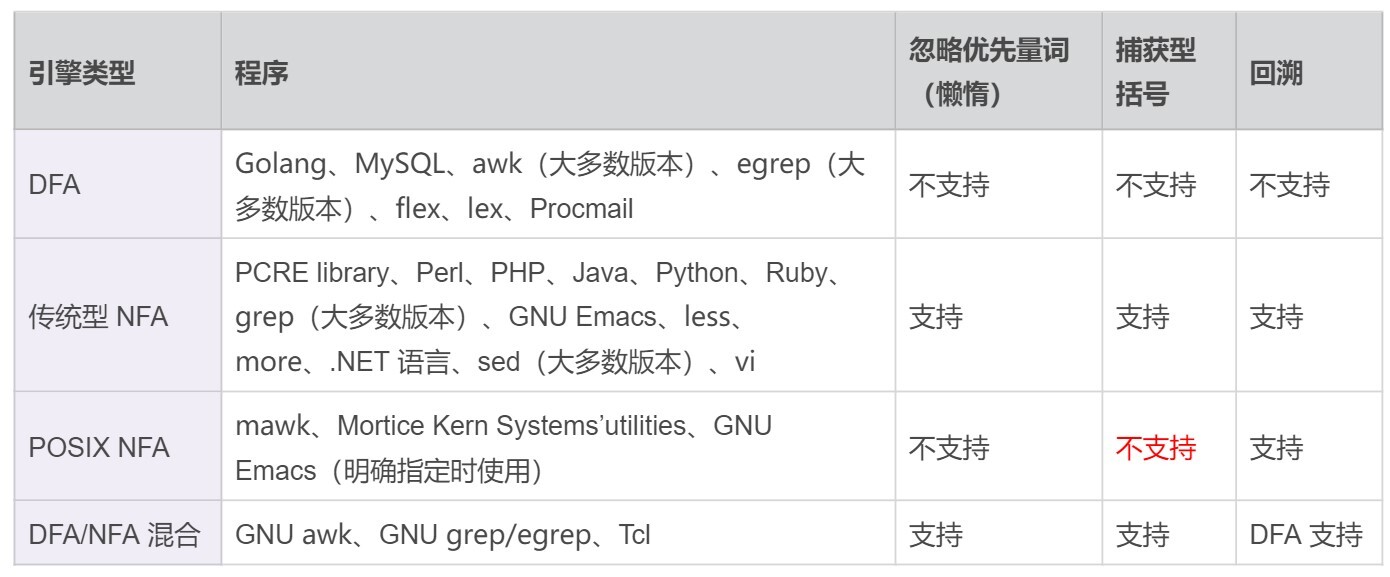
DFA、传统 NFA 以及 POSIX NFA 引擎的特点总结¶
4.1.13. 回溯¶
备注
回溯是 NFA 引擎才有的,并且只有在正则中出现量词或多选分支结构时,才可能会发生回溯。
示例1-简单回溯¶
用正则 a+ab 来匹配 文本 aab:
1. a+ 是贪婪匹配,会占用掉文本中的两个 a
2. 但正则接着又是 a,文本部分只剩下 b,只能通过回溯,让 a+ 吐出一个 a,再次尝试
示例2-.* 导致大量回溯¶
使用 .*ab 去匹配一个比较长的字符串:
.* 会吃掉整个字符串(不考虑换行,假设文本中没有换行)
然后,你会发现正则中还有 ab 没匹配到内容,只能将 .* 匹配上的字符串吐出一个字符,再尝试
还不行,再吐出一个,不断尝试

示例2演示¶
备注
要尽量不用 .* ,除非真的有必要,因为点能匹配的范围太广了,我们要尽可能精确。常见的解决方式有两种,比如要提取引号中的内容时,使用 “[^”]+”,或者使用非贪婪的方式 “.+?”,来减少 “匹配上的内容不断吐出,再次尝试” 的过程。
示例3-店名匹配¶
店名可以出现下面这些组合:
1. 英文字母大小写
2. 数字
3. 越南文
4. 一些特殊字符,如 “&”,“-”,“_” 等
正则表达:
^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
测试字符:
this is a cat, cat
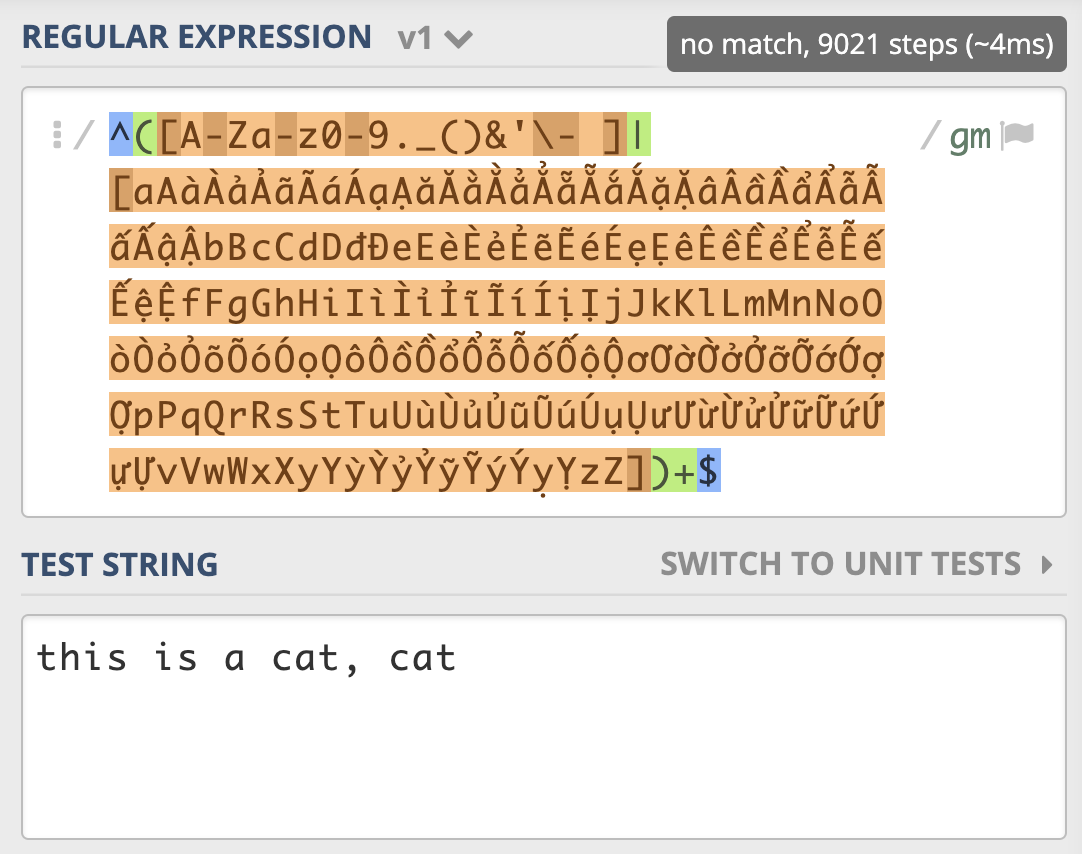
