4.1.1. 常用¶
k8s监控:
container_cpu_system_seconds_total{container_name="POD",namespace="monitoring"}
container_cpu_user_seconds_total{container_name="POD",namespace="monitoring"}
page cache used by the container, in bytes:
container_memory_cache{container_name="POD",namespace="monitoring"}
resident set size (RSS):
container_memory_rss{container_name="POD",namespace="monitoring"}
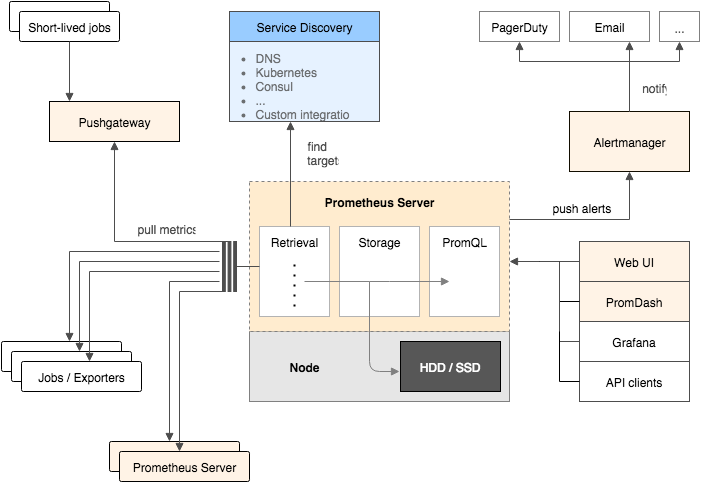
组件¶
Prometheus Server:
主要负责数据采集和存储,提供PromQL查询语言的支持
Push Gateway:
支持临时性Job主动推送指标的中间网关
DashBoard:
使用rails开发的dashboard,用于可视化指标数据
PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据
AlertManager:
警告管理器,用来进行报警
独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式
Exporter:
Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。
与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。
支持其他数据源的指标导入到Prometheus,支持数据库、硬件、消息中间件、存储系统、http服务器、jmx等, 也可以自行开发
指标类型¶
Prometheus定义了4种不同的指标类型(metric type):
Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)
Counter:只增不减的计数器:
Counter类型的指标其工作方式和计数器一样,只增不减
常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标
一般在定义Counter类型指标的名称时推荐使用_total作为后缀
实例:
1. 例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
2. 查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
Gauge:可增可减的仪表盘:
Gauge类型的指标侧重于反应系统的当前状态
常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标
实例:
1. 直接查看系统的当前状态:
node_memory_MemFree
2. 通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况
例如,计算CPU温度在两个小时内的差异
delta(cpu_temp_celsius{host="zeus"}[2h])
3. 使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测
例如,预测系统磁盘空间在4个小时之后的剩余情况
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
使用Histogram和Summary分析数据分布情况:
Histogram和Summary主用用于统计和分析样本的分布情况
例如CPU的平均使用率、页面的平均响应时间
例如,统计延迟在0~10ms之间的请求数有多少而10~20ms之间的请求数又有多少
1. prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。
它记录了Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址
2. 类型为Histogram的监控指标prometheus_tsdb_compaction_chunk_range_bucket
可以通过histogram_quantile()函数计算出其值的分位数
参考文档¶
Prometheus 实战: https://songjiayang.gitbooks.io/prometheus/content/