1.1.5. base编码¶
Base100¶
Base100 编码 / 解码工具(又名:Emoji 表情符号编码 / 解码),可将文本内容编码为 Emoji 表情符号;同时也可以将编码后的 Emoji 表情符号内容解码为文本。
Base91¶
顾名思义,Base91 需要 91 个字符来表示 ASCII 编码的二进制数据。
Base91 编码是从 94 个可打印 ASCII 字符(0x21-0x7E)中,以下三个字符被省略以构建 Base91 编码表:
-(破折号,0x2D) \(反斜杠,0x5C) '(撇号,0x27)
Base91 是将二进制数据编码为 ASCII 字符的高级方法。 它类似于 UUencode 或 base64,但效率更高。 Base91 产生的开销取决于输入数据。 它的数量最多为 23%(而 base64 为 33%),范围可以降低到 14%,通常发生在 0 字节块上。
这使得 Base91 对于通过二进制不安全连接(例如电子邮件或终端线)传输较大的文件非常有用。
base85¶
Base85 是一种类似于 Base64 的二进制文本编码形式,通过使用五个 ASCII 字符来表示四个字节的二进制数据。例如,它用于将图像嵌入到 Adobe PDF 文件中。
Base85 也称为 Ascii85,是 Paul E. Rutter 为 btoa 实用程序开发的一种二进制文本编码形式。通过使用五个 ASCII 字符来表示四个字节的二进制数据(使编码量 1 / 4 比原来大,假设每 ASCII 字符 8 个比特),它比 UUENCODE 或 Base64 更有效[使用四个字符来表示三个字节的数据(1 / 3 的增加,假设每 ASCII 字符 8 个比特)]。
用途是 Adobe 的 PostScript 和 Portable Document Format 文件格式,以及 Git 使用的二进制文件的补丁编码。
与 Base64 一样,Base85 编码的目标是对二进制数据可打印的 ASCII 字符进行编码。但是它使用了更大的字符集,因此效率更高一些。具体来说,它可以用 5 个字符编码 4 个字节(32 位)。
base64¶
Base64 编码是使用 64 个可打印 ASCII 字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成 ASCII 字符串,另有 “=” 符号用作后缀用途。
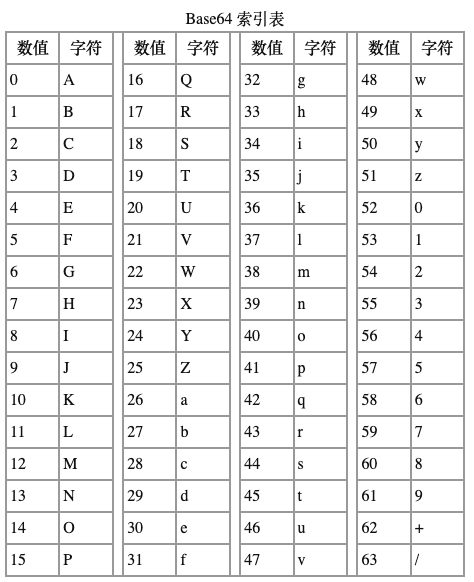
base64 索引¶
备注
Base64 将输入字符串按字节切分,取得每个字节对应的二进制值(若不足 8 比特则高位补 0),然后将这些二进制数值串联起来,再按照 6 比特一组进行切分(因为 2^6=64),最后一组若不足 6 比特则末尾补 0。将每组二进制值转换成十进制,然后在上述表格中找到对应的符号并串联起来就是 Base64 编码结果。
备注
由于二进制数据是按照 8 比特一组进行传输,因此 Base64 按照 6 比特一组切分的二进制数据必须是 24 比特的倍数(6 和 8 的最小公倍数)。24 比特就是 3 个字节,若原字节序列数据长度不是 3 的倍数时且剩下 1 个输入数据,则在编码结果后加 2 个 =;若剩下 2 个输入数据,则在编码结果后加 1 个 =。
完整的 Base64 定义可见 RFC1421 和 RFC2045。因为 Base64 算法是将 3 个字节原数据编码为 4 个字节新数据,所以 Base64 编码后的数据比原始数据略长,为原来的 4/3。在电子邮件中,根据 RFC822 规定,每 76 个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的 135.1%。
备注
Base64 可用于任意数据的底层二进制数据编码,以应用于只能传输 ASCII 字符的场合。不过最常用于文本数据的处理传输,例如在 MIME 格式的电子邮件中,Base64 可以用来编码邮件内容,方便在不同语言计算机间传输而不乱码,注意是传输而不是显示,例如在西欧地区计算机上使用 utf-8 编码即可正常显示中文(安装有对应字库),但是它未必能正常传输中文,这时转换为 Base64 便无此顾虑。
备注
Base64 编码若无特别说明,通常约定非 ASCII 字符按照 UTF-8 字符集进行编码处理。
由来¶
Base64算法最早应用于解决电子邮件传输问题,在早期,电子邮件只支持ASCII码字符。