一个很短的字符串,NFA 引擎尝试步骤达到了 9021 次,由于是贪婪匹配,第一个分支能匹配上 this is a cat 部分,接着后面的逗号匹配失败,使用第二个分支匹配,再次失败,此时贪婪匹配部分结束。NFA 引擎接着用正则后面的 $ 来进行匹配,但此处不是文本结尾,匹配不上,发生回溯,吐出第一个分支匹配上的 t,使用第二个分支匹配 t 再试,还是匹配不上。继续回溯,第二个分支匹配上的 t 吐出,第一个分支匹配上的 a 也吐出,再用第二个分支匹配 a 再试,如此发生了大量的回溯。¶
示例3-店名匹配(优化版)¶
第一个分支中的 A-Za-z 去掉,因为后面多选分支结构中重复了:
^([0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
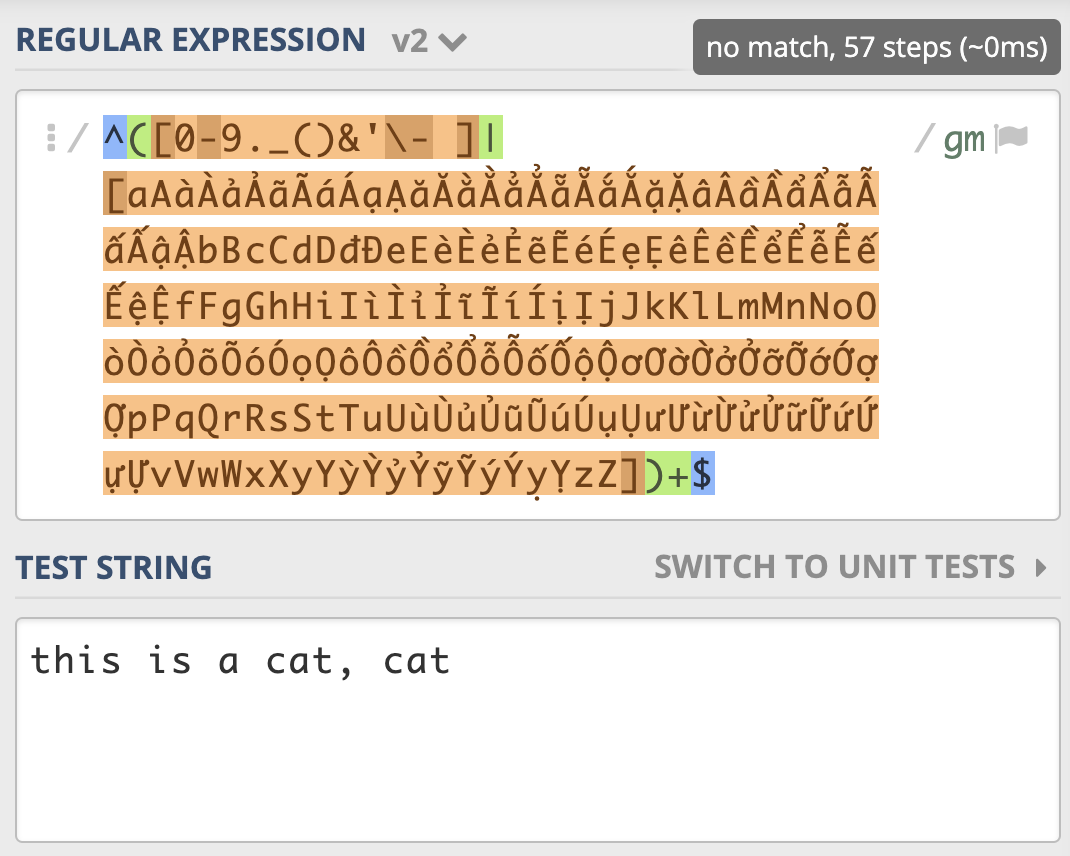
这样优化后只尝试匹配了 57 次就结束了¶
警告
【结论】一定要记住,不要在多选择分支中,出现重复的元素。即:“回溯不可怕,我们要尽量减少回溯后的判断”
示例3-店名匹配(独占模式优化版)¶
说明:
独占模式可以理解为贪婪模式的一种优化,
它也会发生广义的回溯,但它不会吐出已经匹配上的字符。
独占模式匹配到英文逗号那儿,不会吐出已经匹配上的字符,匹配就失败了,所以采用独占模式也能解决性能问题¶
警告
独占模式 “不吐出已匹配字符” 的特性,会使得一些场景不能使用它。另外,只有少数编程语言支持独占模式。
示例3-店名匹配(其他优化版)¶
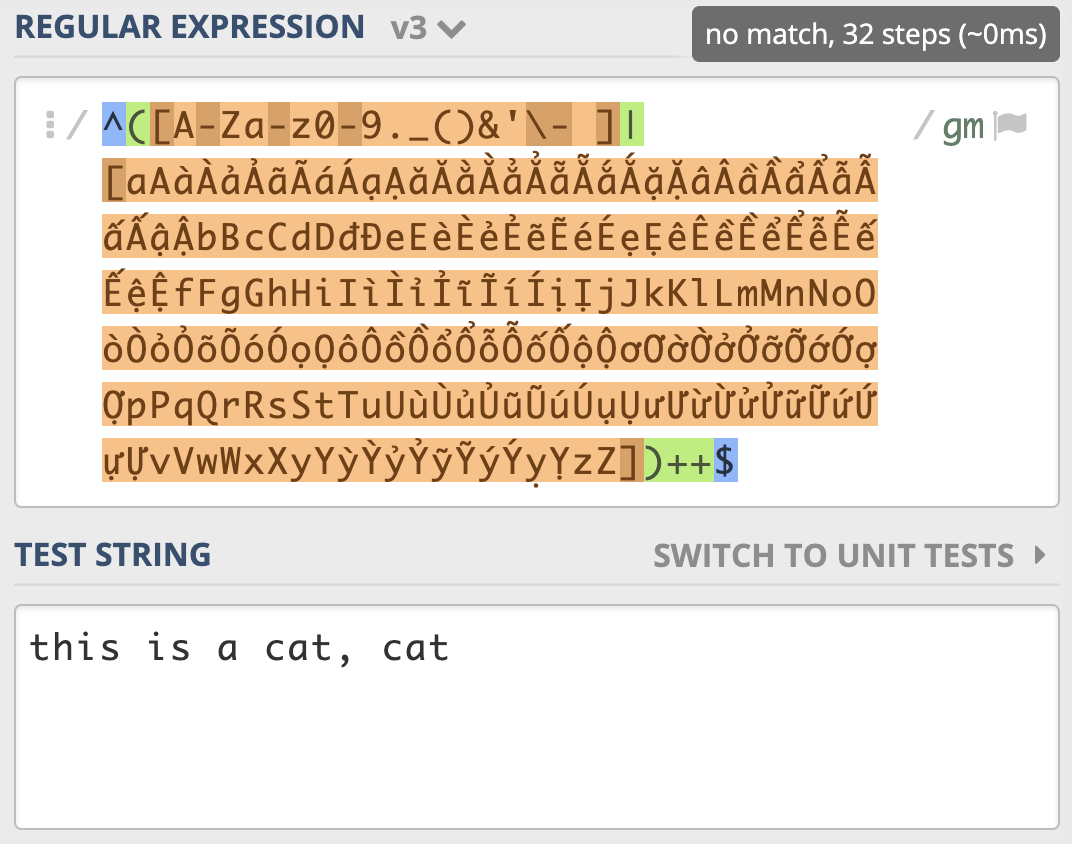
移除多选分支选择结构,直接用中括号表示多选一¶
4.1.14. 正则调试¶
