# 2403.07974_LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
* 首页: [https://arxiv.org/abs/2403.07974](https://arxiv.org/abs/2403.07974)
* PDF: [https://arxiv.org/pdf/2403.07974](https://arxiv.org/pdf/2403.07974)
* 引用: 464(2025-07-22)
* 组织: UC Berkeley, MIT, Cornell
* 首页:
* GitHub:
* HuggingFace:
## 总结
* LiveCodeBench 的评估框架
* 评估大型语言模型(LLM)在编程任务中的表现
* 从LeetCode、AtCoder和CodeForces三大竞赛平台收集2023年5月至2024年5月期间发布的新题目
* 构建了一个污染较少、内容更新及时、覆盖更广的评测集
* 核心设计原则
* 动态更新,防止数据污染
* 从竞赛平台(如LeetCode、AtCoder、CodeForces)收集每周更新的问题,并标注发布时间
* 对于新模型,仅评估其在发布时间晚于其训练截止日期的问题上的表现,避免训练数据中已包含该问题
* 全面评估多个代码能力
* 除了传统的“自然语言到代码生成”外,LiveCodeBench还评估以下三种能力:
* Self-Repair:根据执行反馈修复错误程序,评估调试能力
* Code Execution:给定程序和输入,输出执行结果,评估代码理解能力
* Test Output Prediction:根据自然语言任务和输入,预测输出,评估测试输出生成能力
* 实证结果与发现
* 数据污染现象明显:LLM在训练阶段可能接触过早期问题,存在污染风险
## LLM总结
主要介绍了一个名为 **LiveCodeBench** 的评估框架,用于全面且**无污染**地评估大型语言模型(LLM)在编程任务中的表现。
**总结:**
LiveCodeBench 是一个为代码领域设计的新型评估基准,旨在全面评估大型语言模型在编程任务中的能力,同时避免因模型训练数据中包含测试数据而导致的“污染”问题。该基准通过真实、多样、高质量的编程任务组合,测试模型在代码生成、调试、理解、优化等多个方面的综合能力。作者强调,该框架不依赖于任何模型训练中可能包含的数据,从而确保评估结果的公正性和有效性。这一方法为未来研究提供了一个更可靠、更公平的模型评估方式。
## Abstract
该论文章节主要介绍了**LiveCodeBench**,这是一个用于评估**大型语言模型(LLMs)在代码相关任务中的表现**的新型基准测试平台。文章指出,随着LLMs的快速发展,传统评估基准(如HumanEval、MBPP)已无法全面衡量模型的能力。LiveCodeBench通过从LeetCode、AtCoder和CodeForces三大竞赛平台收集2023年5月至2024年5月期间发布的新题目,构建了一个**污染较少、内容更新及时、覆盖更广的评测集**。
除了基本的代码生成能力,LiveCodeBench还评估了LLMs在**自我修复、代码执行、测试输出预测**等方面的表现。文章中还展示了对大量基础模型和指令微调模型的评估结果,并探讨了**数据污染问题、现有基准可能存在的过拟合现象**,以及不同模型之间的性能比较。最后,作者承诺公开所有提示和模型生成结果,提供工具包供社区扩展和研究使用。
