4.Kafka设计¶
4.1动机:
1.具有高吞吐量、支持高容量事件流,如:日志聚合
2.优雅处理大型数据积压,以支持离线系统的定期数据加载
3.低延时交付用于处理:更传统的消息传递用例
4.期望支持分区的、分布式的、实时处理以创建新的、派生feeds.此点促成我们的分区和消费模式
5.容错性,在机器出问题的情况下保证可用性
4.2持久化:
六个7200rpm SATA RAID-5阵列的JBOD配置的线性写入性能大约为600MB /秒
但随机写入的性能仅为大约100k /秒
顺序磁盘访问在某些情况下可能比随机内存访问更快
4.3效率:
% End-to-end Batch Compression
有时瓶颈不是cpu或磁盘,而是网络带宽,这时就需要压缩
特别适用于通过广域网跨数据中心发送消息
Kafka supports GZIP, Snappy, LZ4 and ZStandard compression protocols.
4.4 The Producer:
% 负载均衡
可以是随机load balance, 或semantic分区函数
% 异步发送
批处理是提升效率很重要的驱动
通过异步的方式,收集多条消息,通过一次请求发送
Kafka可以处理不超过固定数量的消息,不超过固定的延迟限制(如64k或10ms)
4.5 The Consumer:
% pull机制与push机制
kafka采用pull机制
% Consumer Position
% Offline Data Load
4.6 Message Delivery Semantics:
3种模式:都可以由consumer来实现
最多一次:先保存log position然后取数据处理
如果处理时crash,此消息会被当作已经处理
最少一次:先取数据处理,处理成功后保存log Position
如果处理时crash,会重新取数据处理
恰好一次:
可使用v0.11.0.0中的新事务生成器功能
4.7 Replication:
% Kafka节点,活跃度有两个条件:
1.节点必须能够使用ZooKeeper维护其会话(通过ZooKeeper的心跳机制)
2.如果它是一个slave,它必须复制发生在leader身上的写作,而不是落后“太远”
% leader会跟踪in sync来判断slave是否活着
如slave卡住、死掉或落后,leader会从同步副本中删除它
判断的标准由replica.lag.time.max.ms配置决定
4.8 Log Compaction:
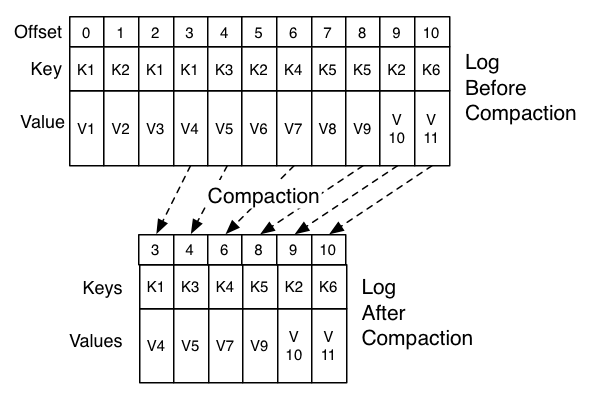
% 日志压缩由log cleaner处理
% log cleaner是一个后台线程池
% 用于重新复制日志段文件,删除其键出现在日志头部的记录
1.It chooses the log that has the highest ratio of log head to log tail
2.它为日志头部的每个键创建最后一个偏移量的简洁摘要
3.它从头重新记录log,移除日志中稍后会出现的keys
New, clean segments are swapped into the log immediately
因此,需要额外的磁盘空间is just one additional log segment (not a fully copy of the log).
4.log head摘要本质上是a space-compact hash table.
它每个条目都使用24 bytes per entry.
因此,使用8GB of cleaner buffer,一个cleaner iteration可以清理大约366GB of log head (assuming 1k messages).
% Configuring The Log Cleaner
log.cleanup.policy=compact
% 可在创建topic时或用alter topic完成
log.cleaner.min.compaction.lag.ms
% 防止比最小消息年龄更新的消息受到压缩
% 如未设定,则除正在写入字段都可以被压缩
4.9 Quotas:
1.网络带宽配额定义字节速率阈值(自0.9起)
2.请求速率配额将CPU利用率阈值定义为网络和I / O线程的百分比(自0.11起)