而ASCII码其长度为1个字节,是7位编码,最高位是0,是有符号字符型数。
如果要传输一封带有非ASCII码字符的电子邮件,当它经过部分网关时就可能出现问题,这个网关可能会对非ASCII码字符的二进制位进行调整,即将这个非ASCII码的8位二进制码最高位置设置为0,此时用户收到的邮件就会是一封乱码的了。由此原因产生了Base64算法。
URL安全的Base64编码(URL Base64)¶
UrlBase64 是 Base64 编码的一种变体,主要用于在 URL 中安全地传输二进制数据。
Base64编码可用于在HTTP环境下传递较长的标识信息。在其他应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。此时,采用Base64编码不仅比较简短,同时也具有不可读性,即所编码的数据不会被人用肉眼所直接看到。
然而,标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的「/」和「+」字符变为形如「%XX」的形式,而这些「%」号在存入数据库时还需要再进行转换,因为ANSI SQL中已将「%」号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它不在末尾填充’=’号,并将标准Base64中的「+」和「/」分别改成了「*」和「-」,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
URL安全的Base64编码适用于以URL方式传递Base64编码结果的场景。该编码方式的基本过程是先将内容以Base64格式编码为字符串,然后检查该结果字符串,将字符串中的加号+换成中划线-,并且将
斜杠/换成下划线_。详细编码规范请参考RFC4648标准中的相关描述。
补充:对于末尾的“=”占位符,Bouncy Castle将之用.代替,而Commons Codes杜绝任何的补位符。下面的示例代码使用了Bouncy Castle的方法,将“=”用“.”代替。
Base62¶
使用了 62 个字符编码,包括 0-9,a-z,A-Z
相比Base64去除了 +和/
base58¶
Base58 是用于比特币(Bitcoin)中使用的一种独特的编码方式,主要用于产生 Bitcoin 的钱包地址。
相比 Base64,Base58 不使用数字 “0”,字母大写 “O”,字母大写 “I”,和字母小写 “l”,以及 “+” 和 “/” 符号。
比特币的 Base58 字母表:
123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz
Base58 的作用¶
比特币私钥最原始的格式是 256 位的二进制表示,也就是 256 个 0 或者 1。下面就是一个栗子:
1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0 1 1 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 0
这么长的东西不但不方便记录,还占用太多的储存空间!所以比特币系统就采用了 base58 编码的方式来 “缩短”,一个 base58 编码后的私钥只有这么长:
J3mBbAH58CpQ3Y5RNJpUKPE62SQ5tfcvU2JpbnkeyhfsYB1Jcn
Base58 的原理¶
二进制:0 和 1
十进制:1 到 10
十六进制:十进制的基础上加上了 A-F 六个字母
...
Base58 可以理解为一种 58 进制。
Base58 包含了阿拉伯数字、小写英文字母,大写英文字母。
但是去掉了一些容易混淆的数字和字母:0(数字 0)、O(o 的大写字母)、l( L 的小写字母)、I(i 的大写字母)
Base45¶
(A-Z0-9$%*+./ :-)
base38¶
(A-Z0-9.-)
base32¶
Base32 使用了 ASCII 编码中可打印的 32 个字符 (大写字母 A~Z 和数字 2~7) 对任意字节数据进行编码.Base32 将串起来的二进制数据按照 5 个二进制位分为一组,由于传输数据的单位是字节 (即 8 个二进制位). 所以分割之前的二进制位数是 40 的倍数 (40 是 5 和 8 的最小公倍数). 如果不足 40 位,则在编码后数据补充 “=”,一个 “=” 相当于一个组 (5 个二进制位),编码后的数据是原先的 8/5 倍.