## 1 Introduction
该论文的引言部分主要探讨了当前大语言模型(LLMs)在代码相关任务中的广泛应用以及评估方法的不足,并提出了一个名为 **LiveCodeBench** 的新型代码能力评估基准。以下是该章节的核心内容总结:
---
### 一、背景与问题
1. **代码领域的LLM发展迅速**
多个代码专用模型(如Codestral、DeepSeek、GPT-4-O等)被提出,并广泛应用于程序修复、优化、测试生成、文档生成、SQL生成等领域。
2. **评估方法存在局限**
尽管模型发展迅速,但评估手段相对滞后。现有基准(如HumanEval、MBPP、APPS)存在两个主要问题:
- **评估范围局限**:仅关注自然语言到代码生成任务,忽视了编程中的多种能力。
- **数据污染和过拟合风险**:基准问题可能已被模型在训练中接触,导致评估结果失真。
---
### 二、LiveCodeBench的提出
为解决上述问题,作者提出了 **LiveCodeBench**,一个**动态更新且无数据污染**的代码能力评估框架。其核心设计原则包括:
1. **动态更新,防止数据污染**
- 通过从竞赛平台(如LeetCode、AtCoder、CodeForces)收集每周更新的问题,并标注发布时间。
- 对于新模型,仅评估其在**发布时间晚于其训练截止日期**的问题上的表现,避免训练数据中已包含该问题。
2. **全面评估多个代码能力**
除了传统的“自然语言到代码生成”外,LiveCodeBench还评估以下三种能力:
- **Self-Repair**:根据执行反馈修复错误程序,评估调试能力。
- **Code Execution**:给定程序和输入,输出执行结果,评估代码理解能力。
- **Test Output Prediction**:根据自然语言任务和输入,预测输出,评估测试输出生成能力。
3. **高质量问题与测试用例**
- 问题来源自经过验证的竞赛平台,确保题面清晰、测试充分。
- 平均每个问题提供约17个测试用例,保证评估的鲁棒性和可靠性。
4. **平衡问题难度分布**
- 通过平台提供的难度评分,筛选并分类问题,确保评估覆盖不同难度层级,避免模型表现趋同。
---
### 三、实证结果与发现
作者在LiveCodeBench上评估了18个基础模型和34个指令调优模型,得出以下关键结论:
1. **数据污染现象明显**
- DeepSeek、GPT-4-O和Codestral等模型在训练截止日期后发布的LeetCode问题上表现显著下降,说明其在训练阶段可能接触过早期问题,存在污染风险。
2. **模型能力在不同任务中表现差异大**
- 不同模型在代码生成、自修、执行、测试预测等任务中的表现差异显著,强调了**综合评估的重要性**。
- 例如,Claude-3-Opus在测试预测任务上甚至优于GPT-4。
3. **HumanEval存在过拟合风险**
- 某些模型在HumanEval上表现良好,但在LiveCodeBench上表现较差,表明它们可能过拟合了HumanEval数据。
4. **模型对比揭示能力差距**
- 封闭API模型(如GPT、Claude、Gemini)普遍优于开放模型。
- 在LiveCodeBench中,GPT-4和GPT-4-Turbo在所有场景中表现最佳(除Claude-3-Opus外)。
---
### 四、相关工作对比
LiveCodeBench与已有方法相比具有以下优势:
- **时间分割评估**:与Huang et al. (2023)类似,但覆盖了多个竞赛平台。
