常见指标¶
单位:
1ns 纳秒(nano second)
1us = 1,000ns 微秒(micro second)
1ms = 1,000us 毫秒(milli second)
1s = 1,000ms 秒
响应指标¶
常见响应指标¶
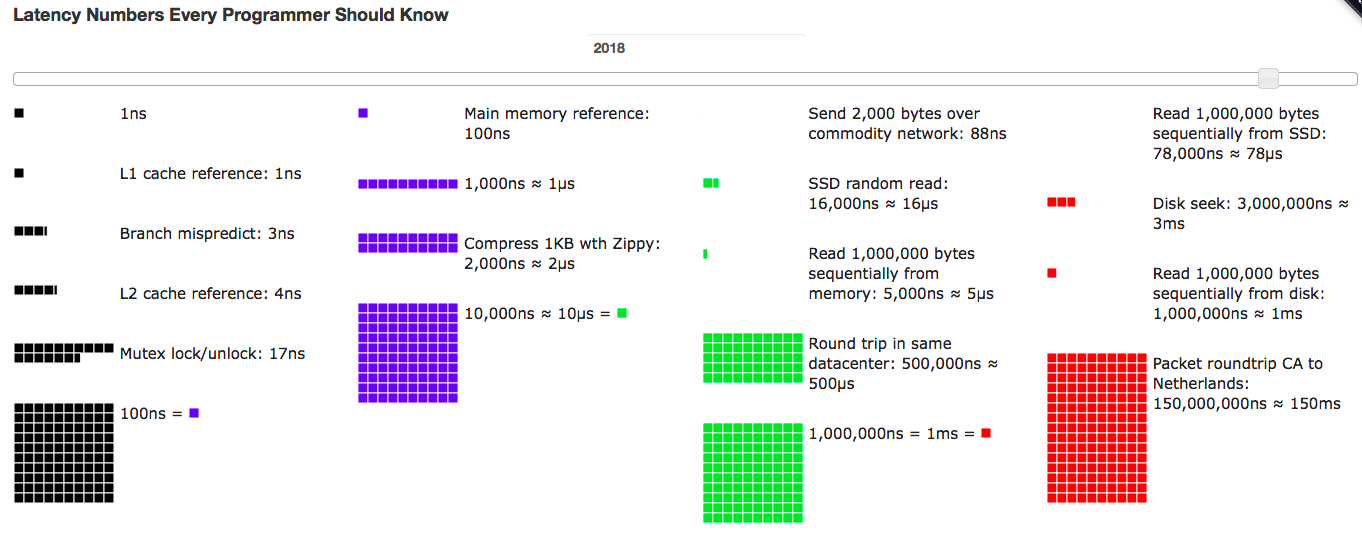
每个程序员都应该知道的延迟数字¶
《Teach Yourself Programming in Ten Years》:
1. fetch from L1 cache memory(从一级缓存中读取数据):
0.5 nanosec
2. branch misprediction(分支预测失败):
5 nanosec
3. fetch from L2 cache memory(从二级缓存获取数据):
7 nanosec
4. Mutex lock/unlock(互斥加锁 / 解锁):
25 nanosec
5. fetch from main memory(从主内存获取数据):
100 nanosec
6. send 2K bytes over 1Gbps network(通过 1G bps 的网络发送 2K 字节):
20,000 nanosec = 20us(微秒)
7. read 1MB sequentially from memory(从内存中顺序读取 1MB 数据):
250,000 nanosec = 250us
8. fetch from new disk location (seek)(从新的磁盘位置获取数据(寻道)):
8,000,000 nanosec = 8ms(毫秒)
9. read 1MB sequentially from disk(从磁盘中顺序读取 1MB 数据):
20,000,000 nanosec =20ms
10. send packet US to Europe and back(从美国发送一个报文包到欧洲再返回):
150 milliseconds = 150,000,000 nanosec
用户体验¶
交互响应时间 超过 100~200ms 就被认为是不好的
用户体验来说:
1. 0~200ms,用户无感知 2. 200ms~1s,稍感延迟,可接受 3. 1~Ns,明显等待,越长体验越差
操作系统¶
按页读取:
一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看
一次会读一页的数据。如果要读取的数据量超过一页的大小,就会触发多次 IO 操作
我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作。
高速缓存的读取时间可能是 0.5ns
而内存的访问时间可能是 50ns
并发指标¶
常见并发指标¶
redis: 并发请求数也就每秒 3-5 万(基于 Reactor 模式)
nginx 负载均衡性能是 3-5 万左右(基于 Reactor 模式)
mc 的读取性能 3-5 万左右(基于 Reactor 模式)
LVS 的性能是十万级,据说可达到 80 万 / 秒
F5 性能是百万级,从 200 万 / 秒到 800 万 / 秒都有
kafka 号称百万级, 百万级是集群性能
zookeeper 写入读取 2 万以上
http 请求访问大概在 1.5-2 万左右(HTTP get 操作访问一个简单页面测试结果)
MySQL 的 TPS 和写入的数据有关:
写入 k/v 数据,主键存储 key,上万TPS 读取 k/v 数据,可以达到10万 QPS mysql 官网 benchmarks: https://www.mysql.com/why-mysql/benchmarks/ 单机 32users 并发只读近 40w+ qps,读写 10w+ qps 说明: 这个数据有误导性,要看具体的 SQL 语句和表结构,实际应用中一般不可能这么高 这个数据是简单的 k/v 数据NoSQL量级一般都是上万,但和测试硬件测试用例相关