Base32 将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足 8 比特高位补 0)串联起来,按照 5 比特一组进行切分,并将每组二进制值转换成十进制来对应 32 个可打印字符中的一个。
由于数据的二进制传输是按照 8 比特一组进行(即一个字节),因此 Base32 按 5 比特切分的二进制数据必须是 40 比特的倍数(5 和 8 的最小公倍数)。例如输入单字节字符 “%”,它对应的二进制值是 “100101”,前面补两个 0 变成 “00100101”(二进制值不足 8 比特的都要在高位加 0 直到 8 比特),从左侧开始按照 5 比特切分成两组:“00100” 和 “101”,后一组不足 5 比特,则在末尾填充 0 直到 5 比特,变成 “00100” 和 “10100”,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符 “E” 和 “U”,但是这里只用到两组共 10 比特,还差 30 比特达到 40 比特,按照 5 比特一组还需 6 组,则在末尾填充 6 个 “=”。填充 “=” 符号的作用是方便一些程序的标准化运行,大多数情况下不添加也无关紧要,而且,在 URL 中使用时必须去掉 “=” 符号。
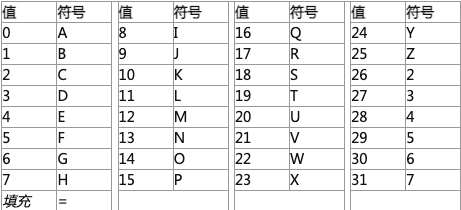
与 Base64 相比,Base32 具有许多优点:
适合不区分大小写的文件系统,更利于人类口语交流或记忆。
结果可以用作文件名,因为它不包含路径分隔符 “/” 等符号。
排除了视觉上容易混淆的字符,因此可以准确的人工录入。(例如,RFC4648 符号集忽略了数字 “1”、“8” 和 “0”,因为它们可能与字母 “I”,“B” 和 “O” 混淆)。
排除填充符号 “=” 的结果可以包含在 URL 中,而不编码任何字符。
Base32 也比 Base16 有优势:
Base32 比 Base16 占用的空间更小。(1000 比特数据 Base32 需要 200 个字符,而 Base16 则为 250 个字符)
Base32 的缺点:
Base32 比 Base64 多占用大约 20%的空间。
因为 Base32 使用 8 个 ASCII 字符去编码原数据中的 5 个字节数据,而 Base64 是使用 4 个 ASCII 字符去编码原数据中的 3 个字节数据。
base16¶
Base16 编码使用 16 个 ASCII 可打印字符(数字 0-9 和字母 A-F)对任意字节数据进行编码。Base16 先获取输入字符串每个字节的二进制值(不足 8 比特在高位补 0),然后将其串联进来,再按照 4 比特一组进行切分,将每组二进制数分别转换成十进制,在下述表格中找到对应的编码串接起来就是 Base16 编码。
Base16 编码是一个标准的十六进制字符串(注意是字符串而不是数值),更易被人类和计算机使用,因为它并不包含任何控制字符,以及 Base64 和 Base32 中的 “=” 符号。
Base16 编码的方式¶
将数据 (根据 ASCII 编码,UTF-8 编码等) 转成对应的二进制数,不足 8 比特位高位补 0。然后将所有的二进制全部串起来,4 个二进制位为一组,转化成对应十进制数。
根据十进制数值找到 Base16 编码表里面对应的字符。Base16 是 4 个比特位表示一个字符,所以原始是 1 个字节 (8 个比特位) 刚好可以分成两组,也就是说原先如果使用 ASCII 编码后的一个字符,现在转化成两个字符。数据量是原先的 2 倍。