- **多任务评估**:与Li et al. (2023c)和Singhal et al. (2024)不同,不仅关注生成任务,还引入了代码理解、调试和测试预测等能力。
- **污染检测机制**:与Guo et al. (2024)相比,更系统地检测并避免了数据污染问题。
---
### 五、总结
**LiveCodeBench** 是一个**动态更新、无污染、综合评估代码能力**的基准平台,解决了传统评估方法在覆盖范围和公平性上的不足。通过实证分析,作者揭示了当前主流模型在真实代码任务上的表现差异,并提供了更准确、更公平的模型比较依据。
## 2 Holistic Evaluation
本章提出了一种对代码相关能力进行**综合性评估**(Holistic Evaluation)的方法,旨在更全面地衡量大语言模型(LLMs)在软件工程中的实际能力。
传统上,代码生成任务是评估模型代码能力的主要方式,但实际软件开发需要更多维度的技能,如测试用例生成、调试、代码理解、文档编写等。这些能力不仅对代码质量、可维护性和可靠性至关重要,也能帮助模型在代码生成任务中表现更好。文章以 **AlphaCodium** 为例,展示了在编程竞赛中结合自然语言推理、测试生成、代码生成和自修复的流程可以显著提升模型性能。
基于此,作者提出了 **LiveCodeBench** 评估框架,涵盖四种评估场景,每种场景都有清晰的自动化评估指标:
1. **代码生成(Code Generation)**
模型根据自然语言描述和示例输入输出生成代码,评估其是否能通过未见测试用例。
- 使用 Pass@1 指标衡量生成代码的正确性。
2. **自修复(Self-Repair)**
模型在初始生成错误代码后,根据错误反馈(如异常信息或失败测试用例)进行修正。
- 评估最终代码的正确性,仍使用 Pass@1 指标。
3. **代码执行预测(Code Execution)**
模型根据给定的代码片段和测试输入,预测代码执行的输出。
- 评估方式是验证预测输出是否与实际执行结果一致。
4. **测试用例输出预测(Test Case Output Prediction)**
模型根据问题陈述和测试输入预测预期输出,不涉及测试输入的生成。
- 该任务有助于评估模型对问题的理解能力和测试生成能力。
此外,作者提到 **LiveCodeBench** 是一个可扩展的框架,未来可以集成更多任务,如输入生成、程序总结、优化等。
**总结**:本章强调了对代码生成任务以外的多维度能力进行评估的重要性,并通过 LiveCodeBench 框架系统性地提出了四种评估场景,以更全面地衡量模型在实际软件开发中的潜力。
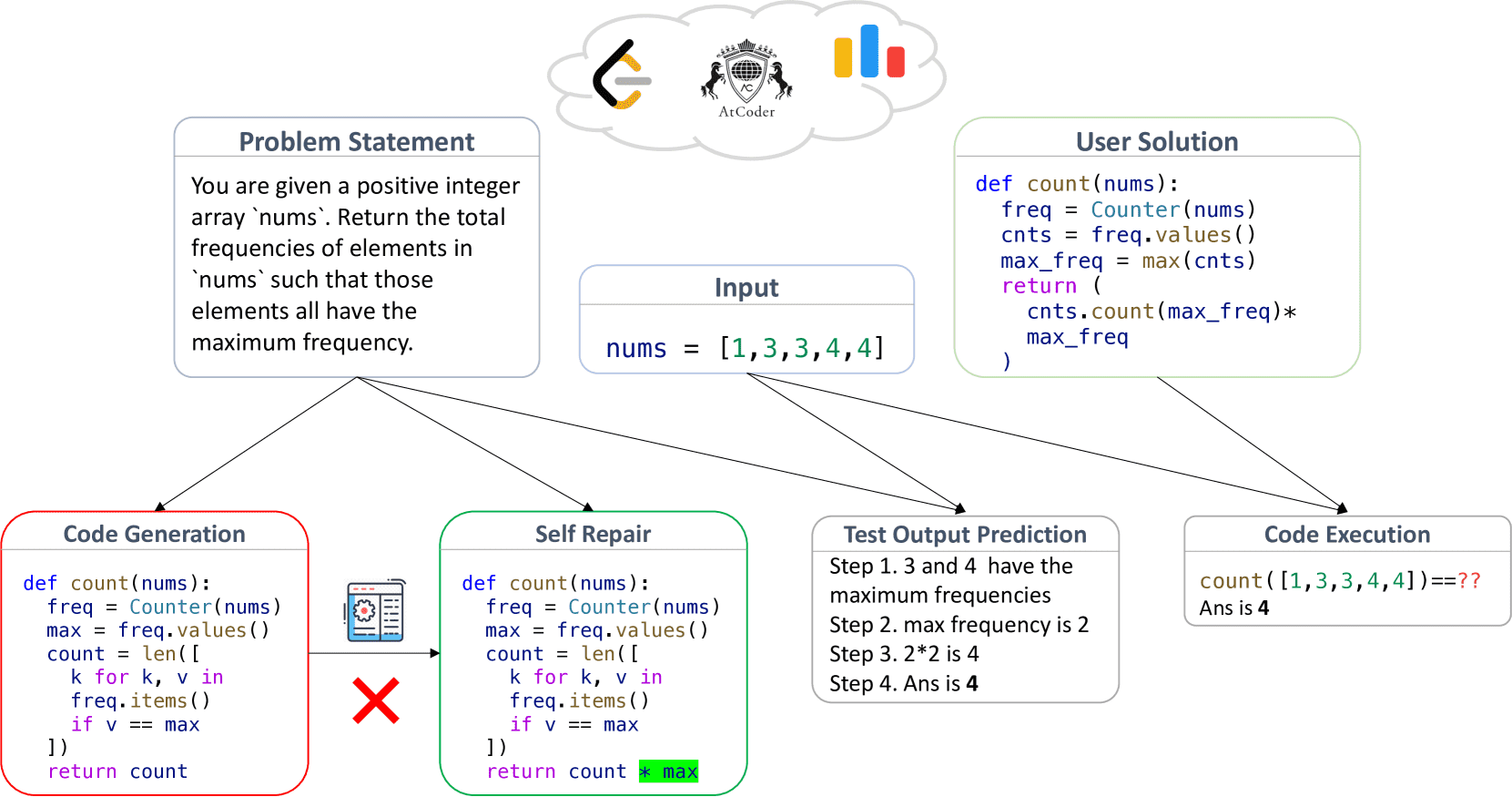
Figure 3: Overview of the different scenarios present in LiveCodeBench. Coding is multi-faceted and we propose evaluating LLMs on a suite of evaluation setups that capture various coding-related capabilities. Specifically, beyond the standard code generation setting, we consider three additional scenarios, namely self-repair, code execution, and a newly introduced test output prediction task.
