3.1. 常用¶
可观测性: Observability
可控制性: Controllability
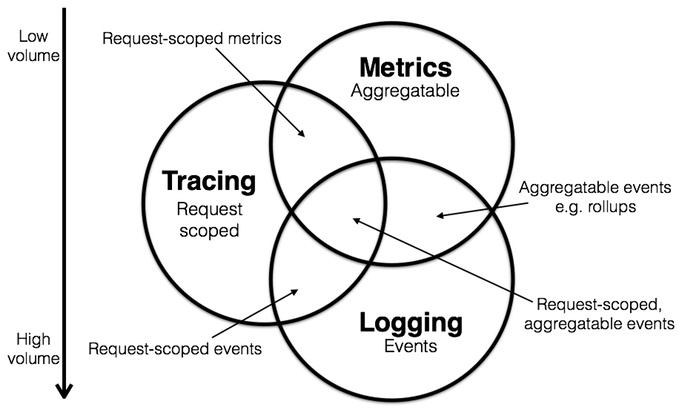
通常一个线上问题的定位流程是:通过 Metric 发现问题,根据 Trace 定位到问题模块,根据模块具体的日志定位问题原因。 Logging,Metrics 和 Tracing 有各自专注的部分:
Logging - 用于记录离散的事件
例如, 应用程序的调试信息或错误信息,它是我们诊断问题的依据
Metrics - 用于记录可聚合的数据
例如,
队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新
HTTP 请求个数可被定义为一个计数器,新请求到来时进行累加
Tracing - 用于记录请求范围内的信息
例如, 一次远程方法调用的执行过程和耗时,它是我们排查系统性能问题的利器
这三者也有相互重叠的部分,如下图所示:
全链路追踪目的:
1. 故障快速定位
跨语言实现开发中在业务日志中添加调用链 ID,可以通过调用链结合业务日志快速定位错误信息。
2. 各个调用环节的性能分析
分析调用链的各个环节耗时,分析系统的性能瓶颈,找到系统的薄弱环节针对性优化
3. 数据分析
分析用户的行为路径,经过了哪些服务器上的哪个服务加以应用。
4. 调用拓扑图
Trace 系统设计目标:
低侵入、低损耗、大范围部署
Metrics, tracing, and logging: http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
9 个技巧,解决 K8s 中的日志输出问题: https://www.cnblogs.com/alisystemsoftware/p/12408258.html