数据湖¶
基本¶
数据湖。数据湖是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。
数据湖与数据仓库的区别:
数据湖:
1. 能处理所有类型的数据,如结构化数据,非结构化数据,半结构化数据等,数据的类型依赖于数据源系统的原始数据格式
2. 拥有足够强的计算能力用于处理和分析所有类型的数据,分析后的数据会被存储起来供用户使用。
3. 数据湖通常包含更多的相关的信息,这些信息有很高概率会被访问,并且能够为企业挖掘新的运营需求。
数据仓库:
1. 只能处理结构化数据进行处理,而且这些数据必须与数据仓库事先定义的模型吻合。
2. 处理结构化数据,将它们或者转化为多维数据,或者转换为报表,以满足后续的高级报表及数据分析需求。
3. 数据仓库通常用于存储和维护长期数据,因此数据可以按需访问。
关于数据湖的定义其实很多,但是基本上都围绕着以下几个特性展开:
1. 数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
2. 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
3. 数据湖中的数据是原始数据,是业务数据的完整副本。数据湖中的数据保持了他们在业务系统中原来的样子。
4. 数据湖需要具备完善的数据管理能力(完善的元数据),可管理各类数据相关的要素,
包括数据源、数据格式、连接信息、数据schema、权限管理等
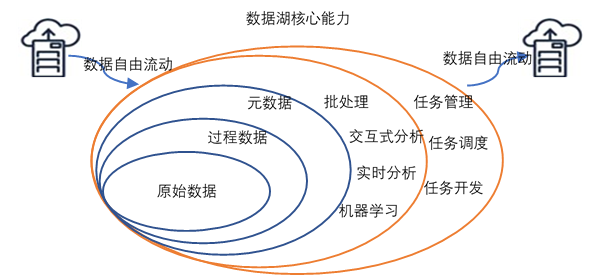
5. 数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;
同时,还需要提供一定的任务调度和管理能力。
6. 数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,
还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,
能帮助用户完整详细追溯任意一条数据的产生过程。
7. 数据湖需要具备完善的数据获取和数据发布能力。
数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;
然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
8. 对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力
数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。
特性 |
数据仓库 |
数据湖 |
|---|---|---|
数据 |
来自事务系统、运营db和业务线app的关系数据 |
来自IoT设备、网站、移动app的非关系和关系数据 |
Schema |
设计在数据仓库实施之前(写入型 Schema) |
写入在分析时(读取型 Schema) |
性价比 |
更快查询结果会带来较高存储成本 |
更快查询结果只需较低存储成本 |
数据质量 |
可作为重要事实依据的高度监管数据 |
任何可以或无法进行监管的数据(例如原始数据) |
用户 |
业务分析师 |
数据科学家、数据开发人员和业务分析师(使用监管数据) |
分析 |
批处理报告、BI和可视化 |
机器学习、预测分析、数据发现和分析 |
上表对比了数据湖与传统数仓的区别,个人觉得可以从数据和计算两个层面进一步分析数据湖应该具备哪些特征:
在数据方面:
1)“保真性”。数据湖中对于业务系统中的数据都会存储一份“一模一样”的完整拷贝。 与数据仓库不同的地方在于,数据湖中必须要保存一份原始数据,无论是数据格式、数据模式、数据内容都不应该被修改。 在这方面,数据湖强调的是对于业务数据“原汁原味”的保存。同时,数据湖应该能够存储任意类型/格式的数据。 2)“灵活性”: 上表一个点是 “写入型schema” v.s.“读取型schema” 其实本质上来讲是数据schema的设计发生在哪个阶段的问题。 对于任何数据应用来说,其实schema的设计都是必不可少的, 即使是mongoDB等一些强调“无模式”的数据库,其最佳实践里依然建议记录尽量采用相同/相似的结构。 “写入型schema”背后隐含的逻辑是数据在写入之前,就需要根据业务的访问方式确定数据的schema, 然后按照既定schema,完成数据导入,带来的好处是数据与业务的良好适配; 但是这也意味着数仓的前期拥有成本会比较高,特别是当业务模式不清晰、业务还处于探索阶段时,数仓的灵活性不够。 数据湖强调的“读取型schema”,背后的潜在逻辑则是认为业务的不确定性是常态: 我们无法预期业务的变化,那么我们就保持一定的灵活性,将设计去延后,让整个基础设施具备使数据“按需”贴合业务的能力。 因此,个人认为“保真性”和“灵活性”是一脉相承的: 既然没办法预估业务的变化,那么索性保持数据最为原始的状态,一旦需要时,可以根据需求对数据进行加工处理。 因此,数据湖更加适合创新型企业、业务高速变化发展的企业。 同时,数据湖的用户也相应的要求更高,数据科学家、业务分析师(配合一定的可视化工具)是数据湖的目标客户。 3)“可管理”:数据湖应该提供完善的数据管理能力。 既然数据要求“保真性”和“灵活性”,那么至少数据湖中会存在两类数据:原始数据和处理后的数据。 数据湖中的数据会不断的积累、演化。 因此,对于数据管理能力也会要求很高,至少应该包含以下数据管理能力:数据源、数据连接、数据格式、数据schema(库/表/列/行)。 同时,数据湖是单个企业/组织中统一的数据存放场所,因此,还需要具有一定的权限管理能力。 4)“可追溯”:数据湖是一个组织/企业中全量数据的存储场所,需要对数据的全生命周期进行管理, 包括数据的定义、接入、存储、处理、分析、应用的全过程。 一个强大的数据湖实现,需要能做到对其间的任意一条数据的接入、存储、处理、消费过程是可追溯的, 能够清楚的重现数据完整的产生过程和流动过程
在计算方面,个人认为数据湖对于计算能力要求其实非常广泛,完全取决于业务对于计算的要求:
5)丰富的计算引擎。
从批处理、流式计算、交互式分析到机器学习,各类计算引擎都属于数据湖应该囊括的范畴。
一般情况下,数据的加载、转换、处理会使用批处理计算引擎;
需要实时计算的部分,会使用流式计算引擎;对于一些探索式的分析场景,可能又需要引入交互式分析引擎。
随着大数据技术与人工智能技术的结合越来越紧密,各类机器学习/深度学习算法也被不断引入,
例如TensorFlow/PyTorch框架已经支持从HDFS/S3/OSS上读取样本数据进行训练。
因此,对于一个合格的数据湖项目而言,计算引擎的可扩展/可插拔,应该是一类基础能力。
6)多模态的存储引擎。
理论上,数据湖本身应该内置多模态的存储引擎,以满足不同的应用对于数据访问需求(综合考虑响应时间/并发/访问频次/成本等因素)
但是,在实际的使用过程中,数据湖中的数据通常并不会被高频次的访问,而且相关的应用也多在进行探索式的数据应用,
为了达到可接受的性价比,数据湖建设通常会选择相对便宜的存储引擎(如S3/OSS/HDFS/OBS),
并且在需要时与外置存储引擎协同工作,满足多样化的应用需求。
定义¶
Wikipedia¶
A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video). A data swamp is a deteriorated and unmanaged data lake that is either inaccessible to its intended users or is providing little value
数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机器学习。数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。数据沼泽是一种退化的、缺乏管理的数据湖,数据沼泽对于用户来说要么是不可访问的要么就是无法提供足够的价值。
AWS¶
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。