## 3 Benchmark Curation
本节介绍了 **LiveCodeBench** 基准数据集的构建过程,主要涵盖问题的收集、筛选和分类,以及针对不同评估场景(如代码生成、测试输出预测等)的专门构建方法。作者从 **LeetCode**、**AtCoder** 和 **CodeForces** 三大编程竞赛平台收集问题,确保问题具有挑战性、清晰度及正确性。
---
### **3.1 数据收集(Data Collection)**
- 使用 HTML 抓取工具从各平台收集问题及其元数据。
- 筛选出适合通过输入输出样例进行评估的问题,排除含图像、答案不唯一或需构造数据结构的问题。
- 收集每个问题的 **自然语言描述**(P)、**测试用例**(T)和 **标准答案**(S),并记录其 **发布日期**(D)。
- 通过时间窗口筛选问题,可以评估模型在不同时间点的表现,用于对比模型的演化能力。
- 测试用例优先使用平台提供的,若不可用则使用 LLM(如 GPT-4-Turbo)并结合上下文学习生成输入生成器。
- 对部分新问题,收集平台提供的失败测试,用于对抗性测试。
---
### **3.2 平台特定的处理(Platform Specific Curation)**
- **LeetCode**:收集 2023 年 4 月后所有周赛与双周赛的问题,包含问题描述、公共测试用例和用户提交代码。由于隐藏测试不可用,使用生成器生成测试,并收集部分失败测试。
- **AtCoder**:仅收集 abc(初学者)比赛的问题,避免难度更高 arc 和 agc 比赛。根据平台难度评分(最高 500)将问题分为 Easy、Medium、Hard。
- **CodeForces**:收集 Division 3 和 4 的问题,尽管经过筛选,仍比其他平台更难。根据评分将问题划分为不同难度等级,并因测试不完整需手动生成部分测试用例。
---
### **3.3 针对不同场景的基准构建(Scenario-specific benchmark construction)**
- **代码生成与自我修复(Code Generation and Self-Repair)**:
- 使用自然语言问题描述构建问题。
- LeetCode 提供初始代码,AtCoder 和 CodeForces 使用标准输入格式。
- 使用收集或生成的测试用例评估生成代码的正确性。
- 最终共构建 511 个问题实例。
- **代码执行(Code Execution)**:
- 参考 Gu 等人的方法,从 LeetCode 收集约 2000 个用户提交的正确代码。
- 通过编译时和运行时过滤,剔除结构复杂、执行步骤多的代码,并进行人工核查。
- 最终构建 479 个代码执行样本,来自 85 个问题。
- **测试输出预测(Test Case Output Prediction)**:
- 使用 LeetCode 的自然语言问题描述和示例测试输入,构建测试输出预测任务。
- 示例输入对人类和 LLM 都有良好的测试代表性。
- 最终构建 442 个问题实例,来自 181 个 LeetCode 问题。
---
### **总结**
本节详细介绍了 LiveCodeBench 基准的构建过程,包括问题的收集、筛选、测试生成以及针对不同评估场景的专门构建方法。通过结合多个编程竞赛平台的问题,并利用 LLM 辅助测试生成与筛选,构建了一个全面、无污染、适合评估大语言模型代码能力的高质量基准数据集。
## 4 Experiment Setup
本章节主要介绍了实验的设置,包括通用设置和针对不同场景的特定设置,内容总结如下:
---
### **实验模型设置**
- **模型范围**:评估了 **52个模型**,模型参数规模从 **1.3B 到 70B** 不等,涵盖基础模型、指令调优模型、开源模型和闭源模型。
- **模型类别**:包括 GPT 系列(GPT-3.5-turbo、GPT-4 等)、Claude、Gemini、Mistral、LLaMa-3、DeepSeek、CodeLLaMA、StarCoder2、CodeQwen 等。
- **调优模型**:还包括从基础模型微调得到的模型,如 Phind-34B、MagiCoders。
- **完整列表**:详见附录 [C.1](https://arxiv.org/html/2403.07974v2#A3.SS1)。
---
### **评估指标**
- **主要指标**:使用 **Pass@1** 指标(Kulal et al., 2019;Chen et al., 2021),计算生成的代码中能通过测试的比例。
- **生成方式**:为每个问题生成 **10个候选答案**,使用 API 或 vLLM(Kwon et al., 2023)生成。
- **采样策略**:采用 **nucleus sampling**,温度设为 **0.2**,top_p 设为 **0.95**。
- **正确性判断**:
- **代码生成与自修复场景**:程序必须通过所有测试才算正确。
- **代码执行场景**:通过与真实输出对比判断正确性。
- **测试输出预测场景**:从生成的回答中提取答案,并通过等价性检查评分。
---