业务系统一个 TPS 接口的请求时间 10~50ms 是比较合理的,QPS 5~20ms 是比较合理的
理想情况下,性能测试的时候,CPU 能压到 80% 以上,此时的 TPS/QPS 就是峰值,如果 CPU 没压满,指标就上不去,就可能有优化的空间。 如果是业务系统,由于业务复杂度差异很大,有的每秒 500 请求可能就是高性能了,因此需要针对业务进行性能测试,确立性能基线,方便后续架构设计做比较
http 相关性能:
Spring Boot 基于 HTTP 协议的,HTTP 协议本身的解析非常耗性能
我们之前实测 Hello world,16 核或者 32 核的机器,单机 TPS 也就 1.5 万左右(核数增加对性能作用不大)
一般把日活转换为 pv,然后按 pv 计算 QPS
单台服务器性能一般是:
企业用的线上物理服务器,如: 16 核 16g 32 核 16G 与时俱进,现在基本都是 32 核 48g 内存 云主机的性能可以按照同配置的物理机 80% 的性能来估算
服务器¶
一台机器最多开65535个 port, 其中压测可用的 port 是
32768~65535,也就是每个兵团的士兵可达到32768个单机可以支持: C100K, C1000K, C1M, C10M, C20M
单进程文件句柄最大可以设置:
即: 单个进程可分配的最大文件数 在我们使用ulimit或limits.conf来设置时,如果要超过默认的1048576值时需要先增大nr_open值 注: Linux 内核 2.6.25 以前,在内核里面宏定义是 1024*1024,最大只能是 100w(1048576) 如果 Linux 内核大于 2.6.25 则可以设置更大值
Java¶
经过 Netty 封装相比Java 原生 NIO,大约有 10% 的性能损耗:
在 1K 大小报文时
原生的 Java NIO 在当时的测试环境所能达到 TPS(每秒事务数) 的极限大约 5 万出头,
而 Netty 在 4.5 万附近
增加了 RPC 的编解码后,TPS 极限下降至 1.3 万左右
加上不算简单的业务逻辑,能预期的单实例真实 TPS 也许只有 1 千 ~2 千
注: 极限,就是继续加压,但 TPS 不再上升,CPU 也消耗不上去,延时却在增加
内存, 磁盘指标¶
一个TCP套接字连接占用的内存做分析,大概占4KByte
内存:
单根 DDR4 内存的数据传输带宽最高为 34GB/s
工作频率最高可达 4266MHz
以 PC 为例:
Intel 386 时代服务器存储能力只有几百 MB
Intel 奔腾时代服务器存储能力可以有几十 GB
Intel 酷睿多核时代的服务器可以有几个 TB
估算一下,给这 1 亿张图片构建散列表大约需要多少台机器:
1. 假设我们通过 MD5 来计算哈希值,那长度就是 128 比特,也就是 16 字节
2. 文件路径长度的上限是 256 字节,我们可以假设平均长度是 128 字节
3. 如果我们用链表法来解决冲突,那还需要存储指针,指针占用 8 字节
所以,散列表中每个数据单元就占用 152 字节(这里只是估算,并不准确)
假设一台机器的内存大小为 2GB,散列表的装载因子为 0.75,
那一台机器可以给大约 1000 万(2GB*0.75/152)张图片构建散列表
所以,如果要对 1 亿张图片构建索引,需要大约十几台机器。
在工程中,这种估算还是很重要的,
能让我们事先对需要投入的资源、资金有个大概的了解,能更好地评估解决方案的可行性。
内存的访问速度是纳秒级别的
磁盘访问的速度是毫秒级别的
从内存中读取所花费时间的上万倍,甚至几十万倍
磁盘¶
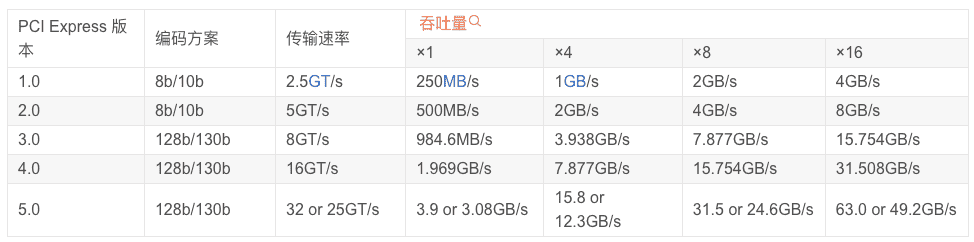
说明:
PCI Express主要用于连接高速设备,如显卡、声卡等
使用点对点串行连接,每个设备都有自己的专用连接,不需要向整个总线请求带宽,而且可以把数据传输率提高到一个很高的频率,达到PCI所不能提供的高带宽。
SATA 3.0则主要用于连接存储设备,如硬盘和光驱
SATA 3.0 的接口:
