复杂度来源-规模¶
备注
规模带来复杂度的主要原因就是 “量变引起质变”,当数量超过一定的阈值后,复杂度会发生质的变化。
这样的系统特点:
功能特别多,逻辑分支特别多。
特别是有的系统,发展时间比较长,不断地往上面叠加功能,
后来的人由于不熟悉整个发展历史,可能连很多功能的应用场景都不清楚,
或者细节根本无法掌握,面对的就是一个黑盒系统,看不懂、改不动、不敢改、修不了,
复杂度自然就感觉很高了。
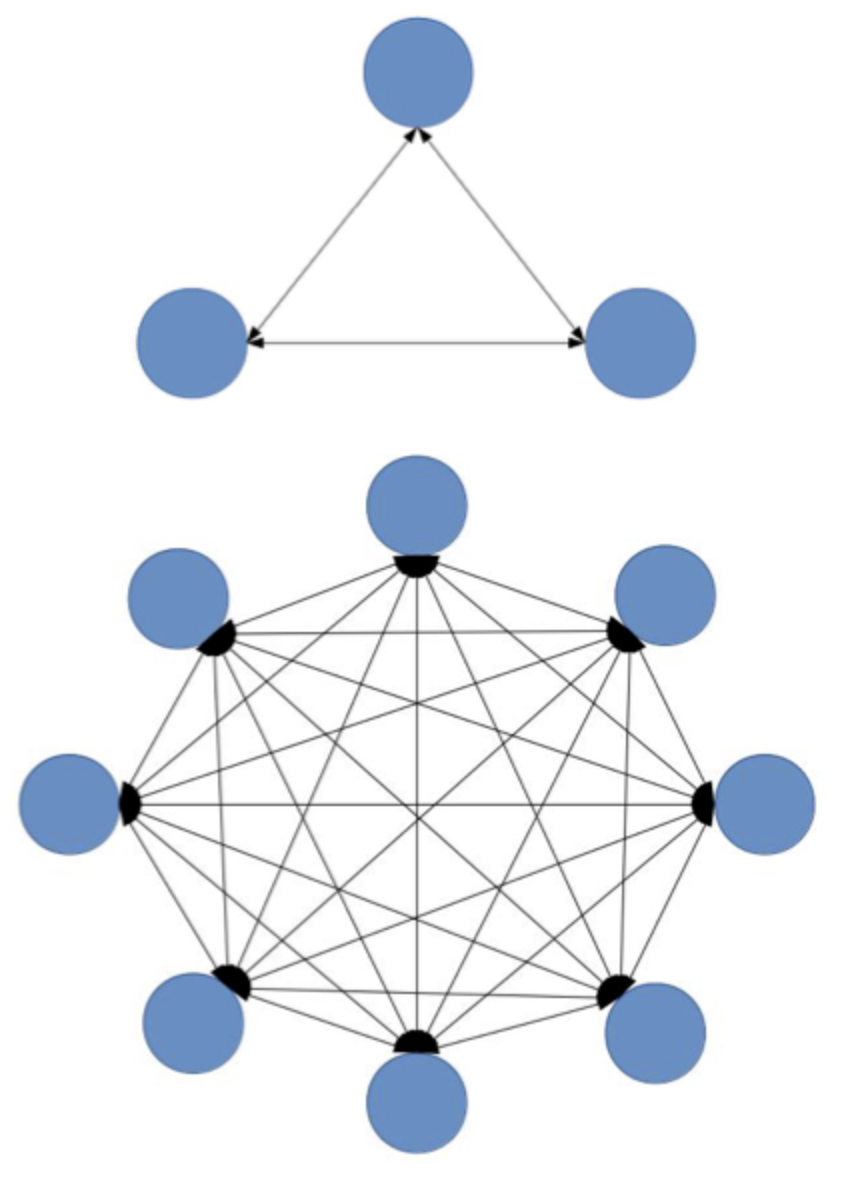
复杂度1-功能多¶
功能越来越多,导致系统复杂度指数级上升:
3 个功能的系统复杂度 = 3(系统) + 3(系统间关系)
8 个功能的系统复杂度 = 8(系统) + 28(系统间关系)
复杂度2-数据多¶
数据太多以后,传统的数据收集、加工、存储、分析的手段和工具已经无法适应,必须应用新的技术才能解决(如大数据)。
即使我们的数据没有达到大数据规模,数据的增长也可能给系统带来复杂性:
MySQL 单表的数据因不同的业务和应用场景会有不同的最优值,但肯定是有一定的限度的,一般推荐在 5000 万行左右。
如果因为业务的发展,单表数据达到了 10 亿行,就会产生很多问题,例如:
1. 添加索引会很慢,可能需要几个小时,这几个小时内数据库表是无法插入数据的,相当于业务停机了。
2. 修改表结构和添加索引存在类似的问题,耗时可能会很长。
3. 即使有索引,索引的性能也可能会很低,因为数据量太大。
4. 数据库备份耗时很长。
5. ……
当 MySQL 单表数据量太大时,我们必须考虑将单表拆分为多表,这个拆分过程也会引入更多复杂性:
1. 拆表的规则是什么?
以用户表为例:是按照用户 id 拆分表,还是按照用户注册时间拆表?
2. 拆完表后查询如何处理?
以用户表为例:假设按照用户 id 拆表,
当业务需要查询学历为 “本科” 以上的用户时,要去很多表查询才能得到最终结果,怎么保证性能?
其他¶
当规模随着业务的发展逐渐增大时复杂度逐渐增加。一旦规模超过一定的量级时复杂度就会出现指数级的上升,完全超出预计。因此要做到在规模上升的时候不断演进架构,不断重构代码,并起且做好运维监控,防微杜渐。