### **不同场景的实验设置**
#### **代码生成(Code Generation)**
- **指令调优模型**:采用 **zero-shot prompt**,并添加适当的指令生成解决方案(函数式或 stdin 格式)。
- **基础模型**:使用 **one-shot 示例**,并为两种输入类型(stdin 和函数输出)提供不同示例。
- **提示模板**:详见附录 [C.2](https://arxiv.org/html/2403.07974v2#A3.SS2)。
#### **自修复(Self Repair)**
- **零样本提示**:基于代码生成阶段的输出和错误反馈构建。
- **错误类型**:包括语法错误、运行时错误、答案错误、超时错误。
- **方法细节**:伪代码和提示结构详见附录 [C.3](https://arxiv.org/html/2403.07974v2#A3.SS3)。
#### **代码执行(Code Execution)**
- **提示方式**:
- 使用 **few-shot prompt**,包括有和无 **chain-of-thought(COT)** 两种方式。
- 具体为:2-shot 不带 COT,1-shot 带详细步骤的 COT。
- **提示内容**:详见附录 [C.4](https://arxiv.org/html/2403.07974v2#A3.SS4)。
#### **测试输出预测(Test Output Prediction)**
- **零样本提示**:给定问题、函数签名和测试输入,要求模型补全断言。
- **提示结构**:详见附录 [C.5](https://arxiv.org/html/2403.07974v2#A3.SS5)。
---
### **总结**
本节详细描述了实验的整体设置,包括评估的模型类别和参数规模、评估指标 Pass@1 的使用方式,以及针对代码生成、自修复、代码执行和测试输出预测四种场景的具体提示构造和评估机制。这些设置旨在全面、无污染地评估代码生成类大模型的性能。
## 5 Results
这篇论文的第五章“结果”部分主要围绕 **LiveCodeBench** 这个用于评估大型语言模型(LLMs)代码能力的基准,探讨了其如何避免**污染问题(contamination)**,并展示了模型在该基准上的**性能表现和模型比较**。
---
### **5.1 避免污染问题(Avoiding Contamination)**
1. **LiveCodeBench 的时间窗口能力**
该基准通过时间窗口划分问题(从 2023 年 5 月至今),可以检测模型对**未见问题**的泛化能力,从而避免训练数据中的污染问题。
2. **DeepSeek 与 GPT-4-O 的污染问题**
- DeepSeek 模型的发布时间(2023 年 9 月)与 LiveCodeBench 的问题发布时间重叠,可能存在训练数据污染。
- GPT-4-O 的训练截止日期为 2023 年 11 月,在之后的问题上性能下降,进一步表明污染的存在。
3. **性能下降的实验观察**
- DeepSeek 模型在 2023 年 8 月之后的问题(即其发布前)表现较好,但在之后下降明显(如 DS-Ins-33B 的 Pass@1 从 ~60% 降至 ~0%)。
- GPT-4-O 在 2023 年 11 月之后的性能也有下降。
- 非 LeetCode 平台的问题(如 AtCoder)性能下降不明显,说明污染主要发生在 LeetCode 数据中。
4. **其他模型的表现**
- GPT-4-Turbo、Gemini-Pro、Mistral-L 和 Claude-3 等模型在时间窗口内没有明显性能波动,污染影响较小。
- DeepSeek 的基础模型(DS-Base-33B)也表现出类似污染问题,说明其预训练数据可能包含 LeetCode 竞赛题。
---
### **5.2 性能与模型比较(Performance and Model Comparisons)**
1. **模型评估与数据集选择**
- 评估了 34 个指令调优模型和 18 个基础模型。
- 为了防止污染,所有模型仅在 2023 年 9 月后的问题上进行评估。
2. **多场景的综合评估**
- LiveCodeBench 包括四种任务场景:代码生成(Code Generation)、自修复(Self-Repair)、测试输出预测(Test Output Prediction)和代码执行(Code Execution)。
- 模型在这些任务上的性能相对一致,相关性高于 0.88,尤其在相关任务(如生成与自修复、测试预测与执行)之间相关性更高(0.98 和 0.96)。
- 但不同任务之间仍存在性能差异,例如 GPT-4-Turbo 在自修复任务中表现优于 GPT-4,Claude-3-Opus 和 Mistral-L 在执行和测试预测任务中表现突出。
3. **与 HumanEval 的对比**
- HumanEval+ 是目前主流的代码生成评估基准,但 LiveCodeBench 的问题更具挑战性和多样性。
- 模型在两个基准上的性能差异明显,一些模型(如 DS-Ins-1.3B)在 HumanEval+ 上表现优异(Pass@1 为 60%),但在 LCB 上性能骤降至 26%,表明它们可能在 HumanEval 上过拟合。