带宽是 6Gb/s(转Byte=768MB)
PCI Express 的接口:
在读取的时候就能做到 2GB/s 左右,差不多是 HDD 硬盘的 10 倍
在写入的时候也能有 1.2GB/s
IOPS 也就是在 2 万左右
HDD 硬盘(机械硬盘):
5400转笔记本硬盘平均读写速度大致在60-90MB这个区间
7200转台式机硬盘大致在130-190MB区间
10000转和15000转台式机硬盘数据不详
数据传输率,差不多在 200MB/s 以内
IOPS 通常在 100 左右
随机读取磁盘上某一个 4KB 大小的数据:
在随机读写的时候,数据传输率也只能到 40MB/s 左右,是顺序读写情况下的几十分之一
响应时间指标:
SSD 硬盘: 几十微秒
HDD 硬盘: 几毫秒到十几毫秒
传输速度¶
线路传输的速度是毫秒级别:
1. 同一机房: 内部能够做到几毫秒; 2. 同城异地: 几毫秒~十几毫秒(距离上一般大约就是几十千米) 3. 跨城异地: 几十甚至上百毫秒(几百、上千千米) 例如: 从广州机房到北京机房,稳定情况下 ping 延时大约是 50ms,不稳定情况下可能达到 1s 甚至更多 4. 跨国异地: 几秒钟
光速真空传播大约是每秒 30 万千米
在光纤中传输的速度大约是每秒 20 万千米
光速:C = 30 万千米 / 秒
光纤:V = C/1.5=20 万千米 / 秒
网速:
2017 年 11 月知名测速网站 Ookla 发布报告,全国平均上网带宽达到 61.24 Mbps,
千兆带宽下 10KB 数据的极限 QPS 为 1.25 万 QPS=1000Mbps/8/10KB
实例1:
北京到广州距离为2100多公里,即: 理想情况下,光纤在北京到广州传输需要0.21/20=0.01s=10ms
但传输中的各种网络设备的处理,实际还远远达不到理论上的速度
一般从广州机房到北京机房,稳定情况下 延时大约是 50ms
实例2:
地球到火星距离是 0.55~4 亿千米。近距离约为 5500 万公里,最远距离则超过 4 亿公里。
2021 年 5 月 15 日祝融号登陆的 9 分钟被称作 “恐怖 9 分钟,因为这9分钟我们是不可能操控探测器的。
原因是地球在与火星通讯的时候会有十几二十分钟的延迟。
这十几分钟延迟算法如下:
按光在真空中最快的30万km/s,距离5500-40000万km延时分别为:
5500/30 ~ 40000/30 = 183s ~ 1333s = 3分钟~22分钟
这是最理想的速度的延时。
pv/qps 计算¶
pv = 日活 * 人均点击次数
并发均值 = pv/86400
并发峰值 = 并发均值 * N
1. 响应时间(RT)
2. 并发数(Concurrency)
3. 吞吐量(TPS)
吞吐量 = 并发数 / 平均响应时间
最⼤吞吐量: 可⽀持的带宽
最⼤并发连接数: 每秒连接的总数量,体现并发处理连接的能⼒
CPS: 每秒新建连接数:每秒新建连接的数量,体现处理新增连接的能⼒
PPS: 每秒处理包量: 每秒钟转发的包量,体现包转发速率
QPS: Query Per Second(每秒请求数,一般指读取,TPS)
TPS: Transactions Per Second(每秒事务数,一般指写入,QPS)
并发数:同一时刻的接收的访问数量,时间单位一般用秒,也可以用分钟和小时,常见有并发请求数,并发连接数
日活:每日活跃用户数,指当天来访问过系统的用户,同一用户,无论用户访问多少功能和页面都只算一个用户
可靠性¶
单机的可靠性大概是 100 天丢失一次数据,数据修复时间是 1 天(即可靠性是 2 个 9)
单机可靠性只有两个 9 不是算出来的,统计出来的
tmp¶
UNIX 网络编程¶
RTT在一个局域网上大约是几毫秒,跨越一个广域网则可能是数秒钟
参考¶
伯克利大学的一个动态网页可以查看每年计算机中各类操作耗时、延迟的变化: https://colin-scott.github.io/personal_website/research/interactive_latency.html