regex101.com的Regex Debugger¶

4.1.15. 正则优化¶
1. 测试性能的方法¶
用 ipython 来测试正则的性能:
In [1]: import re In [2]: x = '-' * 1000000 + 'abc' In [3]: timeit re.search('abc', x) 480 µs ± 8.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)regex101.com 查看正则和文本匹配的次数
2. 提前编译好正则¶
备注
使用这个方法提前将正则处理好,这样不用在每次使用的时候去反复构造自动机,从而可以提高正则匹配的性能。
3. 尽量准确表示匹配范围¶
要匹配引号里面的内容,除了写成 “.+?” 之外,我们可以写成 “[^”]+”。使用 [^”] 要比使用点号好很多,虽然使用的是贪婪模式,但它不会出现点号将引号匹配上,再吐出的问题。
4. 提取出公共部分¶
因为 NFA 以正则为主导,会导致字符串中的某些部分重复匹配多次,影响效率:
(abcd|abxy) 这样的表达式,可以优化成 ab(cd|xy)
th(?:is|at) 要比 this|that 要快
^th(is|at) is 要比 (^this|^that) is 好
备注
但从可读性上看,后者要好一些,这个就需要用的时候去权衡,也可以添加代码注释让代码更容易理解。
5. 出现可能性大的放左边¶
正则是从左到右看的,把出现概率大的放左边:
\.(?:com|net)\b 要比 \.(?:net|com)\b 好
6. 只在必要时才使用子组¶