- 基础模型和闭源模型在两个基准上的表现更一致,而一些开源模型因数据集单一导致泛化能力差。
4. **SOTA 与开源模型的差距**
- 在 LiveCodeBench 上,SOTA 模型(如 GPT-4-Turbo、Gemini-Pro-1.5、Claude-3-Opus)性能远高于开源模型。
- 例如,GPT-4-Turbo 在代码生成任务上比 DS-Ins-33B 高出 16.2 个百分点,在测试输出预测和代码执行任务中分别领先 96% 和 134%。
- GPT-4-Turbo 生成的代码更易读,使用更多自然语言注释进行推理,注释量是 GPT-4 的 19.5 倍。
5. **基础模型与指令调优模型的比较**
- 基础模型中,L3-Base 和 DeepSeek 表现最佳,优于 CodeLLaMa 和 StarCoder2。
- 指令调优可以显著提升模型性能,例如 L3-Ins-70B、DS-Ins-33B 和 Phind-34B 相比其基础模型提升了 7-9 个 Pass@1 百分点。
- 闭源模型的指令调优数据可能更具多样性,而开源模型在不同任务上表现差异较大。
6. **不同开源模型的比较**
- L3-Base 和 DeepSeek 指令调优模型表现最佳,其次是 Phind-34B 和 CodeLLaMa。
- 模型性能与规模相关,更大模型通常表现更好(如 Phind-34B 优于 6.7B 模型)。
7. **闭源与开源模型的对比**
- 闭源模型(如 GPT-4-Turbo、Claude-3-Opus)整体表现优于开源模型。
- 仅有 L3-Ins-70B、Mixtral 和 DS-Ins-33B 能够接近甚至超过闭源模型。
- 闭源模型在代码执行和测试输出预测任务上优势更明显,说明其在复杂推理任务上更强大。
---
### **总结**
LiveCodeBench 作为一个**污染少、覆盖全面**的代码评估基准,揭示了当前大型语言模型在代码生成、自修复、测试预测和代码执行等方面的真实能力。研究发现:
- **污染问题**在某些模型(如 DeepSeek 和 GPT-4-O)中明显存在,需通过时间窗口评估规避。
- **性能表现**与模型类型和数据分布密切相关,SOTA 闭源模型表现显著优于开源模型。
- **HumanEval 的过拟合问题**在多个开源模型中被验证,强调了 LiveCodeBench 的多样性和挑战性。
- **基础模型的性能提升**依赖于高质量的指令调优数据,而闭源模型的泛化能力更强。
该研究有助于推动更公平、更准确的模型评估,为未来代码生成模型的开发和优化提供方向。
## 6 Related Work
本章“相关工作”主要总结了代码生成、综合性任务(如代码修复、执行与测试生成)以及数据污染问题的研究进展,具体总结如下:
### 6.1 代码生成
该部分回顾了近年来大量基于大语言模型(LLM)的代码生成模型,如 Codex、CodeT5、CodeGen、SantaCoder、StarCoder、AlphaCode、InCoder 和 CodeGeeX 等。截至2024年5月,L3-Base、DeepSeek、StarCoder、CodeLLaMa 等是较为流行的开源模型。此外,通过合成数据对这些模型进行微调的下游模型也不断涌现,例如 WizardCoder、MagiCoders 和 Phind-34B。
为了评估这些模型的性能,研究者提出了多种代码生成的基准测试,主要包括自然语言到 Python 代码生成任务(如 HumanEval、APPS、MBPP、L2CEval 等)和针对 API 使用的生成任务(如 DS-1000、NumpyEval、PandasEval 等)。还有一些专门面向竞争性编程的基准(如 CodeContests、CodeScope、LeetCode-Hard 等),以及相关的改进方法(如 AlphaCode、ALGO、AlphaCodium 等)。
与现有基准相比,**LiveCodeBench** 的优势在于其**实时更新、难度平衡、高质量测试用例**,以及涵盖更多应用场景(如代码修复、执行与测试输出预测),更适合评估代理式编程系统(agentic coding systems)。
### 6.2 综合性任务
LiveCodeBench 除了代码生成,还引入了**代码修复、执行与测试生成**等场景,相关研究也进行了回顾:
- **代码修复**:已有研究(如 Chen 等, Olausson 等)通过错误反馈机制提升模型的自我修复能力,这些方法为 LiveCodeBench 的代码修复场景提供了启发。
- **代码执行**:早期研究(如 Austin 等, Nye 等)关注代码执行能力。CRUXEval 是一个衡量代码模型推理与执行能力的基准,而 LiveCodeBench 的执行任务更强调实时性,且使用更复杂、人工编写的函数,而非模型生成的代码。
- **测试生成**:已有工作(如 Yuan 等, Schäfer 等)探索了通过 LLM 生成测试用例,其中 Chen 等证明测试用例的生成可以提升代码质量。LiveCodeBench 的测试生成任务则通过解耦输入与输出,实现更精确的评估。
此外,相关研究还涉及代码类型预测、代码摘要生成、代码安全性分析等任务。
### 6.3 数据污染问题
随着 LLM 被训练在大量公开数据上,**数据污染**和**测试用例泄露**问题引起了广泛关注。研究表明,模型可能通过简单提示就能识别训练数据中的污染内容。一些检测方法(如基于编辑距离和 AST 语义相似度的方法)也被提出用于识别污染情况。例如,Riddell 等使用 AST 语义相似性来检测代码数据中的污染。
---
**总结**:本章系统回顾了代码生成领域的模型发展、基准测试和相关任务研究,并指出现有方法的局限性以及 LiveCodeBench 的创新点,特别是在实时性、多样性与任务综合性方面的优势。同时,也探讨了数据污染问题对模型评估带来的挑战及现有检测方法。
## 7 Limitations
本章节总结了 LiveCodeBench 的主要局限性及其应对策略,具体包括以下几个方面:
1. **基准规模有限**
- 当前基准包含 400 个代码生成任务实例,但为避免训练数据污染,仅使用 349 个在模型截止日期之后发布的问题进行评估。
- 由于样本大小有限,性能波动可能在 1% 至 1.5% 范围内,其他任务场景(如代码修复、执行与测试预测)也面临类似问题。
- 为减少此类影响,建议谨慎对待模型间的微小性能差异,并提出未来将引入更多竞赛平台问题和私有测试集,提升评估鲁棒性。
2. **仅支持 Python**
- 当前仅支持 Python 语言,限制了对多语言模型能力的评估。
- 由于已收集题目和测试用例,只要配备合适的评估引擎,扩展其他语言相对容易。
3. **提示词鲁棒性不足**
- 提示词设计对模型表现影响较大,但当前研究未做系统性优化,可能导致性能差异。
- 尤其在代码执行任务中,开源模型在使用思维链(COT)提示时表现不如封闭模型,说明提示优化仍有改进空间。
4. **问题领域局限**
- 当前基准主要基于竞赛编程问题,缺乏对实际软件开发等更广泛编程场景的覆盖。
- 建议将其作为模型评估的起点,并结合特定领域任务进行更全面的评估。
**总结**:LiveCodeBench 在数据规模、语言支持、提示策略和问题领域上存在局限,但已提出多个改进方案,例如引入更多问题源、扩展语言支持和优化提示策略,以提升评估的代表性与稳定性。
## 8 Conclusion
本章总结了文章的主要贡献和意义。作者提出了一个新的代码大模型评估基准 LiveCodeBench,通过引入实时评估机制来缓解现有基准中数据污染的问题,并扩展了评估场景,以更全面地反映大语言模型的代码能力。该基准具有可扩展性,将持续更新问题、场景和模型。评估结果揭示了一些新发现,例如数据污染现象和模型在 HumanEval 上的潜在过拟合问题。作者希望 LiveCodeBench 能够促进对当前代码大模型的理解,并为未来的研究提供指导。
## Appendix A Dataset
本附录详细介绍了LiveCodeBench数据集的构建方法、数据来源、生成器的使用以及代码执行的筛选标准。
### A.1 License(授权)
- 数据主要从LeetCode、AtCoder和CodeForces等编程竞赛平台抓取,仅限公开可见的内容,避免涉及付费墙或需要登录的内容。
- 引用了Hendrycks等人的Fair Use原则,强调数据使用的目的为学术研究,不涉及商业用途,并遵守版权法规。
- 所有抓取的数据仅用于学术研究,并未用于模型训练。
### A.2 Generator Based Test Generation(基于生成器的测试生成)
- 使用GPT-4-Turbo模型生成输入生成器,用于测试编程竞赛问题。
- 随机输入生成器和对抗输入生成器分别构建,以覆盖程序的常见输入和边界情况。
- 构建了2222个随机输入生成器和4个对抗输入生成器,最终采样输入数控制在 100 以内以提高评估效率。
- 对于CodeForces平台,由于只使用了 9 个问题,因此生成器采用了半自动方式构建。
- 提供了用于生成随机输入和对抗输入的提示模板(Prompt Examples),并展示了示例生成器代码。
### A.3 Code Execution(代码执行)
- LiveCodeBench代码执行部分包含来自85个不同问题的479个样本,每个问题最多选取6个样本以保证多样性。
- 对代码进行了严格的筛选标准,包括代码长度、语法正确性、运行时间、运算复杂性等。
- 禁用了浮点运算、复杂字符串和列表操作,并限制执行步骤在1000个Python字节码操作以内,以确保代码的可执行性和安全性。
- 给出了两个被筛选掉的代码示例,一个因包含乘法运算,另一个因控制流复杂。
- 提供了数据集的统计信息,包括代码长度和执行步骤的分布情况(图8)。
**总结**:
本附录详细说明了LiveCodeBench数据集的构建流程、授权依据、输入生成方法和代码筛选标准,确保了数据集的合法性、多样性和可执行性,为LLM的代码评估提供了一个高质量、无污染的基准。
## Appendix B UI
本附录介绍了LiveCodeBench的用户界面(UI),展示了两个视图:May-Jan和Sep-Jan。界面中受污染的模型被模糊显示,两个视图之间的性能差异一目了然。顶部的滚动条允许用户选择不同的时间段,突出显示了该基准测试的实时特性。