在正则中,括号可以用于归组,但如果某部分后续不会再用到,就不需要保存成子组。如果保存成子组,正则引擎必须做一些额外工作来保存匹配到的内容,因为后面可能会用到,这会降低正则的匹配性能。
7. 警惕嵌套的子组重复¶
如果一个组里面包含重复,接着这个组整体也可以重复,比如 (.*)* 这个正则,匹配的次数会呈指数级增长,所以尽量不要写这样的正则。
8. 避免不同分支重复匹配¶
在多选分支选择中,要避免不同分支出现相同范围的情况
4.1.16. 语系对正则表达式的影响¶
在linux下执行正则表达式,要考虑语系环境所带来的影响,LANG=C和LANG=zh_CN.gb2312时,[a-z]所选取的范围是不同的:
LANG=C,使用ascii编码,a-z表示的就是a-z,字母排列方式是A,B,C,D……Z 然后a,b,c,d……z
LANG=zh_CN.gb2312,使用的是gb2312语系,排列方式为: a,A,b,B,c,C……z,Z
4.1.17. 参考¶
[工具]正则测试: https://regex101.com/r/PnzZ4k/1
[工具]Regexper: https://regexper.com/
https://regex101.com/ (老师用的)
Windows 上推荐:RegexBuddy
Mac 上推荐:Expressions
Python - Regular Expressions: http://www.tutorialspoint.com/python/python_reg_expressions.htm
正则基础之 ——NFA 引擎匹配原理: https://blog.csdn.net/lxcnn/article/details/4304651