## Appendix C Experimental Setup
本节详细介绍了实验中使用的模型、代码生成、自修复、代码执行及测试输出预测的设置方法。
### **C.1 模型**
本节列出了实验中使用的语言模型的详细信息,包括模型 ID、简称、大致的截止日期和模型链接。模型涵盖了多个主流的代码生成模型和大语言模型,包括:
- **DeepSeek Coder 系列**(如 DSCoder-33b-Ins、DSCoder-6.7b-Ins 等)
- **CodeLlama 系列**(如 CodeLlama-70b-Ins、CodeLlama-34b-Ins 等)
- **LLaMA 系列**(如 LLama3-8b-Ins、LLama3-70b-Ins 等)
- **Anthropic 系列**(如 Claude-2、Claude-3 系列)
- **Google 系列**(如 CodeGemma、Gemini-Pro 等)
- **Meta 系列**(如 Mixtral-8x22b、Mixtral-8x7b 等)
- **Qwen、MagiCoder、StarCoder、OpenCodeInterpreter、Codestral、Command-R 等**
这些模型的截止日期从 2021 年到 2024 年不等,涵盖了多个不同版本和大小,以全面评估其性能。
---
### **C.2 代码生成**
本节提供了用于代码生成场景的提示格式。提示模板为用户生成符合要求的 Python 代码,包括两种情况:
- **有启动代码时**:提示中包含用户提供的启动代码。
- **无启动代码时**:提示中引导用户直接编写完整代码。
提示明确了用户要返回的是完整且正确的 Python 程序,不包含额外信息。
---
### **C.3 自修复(Self Repair)**
此部分描述了用于代码自修复的提示格式。当模型生成的代码出错时,系统会返回错误信息(如错误输出、运行时错误、超时等),并引导模型进行自修复。
提示要求模型:
1. **先简要说明错误原因(最多 2-3 句话)**。
2. **再提供修正后的完整代码**,并确保代码被正确包裹在代码块中。
---
### **C.4 代码执行**
本节提供了用于代码执行任务的提示内容,分为两种方式:
- **基础提示**:要求模型根据给定的 Python 函数和输入,生成对应的 assert 输出。
- **链式思考(CoT)提示**:要求模型先逐步执行代码,再生成最终的 assert 语句。
例如,给定 `def performOperation(s):` 和 `assert performOperation("hi") == ??`,模型需要计算执行结果并填写正确输出。
---
### **C.5 测试输出预测**
本节描述了用于测试输出预测的提示模板。用户会提供函数签名和输入,模型需计算输出并生成完整的 assert 语句。提示强调:
- 用户是高级 Python 编程助手。
- 需根据问题描述、函数定义和测试输入推导出正确的输出。
- 最终结果应完整地写入代码块中。
---
### **总结**
本章节详细说明了实验中使用的模型配置以及各项任务(代码生成、自修复、代码执行和测试输出预测)的提示格式,确保模型在统一的标准下进行测试,为后续实验的对比分析提供了明确的基础。
## Appendix D Results
### D.1 污染(Contamination)
本节展示了一些模型在代码生成和执行任务中出现的“污染”现象,尤其是 DeepSeek(DS)模型。通过图 10 和图 11,可见 DS 模型在自修复(self-repair)和代码执行(code execution)任务中,随着时间推移性能有所下降,这可能与模型训练数据中的污染有关。此外,图 12 显示了在 LeetCode 和 AtCoder 平台上,代码生成任务随时间的变化,其中 DS 模型的性能波动较大,而其他模型的性能相对稳定。图 13 展示了不同任务场景之间的相关性。
### D.2 所有结果(All Results)
- GPT-4O-2024-05-13 和 GPT-4 Turbo 在多个任务中表现最为突出。
- Gemini-Pro-1.5 系列和 Claude-3 系列也有较强的综合能力。
- DS 模型在某些任务中表现出性能波动,可能与数据污染相关。
- COT 模式显著提升了部分模型在代码执行任务中的表现。
这些结果反映了不同大语言模型在代码生成、自修复、测试输出预测和代码执行任务中的综合能力,同时也揭示了污染问题和模型更新对性能的影响。
## Appendix E Qualitative Examples
GPT-4在代码执行任务中,即便使用了Chain-of-Thought(CoT)提示方法,仍存在执行错误的5个示例。每个示例都包含任务描述、正确代码及其测试断言,以及GPT-4输出的错误结果,具体总结如下:
### **E.1 代码执行错误示例总结**
这些示例反映了GPT-4在代码任务中的一些局限性,尤其是在**逻辑判断、递归状态管理、数据结构操作**等方面。即便使用了推理链提示(CoT),GPT-4仍可能产生错误答案。这表明对于需要**精确逻辑推理或对算法理解较深**的编程问题,大型语言模型仍存在一定的执行误差。